

今回は、KMNIST日本語くずし文字データセットを使って、「くずし文字」を書く練習をするための練習器を作ってみます。
皆さん、あけましておめでとうございます。今年もよろしくお願い致します。
お正月をどうお過ごしですか、cedro です。
過日、人文学オープンデータ共同利用センターが発表した、KMNISTという日本語くずし文字データセットを使って、KerasのVAEで遊んでみました。
その後、思ったのは、日本人であれば、日本語のくずし文字が読めるだけではなく、くずし文字を書くことも教養として必要ではないかということです。
であれは、そのための練習器があっても良いのではないかと考えたわけです(笑)。
ということで、今回は、KMNIST日本語くずし文字データセットを使って、「くずし文字」を書く練習をするための練習器を作ってみます。
くずし文字をCNNに学習させます


これが、KMNISTくずし文字データセットです。ひらがなのうち「お、き、す、つ、な、は、ま、や、れ、を」10文字を採用しています。データセットの仕様は、MNIST互換です。
早速ダウンロードしてみましょう。GithubからフォルダーをCloneするかDownloadZIPします。フォルダーの中のdownload_data.py を動かすとデータセットを簡単にダウンロード出来ます。

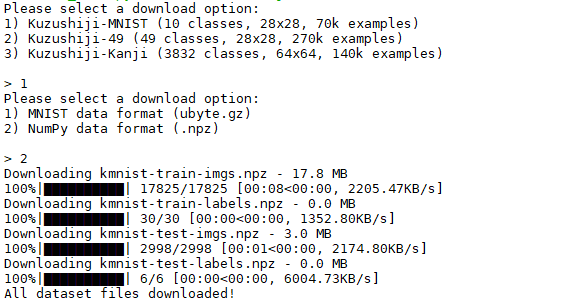
download_data.py を動かした時の画面です。こんな風に、数字を選択するだけで好みのデータセットをダウンロードできます。
1) Kuzushuji-MNIST を 2)NumPy data format (.npz) でダウンロードし k フォルダーを作って保管します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
from __future__ import print_function import keras import numpy as np from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 12 # load dataset x_train = np.load('k/kmnist-train-imgs.npz')['arr_0'] x_test = np.load('k/kmnist-test-imgs.npz')['arr_0'] y_train = np.load('k/kmnist-train-labels.npz')['arr_0'] y_test = np.load('k/kmnist-test-labels.npz')['arr_0'] # change data shape x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) input_shape = (28, 28, 1) # change data value x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # convert class vectors to binary class matrices y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax')) model.summary() model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) # save model and weights open('k_mnist_cnn_model.json','w').write(model.to_json()) model.save_weights('k_mnist_cnn_weights.h5') |
CNNでKMNISTを学習するコードです。基本的には、keras_example にある mnist_cnn.py です。
追加したのは以下2つ。# load dataset は kフォルダー内のKMNISTデータセットを読み込む部分、最後にある # save model and weights は学習したモデルと重みファイルを保存する部分です。

k_mnist_cnn.py(先程、修正追加したコード) と kフォルダー(KMNISTデータが入っている) を、適当なフォルダーに保存し、実行します。


畳み込みが2段+全結合2段のシンプルなCNNです。私のMacbookAir では 12epoch を 32分くらいで完了し、Test accuracy は97.42%でした。これで、学習モデル(k_mnist_cnn_model.json)と重みファイル(k_mnist_cnn_weights.h5)が mnist_cnn.py と同じフォルダーに保存されました。
練習器を作成します
くずし文字の入力と判定結果の表示にはブラウザを使うので、bottle ライブラリーを pip install bottle で事前にインストールします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
from bottle import get, post, request, run, template, response from keras.models import model_from_json from keras.optimizers import RMSprop import numpy as np from PIL import Image from io import BytesIO from binascii import a2b_base64 # index.html を表示する処理 @get('/') def index(): return template(open('./index.html').read()) # 画像の判定処理 @post('/img') def image(): img_str = request.params['img'] if img_str == False: return "{}" # 画像を28x28、グレースケールに変換 b64_str = img_str.split(',')[1] img = Image.open(BytesIO(a2b_base64(b64_str))) img = img.resize((28, 28)) img = img.convert('L') # load model and weights model =model_from_json(open('k_mnist_cnn_model.json').read()) model.load_weights('k_mnist_cnn_weights.h5') # model compile model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) # 画像をデータに変換 x = np.array(img) * (1.0 / 255.0) x = x[None, ...] x = x.reshape(1, 28, 28, 1) # number を予測 pred = model.predict(x, batch_size=1, verbose=1) print('pred_label = ', np.argmax(pred)) number = np.argmax(pred) # HTMLに返す list = ['お','き','す','つ','な','は','ま','や','れ','を'] return( {"result":list[number]}) run(host='localhost', port=8080) |
ブラウザを通じて手書き文字を読み込み、判定結果をブラウザに返すコードです。
まず、index.html を表示させて、手書き文字画像を読み込み、28×28のグレースケールに変換します。その後、学習モデルと重みファイルを読み込んで、モデルをコンパイルします。
画像をデータに変換して、「お、き、す、つ、な、は、ま、や、れ、を」のうちどれに一番近いのかmodel.predict でCNNに判定させます。
判定結果は「0〜9」の数字なので、リストから文字を選んでブラウザに返します。このコードを k_mnist_app.py で先程のフォルダーに保管します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 |
<html> <head> <meta charset="utf-8"> </head> <body> <h1>KMNIST Write Training</h1> <div>please write character (お,き,す,つ,な,は,ま,や,れ,を)</div> <p> <canvas id="canvas" width="400" height="400" style="border: 1px solid #999;"> </canvas> </p> <input id="clear" type="button" value="delete" onclick="clearCanvas();"> <input id="submit" type="button" value="predict character" onclick="judgeImg();"><br><br> <span id="answer"></span> <script> // キャンバスオブジェクト const canvas = document.getElementById('canvas'); const ctx = canvas.getContext('2d'); // Canvasの座標 const cleft = canvas.getBoundingClientRect().left; const ctop = canvas.getBoundingClientRect().top; // マウスのX/Y座標 let mouseX = mouseY = null; // キャンバスの内容をリセット clearCanvas(); // イベントの設定 canvas.addEventListener('mousemove', mmove, false); canvas.addEventListener('mousedown', mdown, false); canvas.addEventListener('mouseup', mouseInit, false); canvas.addEventListener('mouseout', mouseInit, false); // マウスを動かしている時のイベント function mmove(e){ if (e.buttons == 1 || e.witch == 1) { draw(e.clientX - cleft, e.clientY - ctop); }; } // マウスが押されている時のイベント function mdown(e){ draw(e.clientX - cleft, e.clientY - ctop); } // 描画処理 function draw(x, y){ ctx.beginPath(); if (mouseX === null) { ctx.moveTo(x, y); } else { ctx.moveTo(mouseX, mouseY); } ctx.lineTo(x, y); ctx.lineCap = "round"; // 線の太さは18、色は白 ctx.lineWidth = 18; ctx.strokeStyle = '#fff'; // 少し周りをぼかす ctx.shadowBlur = 15; ctx.shadowColor = '#fff'; ctx.stroke(); mouseX = x; mouseY = y; } // X/Yを初期化する処理 function mouseInit(){ mouseX = mouseY = null; } // Canvasの内容を消す処理 function clearCanvas(){ ctx.clearRect(0, 0, canvas.width, canvas.height); ctx.fillStyle = '#000'; ctx.fillRect(0, 0, canvas.width, canvas.height); document.querySelector('#answer').innerHTML = ''; } // 画像をサーバに送信 function judgeImg(){ // Canvasの内容をPNG画像として取り出す const img = document.querySelector('#canvas').toDataURL('image/png'); // 画像をフォームデータとして設定 const f = new FormData(); f.append('img', img); // サーバに送信 fetch('/img', { method: 'POST', body: f }) .then(res => { // 結果をJSONとして取り出す return res.json(); }) .then(json => { // 予測した文字を表示 document.querySelector("#answer").innerText = json.result + '、です'; }) } </script> </body> </html> |
手書き文字を画像読み取って、判定結果を表示するHTMLコードです。以下に、表示画面を元にコードの動きを説明します。


index.html の起動画面です。黒字のキャンバスは文字を書き込むためのもので、キャンバスのエリアでマウスが押されたら、マウスの動きを読み取って白い線で描画します。
「Delete」ボタンでキャンバスをクリア、「predict character」ボタンで描画した画像をサーバーへ送信し、サーバーから返って来た判定結果をボタンの下に表示します。index.html という名前で先程のフォルダーに保管します。

さて、フォルダーの中は、こんな感じになったと思います。では、動かしてみましょう。
「くずし文字」練習器を動かしてみる


python k_mnist_app.py でコードを実行すると、こんな表示が出ます。そうしたら、ブラウザで http://localhost:8080/ に接続すると練習器が動きます。


くずし文字には、色々なバリエーションがあるわけですが、今回は上記の例を練習してみます。


まず、「お」のくずし文字を書いてみました。判定が「お、です」と返って来ていますので、合格です。


次に、「き」のくずし文字を書いています。これは2回目で判定が「き、です」と返って来て、合格!


これは、「す」のくずし文字です。「す」は結構難しくて、「つ」と良く間違えられてしまいます。4回目でやっと合格が貰えました。


これは、「な」のくずし文字です。これは一発合格でした!
いやー、面白いです。もし、日本語のくずし文字を書くことを習得したいというニーズがあるなら、ディープラーニングで結構実用的なものが作れそうな気がします。
人間は学習する時に、正解率が70%くらいだと一番やる気になると言われているので、習熟度に応じて、最初は簡単なものから、徐々に難しいくずし文字にトライさせると、ボケ防止にもなって良いかも。
習得後は、古文書がスラスラ読める様になったりしたら、嬉しいですよね。
なお、今回の練習器のコード作成に当たっては、12/27 にgoofmint さんが行ったセミナーの内容を参考にさせて頂きました。感謝です!
では、また。