

今回は、BigGANデモを使って、OpenCVで色々と動画を作ってみます。
こんにちは cedro です。
先回のブログ、BigGANを使ってモーフィング動画を自動で作ってみるでOpenCVを使うと実に簡単に動画が作れることが分かりました。
あの静止画を一端作ってからGIF動画を作るプロセスは、一体なんだったのかと思えるほど簡単で、こうなって来ると、色々動画が作ってみたくなるわけです。
ということで、今回は、BigGANデモを使って、OpenCVで色々と動画を作ってみます。
コードを動かす準備をします
BigGAN TF Hub Demo に行き、Google account でログインします。





先回同様、[ 1 ] から [ 5 ] までのボタンを順にクリックして、コードを実行して下さい。


そして、ページ上部にある、赤丸の+コードをクリックします。


すると、コードを入力するセルが表示されます。ここに、後述のコードをコピペします。後は、ボタンを押せば、コードが実行されます。
モーフィング動画を多チャンネルで作る!
先回、ランダムに選んだ画像から画像への連続モーフィング動画を作ってみましたが、もっと迫力を出すために多チャンネルにしたい。今回は、2行×3列=6chで、3分間の動画を作ってみます。
例によってコードの説明は後にして、まず動かしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
#@title Interpolation { display-mode: "form", run: "auto" } import cv2 import random num_samples = 1 num_interps = 40 length = 45 #@param {type:"slider", min:15, max:150, step:1} truncation = 0.4 #@param {type:"slider", min:0.02, max:1, step:0.02} def interpolate_and_shape(A, B, num_interps): interps = interpolate(A, B, num_interps) return (interps.transpose(1, 0, *range(2, len(interps.shape))) .reshape(num_samples * num_interps, *interps.shape[2:])) fourcc = cv2.VideoWriter_fourcc('m','p','4','v') video = cv2.VideoWriter('BigGAN_video.mp4', fourcc, 10.0, (768, 512)) c1 = random.randint(0,999) n1 = random.randint(0,100) c2 = random.randint(0,999) n2 = random.randint(0,100) c3 = random.randint(0,999) n3 = random.randint(0,100) c4 = random.randint(0,999) n4 = random.randint(0,100) c5 = random.randint(0,999) n5 = random.randint(0,100) c6 = random.randint(0,999) n6 = random.randint(0,100) def mov(c,n): noise_seed_A = n category_A = c noise_seed_B = random.randint(0,100) category_B = random.randint(0,999) z_A, z_B = [truncated_z_sample(num_samples, truncation, noise_seed) for noise_seed in [noise_seed_A, noise_seed_B]] y_A, y_B = [one_hot(category * num_samples) for category in [category_A, category_B]] z_interp = interpolate_and_shape(z_A, z_B, num_interps) y_interp = interpolate_and_shape(y_A, y_B, num_interps) ims = sample(sess, z_interp, y_interp, truncation=truncation) return ims, category_B, noise_seed_B for i in range(length): print(i) ims1, c1, n1 = mov(c1, n1) ims2, c2, n2 = mov(c2, n2) ims3, c3, n3 = mov(c3, n3) ims4, c4, n4 = mov(c4, n4) ims5, c5, n5 = mov(c5, n5) ims6, c6, n6 = mov(c6, n6) for j in range(len(ims1)): im_v1 = cv2.vconcat([ims1[j],ims2[j]]) im_v2 = cv2.vconcat([ims3[j],ims4[j]]) im_v3 = cv2.vconcat([ims5[j],ims6[j]]) im_v4 = cv2.hconcat([im_v1,im_v2]) ims = cv2.hconcat([im_v3,im_v4]) img = ims[:, :, [2,1,0]] video.write(img) video.release() |
このコードをセルにコピペして、ボタンを押せばコードが実行され、ボタンがクルクル回り始めます。
動画作成の進捗状況をチェックするために、0から数字が順次カウントアップ表示されます。約20分くらいで、ボタンのクルクルが止まり、動画の完成です。

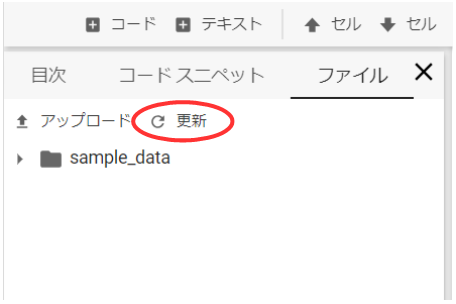
ボタンのクルクルが止まったら、左側の目次があるところで、ファイルのタブを選択し、赤丸の更新ボタンを押します。

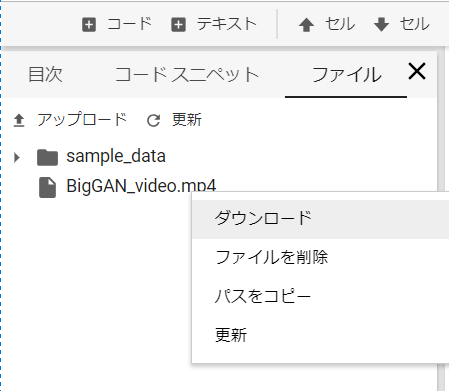
すると、BigGAN_video.mp4 というファイルが現れますので、右クリックでダウンロードを選択すればダウンロードを開始します。動画の内容が気に入らなければ、再度ボタンを押せば、別の動画が作成されます。

これは、作成した動画(108MB)をそのままYoutube にアップロードした例です。フルスクリーンで表示させれば、結構迫力があり見ごたえがあります。
コードの説明をします
ポイント部分のみ説明します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 初回のカテゴリーAの番号、ノイズシードAの番号(6チャンネル分) c1 = random.randint(0,999) n1 = random.randint(0,100) c2 = random.randint(0,999) n2 = random.randint(0,100) c3 = random.randint(0,999) n3 = random.randint(0,100) c4 = random.randint(0,999) n4 = random.randint(0,100) c5 = random.randint(0,999) n5 = random.randint(0,100) c6 = random.randint(0,999) n6 = random.randint(0,100) # 関数:カテゴリーAの番号、ノイズシードAの番号を引数で呼ぶと、画像間補完結果、カテゴリーBの番号、ノイズシードBの番号を返す def mov(c,n): noise_seed_A = n category_A = c noise_seed_B = random.randint(0,100) category_B = random.randint(0,999) z_A, z_B = [truncated_z_sample(num_samples, truncation, noise_seed) for noise_seed in [noise_seed_A, noise_seed_B]] y_A, y_B = [one_hot(category * num_samples) for category in [category_A, category_B]] z_interp = interpolate_and_shape(z_A, z_B, num_interps) y_interp = interpolate_and_shape(y_A, y_B, num_interps) ims = sample(sess, z_interp, y_interp, truncation=truncation) return ims, category_B, noise_seed_B |
3-14行目で画像間補完時の6ch分のカテゴリーAの番号とノイズシードAの番号をランダムに設定しています。これは、画像間補完の初回のみ使用します。
17行目から、関数 mov(c,n) を定義しています。引数c はカテゴリーAの番号、引数n はノイズシードAの番号です。戻り値は、画像間補完結果、カテゴリーBの番号、ノイズシードBの番号の3つです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# ims1〜6に画像間補完結果が入る。c1〜6にカテゴリーB、n1〜6にノイズBが返り、そのまま次の引数に使用される。 for i in range(length): print(i) ims1, c1, n1 = mov(c1, n1) ims2, c2, n2 = mov(c2, n2) ims3, c3, n3 = mov(c3, n3) ims4, c4, n4 = mov(c4, n4) ims5, c5, n5 = mov(c5, n5) ims6, c6, n6 = mov(c6, n6) # 画像の縦方向、横方向の連結 for j in range(len(ims1)): im_v1 = cv2.vconcat([ims1[j],ims2[j]]) im_v2 = cv2.vconcat([ims3[j],ims4[j]]) im_v3 = cv2.vconcat([ims5[j],ims6[j]]) im_v4 = cv2.hconcat([im_v1,im_v2]) ims = cv2.hconcat([im_v3,im_v4]) img = ims[:, :, [2,1,0]] # RBG を BGR に変換 video.write(img) video.release() |
3-10行目で各チャンネルの画像間保管結果を取得します。引数については、初回はカテゴリーAの番号とノイズシードAの番号は先ほどランダムに設定したものを使い、2回目以降はカテゴリーAの番号は前回のカテゴリーBの番号を使いノイズシードAの番号は前回のノイズシードBの番号を使います。こうすることで、各chとも常に連続した画像間補完が出来ます。
13-20行目で6chの画像間補完結果を連結してビデオに書き込んでいます。cv2.vconcat ( [ image1, image2 ] )で縦方向の連結、cv2.hconcat ( [ image1, image2 ] ) で横方向の連結が出来ます(image1, image2 はnumpy 配列)。
1000カテゴリーの画像を効率良く見れる動画を作る!
短時間で1000カテゴリーの画像を効率良く見れる動画を作ってみます。先ほどと同じく 2行×3列=6chで、1chをナンバー表示に使い、残り5chを画像にあて、13分ちょっとで1000カテゴリー全部見れるようにしてみます。
これも、コードの説明は後にして、まず動かしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
#PICフォルダーを作る import os if not os.path.isdir('pic'): os.mkdir('pic') # write number in black freme from PIL import Image, ImageDraw, ImageFont imageArray = np.zeros((256, 256, 3), np.uint8) cv2.imwrite("blank.bmp", imageArray); filename='/usr/share/fonts/truetype/liberation/LiberationSerif-Italic.ttf' font = ImageFont.truetype(filename, 40) for i in range(200): img = Image.open("blank.bmp") draw = ImageDraw.Draw(img) number = '# '+str(i*5)+' - '+str(i*5+4) name = str(i)+'.jpg' draw.text((10, 50), u'BigGAN', fill=(255, 255, 255), font=font) draw.text((10, 100), u'TF Hub Demo', fill=(255, 255, 255), font=font) draw.text((10, 150), number, fill=(255, 255, 255), font=font) img.save('pic/'+name) # メイン import cv2 import random import numpy as np num_samples = 1 num_interps = 40 length = 200 truncation = 0.4 def interpolate_and_shape(A, B, num_interps): interps = interpolate(A, B, num_interps) return (interps.transpose(1, 0, *range(2, len(interps.shape))) .reshape(num_samples * num_interps, *interps.shape[2:])) fourcc = cv2.VideoWriter_fourcc('m','p','4','v') video = cv2.VideoWriter('BigGAN_video.mp4', fourcc, 10.0, (768, 512)) def mov(c): noise_seed_A = random.randint(0,100) category_A = c noise_seed_B = random.randint(0,100) category_B = c z_A, z_B = [truncated_z_sample(num_samples, truncation, noise_seed) for noise_seed in [noise_seed_A, noise_seed_B]] y_A, y_B = [one_hot(category * num_samples) for category in [category_A, category_B]] z_interp = interpolate_and_shape(z_A, z_B, num_interps) y_interp = interpolate_and_shape(y_A, y_B, num_interps) ims = sample(sess, z_interp, y_interp, truncation=truncation) return ims for i in range(length): print(i) ims0 = np.array(Image.open('pic/'+str(i)+'.jpg')) ims1 = mov(i*5) ims2 = mov(i*5+1) ims3 = mov(i*5+2) ims4 = mov(i*5+3) ims5 = mov(i*5+4) for j in range(len(ims1)): im_v1 = cv2.vconcat([ims0,ims3[j]]) im_v2 = cv2.vconcat([ims1[j],ims4[j]]) im_v3 = cv2.vconcat([ims2[j],ims5[j]]) im_v4 = cv2.hconcat([im_v1,im_v2]) ims = cv2.hconcat([im_v4,im_v3]) img = ims[:, :, [2,1,0]] video.write(img) video.release() |
このコードをセルにコピペして、ボタンを押せばコードが実行され、ボタンがクルクル回り始めます。
動画作成の進捗状況をチェックするために、0から数字が順次カウントアップ表示されます。約76分くらいでボタンのクルクルが止まり、動画の完成です。
後は、先ほどと同じように、できた動画をダウンロードします。
これは、作成した動画(295MB)をそのままYoutube にアップロードした例です。左上にカテゴリー番号が表示されています。また、各カテゴリーの動画は、ランダムに選んだ2つのノイズシードを使って画像間補完しているので、微妙に連続的に変化して良い感じです。
コードの説明をします
ポイントのみ説明します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# pic フォルダーを作る import os if not os.path.isdir('pic'): # pic フォルダーがなかったら os.mkdir('pic') # pic フォルダーを作る # 黒画像(blank.bmp)を作る from PIL import Image, ImageDraw, ImageFont imageArray = np.zeros((256, 256, 3), np.uint8) cv2.imwrite("blank.bmp", imageArray); # フォントスタイル(LiberationSerif-Italic.ttf)の指定 filename='/usr/share/fonts/truetype/liberation/LiberationSerif-Italic.ttf' # フォントサイズ(40)の指定 font = ImageFont.truetype(filename, 40) # ナンバー画像(jpg)を作成し、pic フォルダーに保存する for i in range(200): img = Image.open("blank.bmp") # 真っ黒な画像を読み込む draw = ImageDraw.Draw(img) # draw インスタンスを作成 # ナンバー表示の仕様 ” # *** - *** " number = '# '+str(i*5)+' - '+str(i*5+4) # ファイル名指定 0.jpg 〜 199.jpg name = str(i)+'.jpg' # 真っ黒な画像に白色で文字を書き込む draw.text((10, 50), u'BigGAN', fill=(255, 255, 255), font=font) draw.text((10, 100), u'TF Hub Demo', fill=(255, 255, 255), font=font) draw.text((10, 150), number, fill=(255, 255, 255), font=font) # 作成したナンバー画像を 0.jpg 〜 199.jpg でpic フォルダーに書き込む img.save('pic/'+name) |
コード冒頭にある、カテゴリー番号を表示する、ナンバー画像を作成する部分です。1000枚を5枚づつ見るので、1000÷5=200枚の画像が必要です。一々手作業で作っていては大変なので、自動作成して pic フォルダーに格納します。
3-5行目で pic フォルダーを作成し、8-10行目で下地となる黒画像を作成します。13-15行目はフォントのスタイルとサイズの指定。18行目から黒画像に白色で文字で書き込みます。
28-30行目で文字を書き込む draw.text ()の引数は、draw.text ( (書き込む先頭のx,y座標), 書き込む文字列, fill = (文字色のR, G, B値指定), font = フォントファイルの指定)です。
このコードを実行すると、pic フォルダーの中に 200枚のナンバー画像が格納されます。
補足<フォントファイルが何処にあるか調べる方法>
|
1 2 3 4 |
import matplotlib.font_manager as fm fm.findSystemFonts() |
セルに、このコードを貼り付けて実行すれば、Google Colab にインストール済みのフォントファイルの一覧が表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 関数:カテゴリーAを引数で呼ぶと、画像間補完結果を返す def mov(c): noise_seed_A = random.randint(0,100) category_A = c noise_seed_B = random.randint(0,100) category_B = c z_A, z_B = [truncated_z_sample(num_samples, truncation, noise_seed) for noise_seed in [noise_seed_A, noise_seed_B]] y_A, y_B = [one_hot(category * num_samples) for category in [category_A, category_B]] z_interp = interpolate_and_shape(z_A, z_B, num_interps) y_interp = interpolate_and_shape(y_A, y_B, num_interps) ims = sample(sess, z_interp, y_interp, truncation=truncation) return ims # ナンバー画像とims1〜5を読み込む for i in range(length): print(i) # ナンバー画像の読み込み ims0 = np.array(Image.open('pic/'+str(i)+'.jpg')) # ims1〜5の読み込み ims1 = mov(i*5) ims2 = mov(i*5+1) ims3 = mov(i*5+2) ims4 = mov(i*5+3) ims5 = mov(i*5+4) |
関数定義の部分です。3-15行目で、引数はカテゴリーAの番号で、画像間補完結果を返す設定にしています。先程と比べればシンプルです。内部では、ノイズシードAの番号とノイズシードBの番号はランダムに選んで画像間補完する設定にしています。
18-27行目で、ナンバー画像と5枚の画像間補完結果を読み込みます。この後は、先程同様、これらを連結してビデオに書きむだけです。
いやー、それにしても、画像の連結とか文字入れが自動で出来ると、簡単に動画の表現力が上がって楽しいですねー。
では、また。