

今回は、変分オートエンコーダで漢字を2次元マップにマッピングしてみます。
こんにちは cedro です。
変分オートエンコーダが面白くてたまりません。画像を連続的に変化させながら2次元マップに分布させるのを見る度に、関心してしまいます。
変分オートエンコーダは、第1回はMNIST、第2回はオリジナルデータセット(モノクロ28×28の顔画像)、第3回はセレブの顔画像とやって来ました。
数字、顔画像、顔画像とやって来ましたので、今回は文字にトライしてみたいなと思って、色々データセットを探したところ、ちょうど良さそうな漢字のデータセットを見つけました。
ということで、今回は、変分オートエンコーダで漢字を2次元マップにマッピングしてみます。
NDL Lab 漢字データセット とは


今回、使うデータセットは、NDL Lab の文字画像データセット(漢字300文字版)です。
このデータセットは、国立国会図書館デジタルコレクションのインターネット公開資料から、頻出漢字300文字の画像を切り出したもので、合計146,157画像あります。


データ形式は、グレイスケール48×48のPNGです。各文字の収録画像数は、100画像から1,000画像まで文字によってバラツキがあります。
今回、どれ位の種類の漢字を2次元マップにマッピングさせようかと考えたのですが、10種類くらいじゃあ MNIST みたいで面白くない。なので、思い切って30種類の漢字をマッピングさせることにしました。

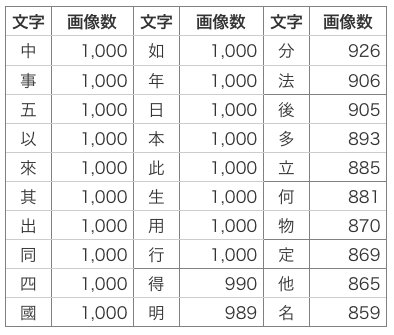
使用する漢字は、データ数を多い順に並べ、画数が4未満のものを省いて(あまり簡単だと面白くないので)、上位30個を選びました。データ数は、合計28,838個です。

moji フォルダーを作成し、その下に0〜29まで30種類のフォルダーを作成して、画像データをそのまま格納すればOKです。前処理は、一切不要です。
プログラムを改造します
今回は、畳み込み変分エンコーダーのサンプルプログラム(variational_autoencoder_deconv.py)を改造して使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from __future__ import absolute_import from __future__ import division from __future__ import print_function from keras.layers import Dense, Input from keras.layers import Conv2D, Flatten, Lambda from keras.layers import Reshape, Conv2DTranspose from keras.models import Model from keras.datasets import mnist from keras.losses import mse, binary_crossentropy from keras.utils import plot_model from keras import backend as K from sklearn.model_selection import train_test_split ### 追加 from PIL import Image ### 追加 import numpy as np import matplotlib.pyplot as plt import argparse import os import glob ### 追加 |
新たに必要なパッケージを追加でインポートします。train_test_split は1つのデータセットを学習用と評価用に任意に分割してくれるパッケージ、Image と glob は今回のデータセットの読み込みに使うパッケージです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
def plot_results(models, data, batch_size=128, model_name="vae_mnist"): """Plots labels and MNIST digits as function of 2-dim latent vector # Arguments: models (tuple): encoder and decoder models data (tuple): test data and label batch_size (int): prediction batch size model_name (string): which model is using this function """ encoder, decoder = models x_test, y_test = data os.makedirs(model_name, exist_ok=True) filename = os.path.join(model_name, "vae_mean.png") # display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(x_test, batch_size=batch_size) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y_test) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.savefig(filename) plt.close() ### clear #plt.show() ### 表示させない filename = os.path.join(model_name, "digits_over_latent.png") # display a 30x30 2D manifold of digits n = 30 digit_size = 48 ### 28 → 48 に変更 figure = np.zeros((digit_size * n, digit_size * n)) # linearly spaced coordinates corresponding to the 2D plot # of digit classes in the latent space grid_x = np.linspace(-4, 4, n) grid_y = np.linspace(-4, 4, n)[::-1] for i, yi in enumerate(grid_y): for j, xi in enumerate(grid_x): z_sample = np.array([[xi, yi]]) x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size) plt.imshow(digit,cmap='Greys_r') ### 追加 plt.savefig(str(i)+'@'+str(j)+'fig.png') ### 追加 figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) start_range = digit_size // 2 end_range = n * digit_size + start_range + 1 pixel_range = np.arange(start_range, end_range, digit_size) sample_range_x = np.round(grid_x, 1) sample_range_y = np.round(grid_y, 1) plt.xticks(pixel_range, sample_range_x) plt.yticks(pixel_range, sample_range_y) plt.xlabel("z[0]") plt.ylabel("z[1]") plt.imshow(figure, cmap='Greys_r') plt.savefig(filename) #plt.show() ### 表示させない |
学習完了後、2次元マップにドットと画像でマッピングする部分です。
28行目の plt.close() で、ドットの2次元マップをセーブした後に、matplotlib をクリアしています。理由は良く分かりませんが、ここでクリアしておかないと、この後2次元マップに多量に生成する画像にシミのようなものが付いてしまうので。
29行目と63行目の plt.show() を無効にしているのは、一端表示させると、表示中止ボタンを押すまでプログラム動作が中断して使い勝手が悪いので。
46−47行目は、2次元マップに生成する画像を1枚づつ保存する部分で、0@0fig.png 〜 29@29fig.png まで 900枚(30×30=900)を保存する設定にしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# MNIST dataset #(x_train, y_train), (x_test, y_test) = mnist.load_data() #image_size = x_train.shape[1] #x_train = np.reshape(x_train, [-1, image_size, image_size, 1]) #x_test = np.reshape(x_test, [-1, image_size, image_size, 1]) #x_train = x_train.astype('float32') / 255 #x_test = x_test.astype('float32') / 255 ### kanji dataset folder = ["0","1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29"] image_size = 48 x = [] y = [] for index, name in enumerate(folder): dir = "./moji/" + name files = glob.glob(dir + "/*.png") ### フォルダー内の画像名を全て取得 for i, file in enumerate(files): ### 1つづつ画像を処理する image = Image.open(file) ### 画像を開く image = image.convert("L") ### グレイスケールで読み込み(カラーで読み込む場合は、"RGB" とする) image = image.resize((image_size, image_size)) ### 48×48にリサイズ data = np.asarray(image) ### 配列に格納 x.append(data) ### 画像配列を格納 y.append(index) ### フォルダー名を格納 x = np.array(x) ### numpy配列の形式に変更 y = np.array(y) ### numpy配列の形式に変更 x = x.astype('float32') x = x/ 255.0 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) x_train = np.reshape(x_train, [-1, image_size, image_size, 1]) ### 4次元配列にリシェイプ x_test = np.reshape(x_test, [-1, image_size, image_size, 1]) ### 4次元配列にリシェイプ original_dim = 2304 ### 48×48=2304 image_size = 48 |
データセット読み込み部分です。まず、MNIST 用の部分は無効にします(削除でもOK)。
今回は、画像データが30種類もあるので、前回や前々回の読み込み方だと、やたらプログラムの行数が増えスマートでないので、別の方法を試してみます。
まず、folder = [“0”, “1”, “2”, ・・・”29″] でフォルダー名を設定します。そして、 files = glob.glob(dir + “/*.png”) で、フォルダー内の画像名を全て取得します。その後、for i, file in enumerate(files): で画像を1つづつ、読み込んで行きます。
読み込んだ後は、必要な処理をし、train_test_split で学習データと評価データを8:2に分割しています。これ便利で良いですよね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# network parameters input_shape = (image_size,image_size,1) batch_size = 128 kernel_size = 3 filters = 32 ### 16 → 32 に変更 latent_dim = 2 epochs = 50 # VAE model = encoder + decoder # build encoder model inputs = Input(shape=input_shape, name='encoder_input') x = inputs for i in range(3): ### 2 → 3 に変更 filters *= 2 x = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu', strides=2, padding='same')(x) # shape info needed to build decoder model shape = K.int_shape(x) # generate latent vector Q(z|X) x = Flatten()(x) x = Dense(16, activation='relu')(x) z_mean = Dense(latent_dim, name='z_mean')(x) z_log_var = Dense(latent_dim, name='z_log_var')(x) # use reparameterization trick to push the sampling out as input # note that "output_shape" isn't necessary with the TensorFlow backend z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var]) # instantiate encoder model encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder') encoder.summary() plot_model(encoder, to_file='vae_cnn_encoder.png', show_shapes=True) # build decoder model latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) for i in range(3): ### 2 → 3 に変更 x = Conv2DTranspose(filters=filters, kernel_size=kernel_size, activation='relu', strides=2, padding='same')(x) filters //= 2 outputs = Conv2DTranspose(filters=1, kernel_size=kernel_size, activation='sigmoid', padding='same', name='decoder_output')(x) |
ネットワーク構築部分です。先回同様、2箇所ある for i in range (2) → for i in range (3) に変更することで、エンコーダとデコーダの畳み込みレイヤーを2段から3段にパワーアップさせ、これに伴い filters は 16 → 32 に変更しています。

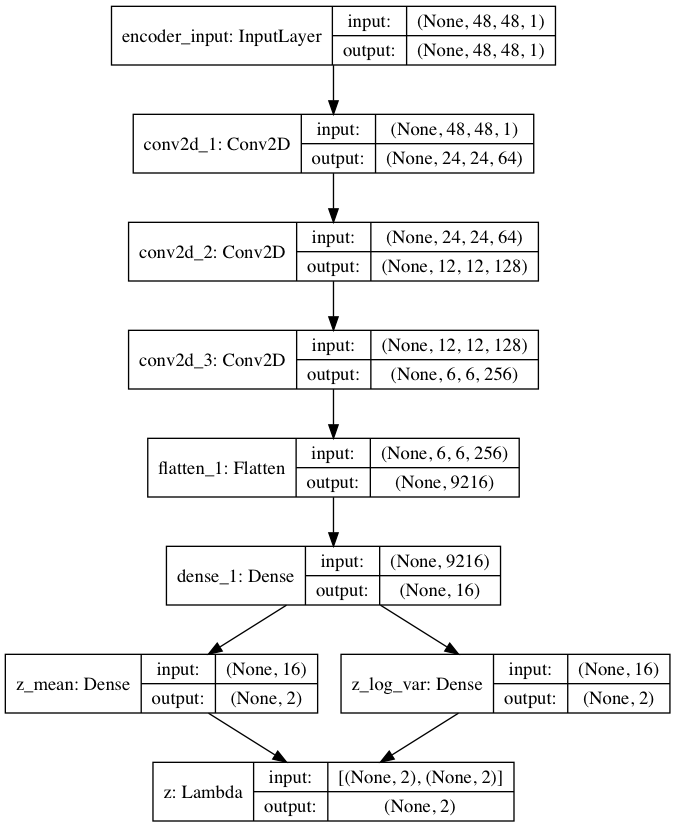
エンコーダの構成図はこんな形(プログラムが出力する vae_cnn_encoder.pngです)。畳み込みの部分は、モノクロ48×48の入力を24×24フィルター64枚で受けてから、6×6フィルター256枚まで次元圧縮(1/4)しています。

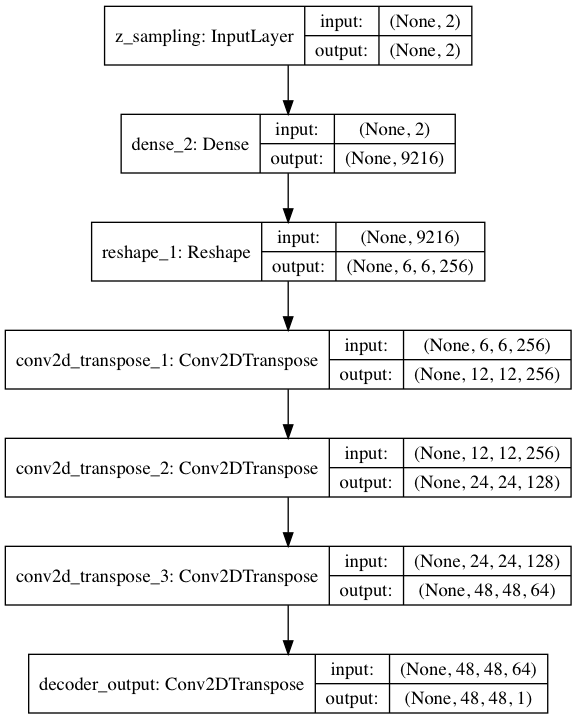
デコーダの構成図はこんな形(プログラムが出力する vae_cnn_decorder.pngです)。畳み込み部分は、エンコーダの逆です。
プログラムを動かしてみます
|
1 2 3 |
pyhon variational_autoencoder_deconv.py |

2次元マップにドットでマッピングした結果です。Color bar を使ってデータを色分けしていますが、30種類もあると、色の変化が微妙で識別は難しいですね(笑)。



2次元マップに画像をマッピングした結果です。さすがに30種類の漢字は伊達じゃないですね。変分オートエンコーダも結構大変なようで、ところどころ不連続なところがあります。

2次元マップの画像が比較的上手く分布している、赤枠線の部分に該当する画像を、保存した画像の中から拾って、GIF動画にしてみます。

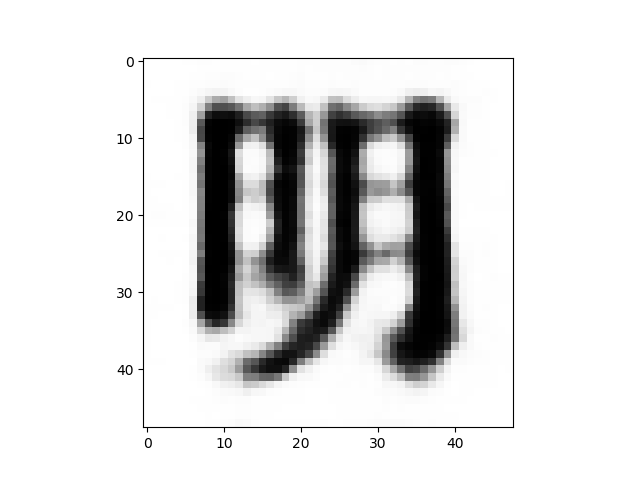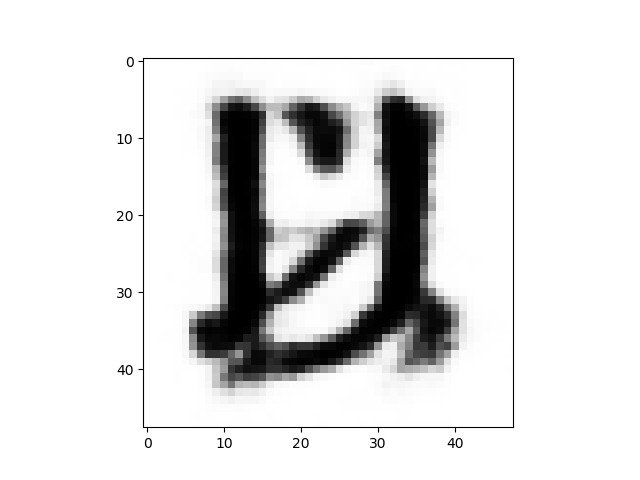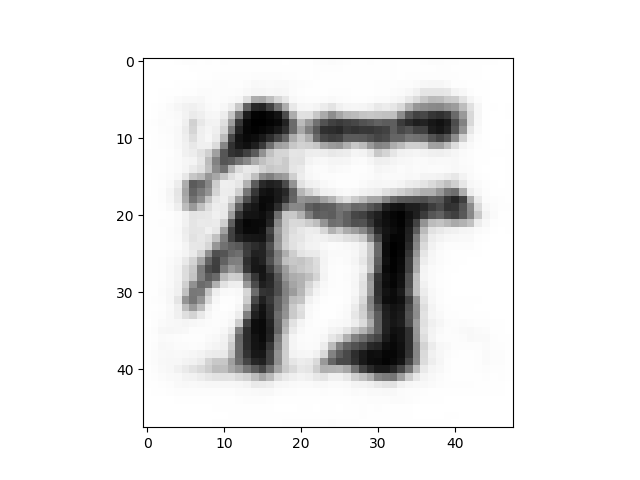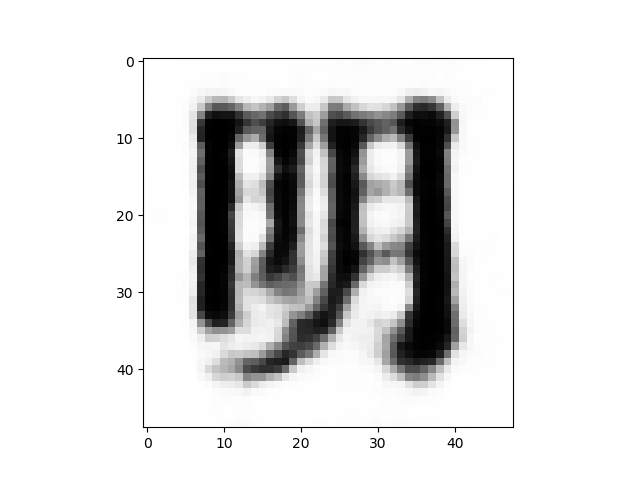
まるで生き物のように漢字が連続的に変形して行きます。いわゆる漢字のモーフィングも、結構面白いものですね。
では、また。