

1.はじめに
ちょっと前まで、顔・手・ポーズのリアルタイム検出をしようと思ったら高性能なGPUを積んだPCが必要でしたが、今回はこれらをCPUだけでも行える MediaPipe をご紹介します。
2.MediaPipeとは?
MediaPipieは、Googleが提供しているライブメディアやストリーミングメディア向けのMLソリューションで、以下の特徴があります。
- 高速なエンドツーエンド処理:一般的なハードウェアでも高速化されたML推論と処理を実現
- 様々なプラットフォームで使用可能:Android、iOS、C++、Pythonに対応
- 無料のオープンソース: Apache 2.0で、拡張やカスタマイズが可能
現在、4つのプラットフォームで、15種類のソリューションを提供されています。今回はその中から、Pythonプラットフォームの、顔検出、手検出、ポーズ検出、ホリスティック検出(顔・手・ポーズの統合検出)についてご紹介します。
3.コード(動画から検出)
最初のデモはオジサンより、女優やダンサーの方が見ていて楽しいと思うので、あえて動画からホリスティック検出(顔・手・ポーズの統合検出)をやってみます。
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。なお、GPUは使っていません。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#@title **set up** # install mediapipe !pip install mediapipe # clone github code !git clone https://github.com/cedro3/mediapipe.git %cd mediapipe/ # initial setting import mediapipe as mp mp_holistic = mp.solutions.holistic # Initialize MediaPipe Holistic. holistic = mp_holistic.Holistic( static_image_mode=True, min_detection_confidence=0.5) # Prepare DrawingSpec for drawing the face landmarks later. WHITE_COLOR = (224, 224, 224) BLACK_COLOR = (0, 0, 0) RED_COLOR = (0, 0, 255) GREEN_COLOR = (0, 128, 0) BLUE_COLOR = (255, 0, 0) mp_drawing = mp.solutions.drawing_utils drawing_face_spec = mp_drawing.DrawingSpec(color=WHITE_COLOR, thickness=1, circle_radius=1) drawing_pose_spec = mp_drawing.DrawingSpec(color=WHITE_COLOR, thickness=3, circle_radius=3) drawing_hand_spec = mp_drawing.DrawingSpec(color=WHITE_COLOR, thickness=3, circle_radius=3) drawing_dot_spec = mp_drawing.DrawingSpec(color=RED_COLOR, thickness=2, circle_radius=3) # define fuction from function import * |
次に、video で指定した動画を読み込み静止画に分解し、framesフォルダ に保管します。既に frames フォルダがある場合(2回目以降)は、既にあるフォルダを一旦削除してから処理を開始します。ここでは、video = satomi.mp4 を指定しています。
ご自分の動画を使いたい場合は、その動画をPCから videoフォルダにドラッグ&ドロップでアップロードして下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#@title **video-to-frames** #@markdown upload video(mp4) with sound to movie/video folder video = 'satomi.mp4' #@param {type:"string"} video_file = 'video/'+video image_dir='frames/' image_file='%s.jpg' # video_2_images reset_folder('frames') fps, i, interval = video_2_images(video_file, image_dir, image_file) # display strat frame from google.colab.patches import cv2_imshow img = cv2.imread('frames/000000.jpg') cv2_imshow(img) # display parameter print('fps = ', fps) print('frames = ', i) print('interval = ', interval) |


frames = 106
interval = 1
読み込んだ動画の最初のフレームのみを表示しています。
そして、MediaPipeを使って、frames フォルダの中にある静止画から顔・手・ポーズを検出し、結果を images フォルダに保管して行きます。既に images フォルダがある場合(2回目以降)は、既にあるフォルダを一旦削除してから処理を開始します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
#@title **MediaPipe from frames to images** import cv2 from google.colab.patches import cv2_imshow import numpy as np import glob from tqdm import tqdm ### # reset images folder reset_folder('images') # image file names to files in list format files=[] for name in sorted(glob.glob('./frames/*.jpg')): files.append(name) # Read images with OpenCV. images = {name: cv2.imread(name) for name in files} #for name, image in images.items(): for name, image in tqdm(images.items()): # Convert the BGR image to RGB and process it with MediaPipe Pose. results = holistic.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # Draw pose landmarks. annotated_image = image.copy() mp_drawing.draw_landmarks( image=annotated_image, landmark_list=results.left_hand_landmarks, connections=mp_holistic.HAND_CONNECTIONS, landmark_drawing_spec=drawing_dot_spec, connection_drawing_spec=drawing_hand_spec) mp_drawing.draw_landmarks( image=annotated_image, landmark_list=results.right_hand_landmarks, connections=mp_holistic.HAND_CONNECTIONS, landmark_drawing_spec=drawing_dot_spec, connection_drawing_spec=drawing_hand_spec) mp_drawing.draw_landmarks( image=annotated_image, landmark_list=results.face_landmarks, connections=mp_holistic.FACEMESH_TESSELATION, ### landmark_drawing_spec=drawing_face_spec, connection_drawing_spec=drawing_face_spec) mp_drawing.draw_landmarks( image=annotated_image, landmark_list=results.pose_landmarks, connections=mp_holistic.POSE_CONNECTIONS, landmark_drawing_spec=drawing_pose_spec, connection_drawing_spec=drawing_pose_spec) save_name = 'images/'+os.path.basename(name) ### cv2.imwrite(save_name, annotated_image) |
最後に、images フォルダの中にある検出結果を読み込んでmp4動画を作成します。このとき、with_sound のチェックボックスにチェックを入れておくと、元動画の音声を検出動画に付加します。元動画に音声が付いていない場合にチェックを入れるとエラーになりますので、ご注意下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#@title **make movie from images** #@markdown check with_sound if the video has sound with_sound = False #@param {type:"boolean"} fps_r = fps/interval print('making movie...') if with_sound == True: ! ffmpeg -y -r $fps_r -i images/%6d.jpg -vcodec libx264 -pix_fmt yuv420p -loglevel error out.mp4 # audio extraction/addition print('preparation for sound...') ! ffmpeg -y -i $video_file -loglevel error sound.mp3 ! ffmpeg -y -i out.mp4 -i sound.mp3 -loglevel error output.mp4 else: ! ffmpeg -y -r $fps_r -i images/%6d.jpg -vcodec libx264 -pix_fmt yuv420p -loglevel error output.mp4 display_mp4('output.mp4') |

顔と手は、かなり細かい検出がされていることが分かります。写っている範囲が狭いので、ポーズは肩の線のみ見えています。作成したmp4動画は、下記を実行するとダウンロードできます。
|
1 2 3 |
#@title **download movie** (chrome) from google.colab import files files.download('output.mp4') |
ビデオ指定のところを、video = mana.mp4 に変更して、それ以降のコードを実行すると、

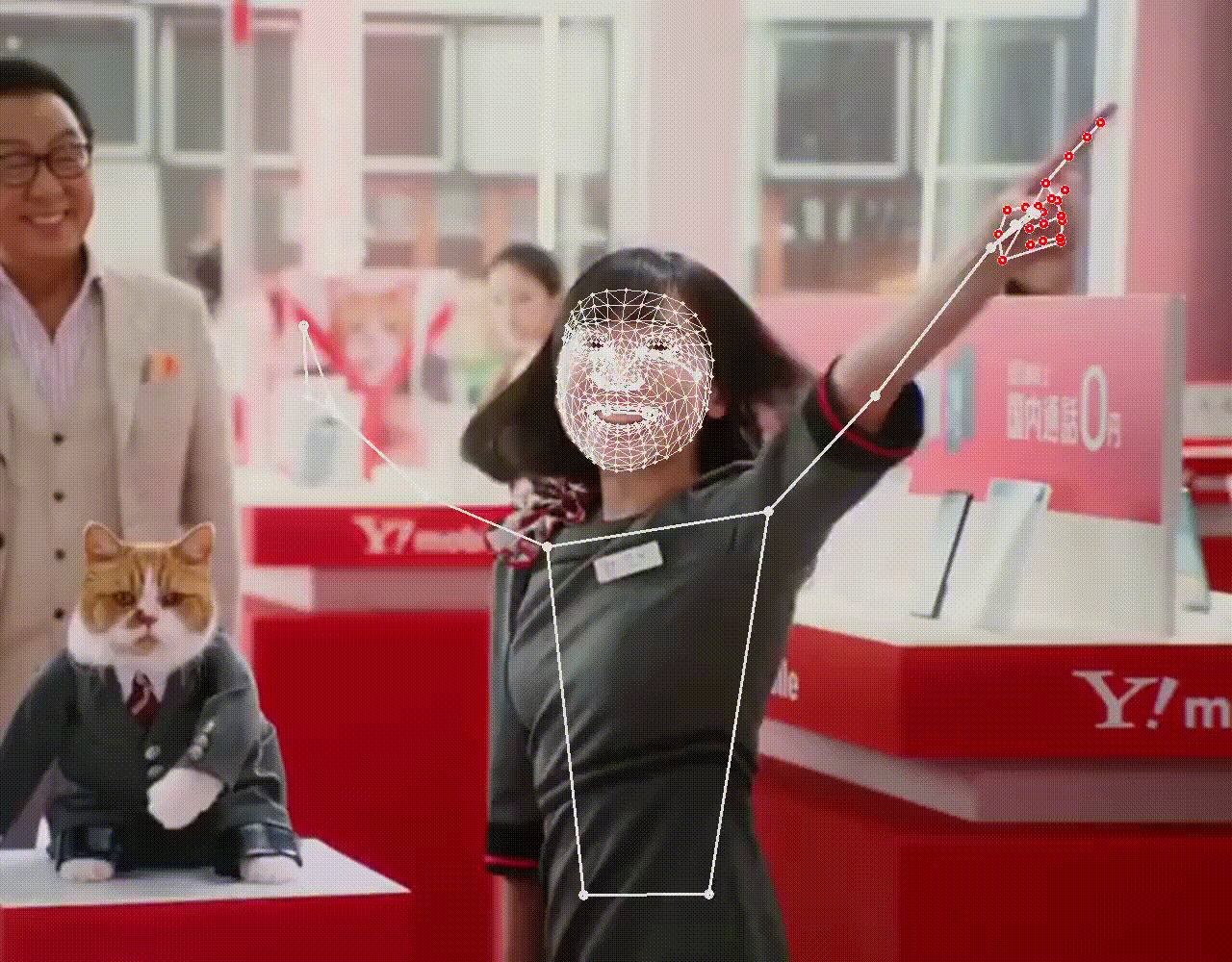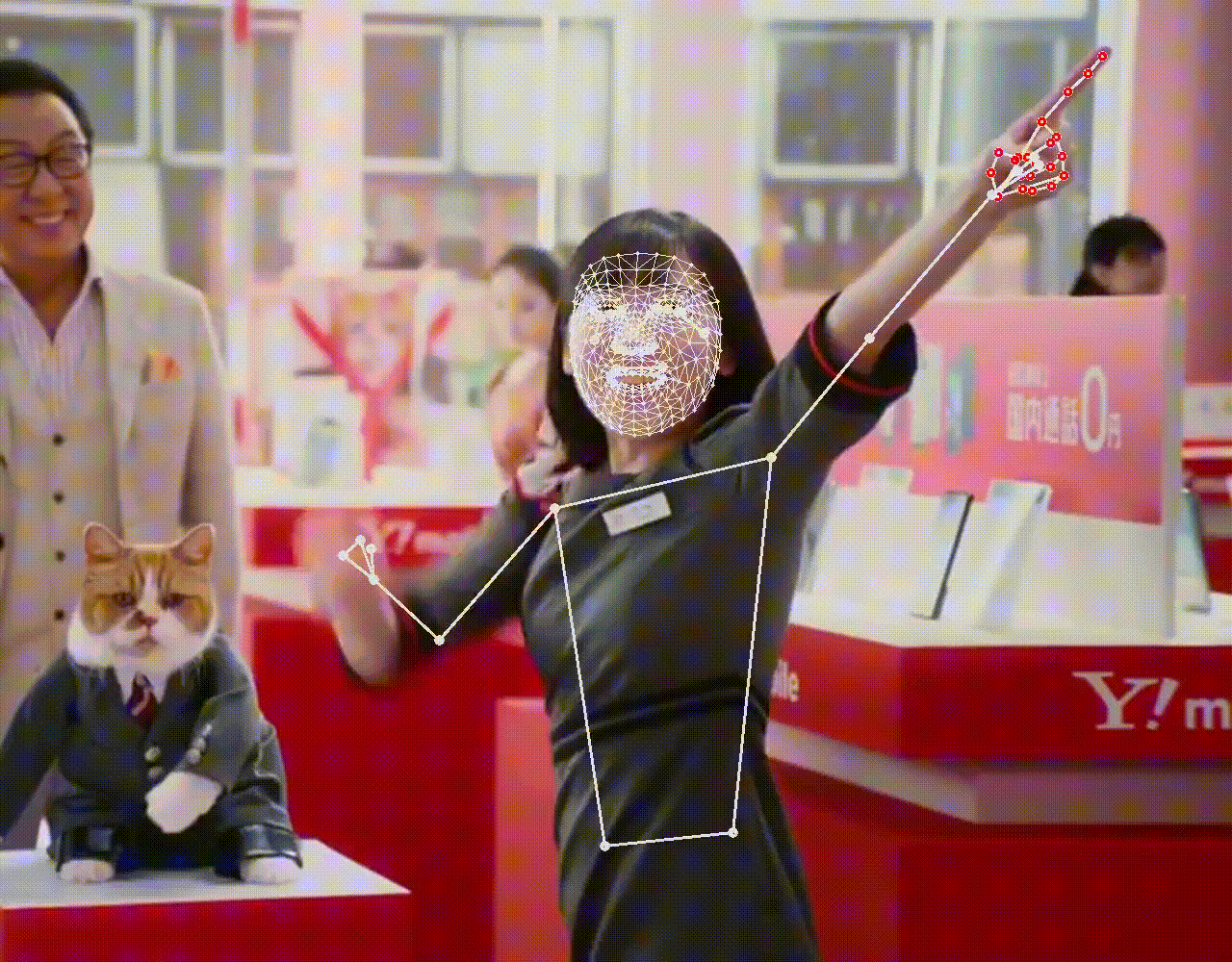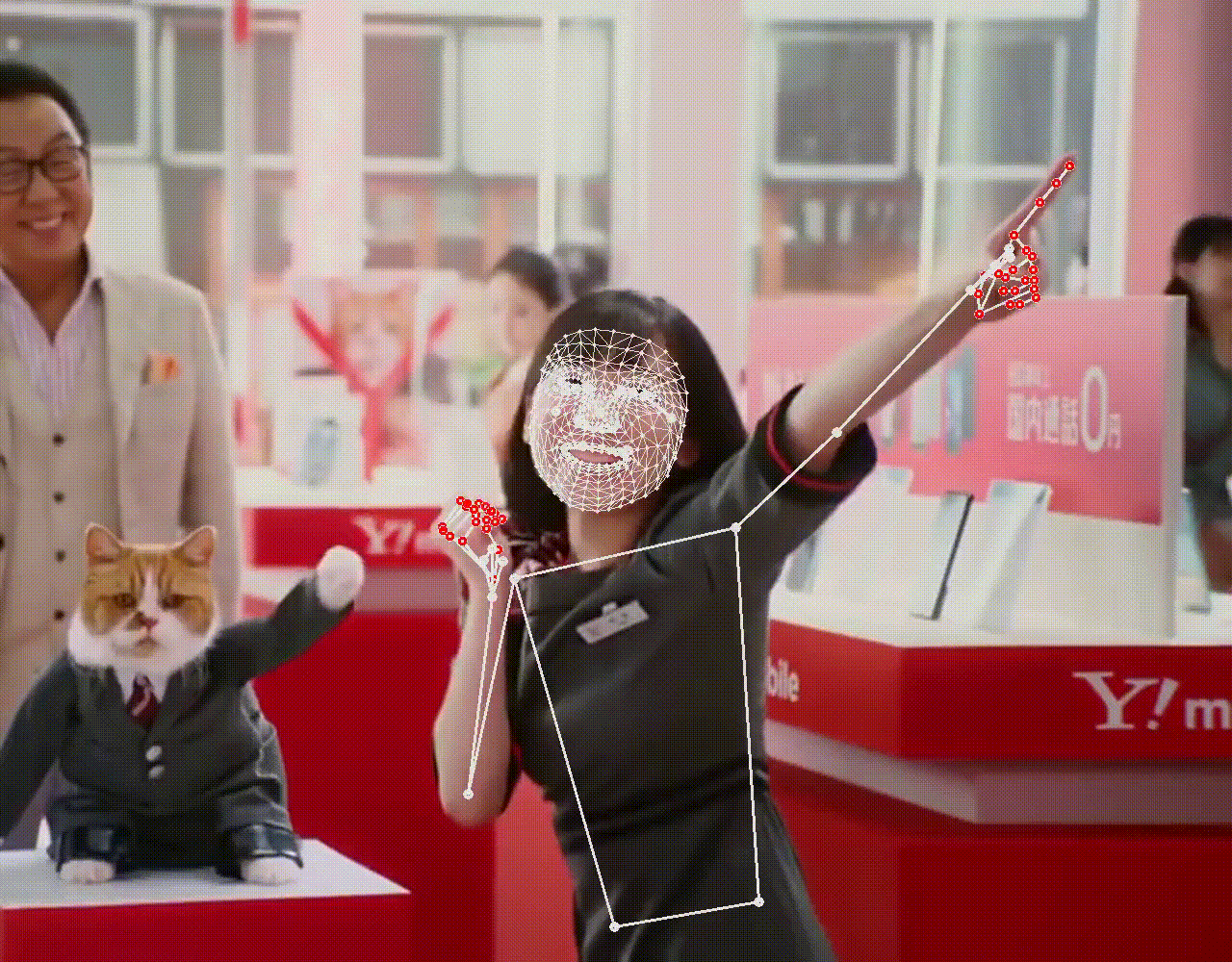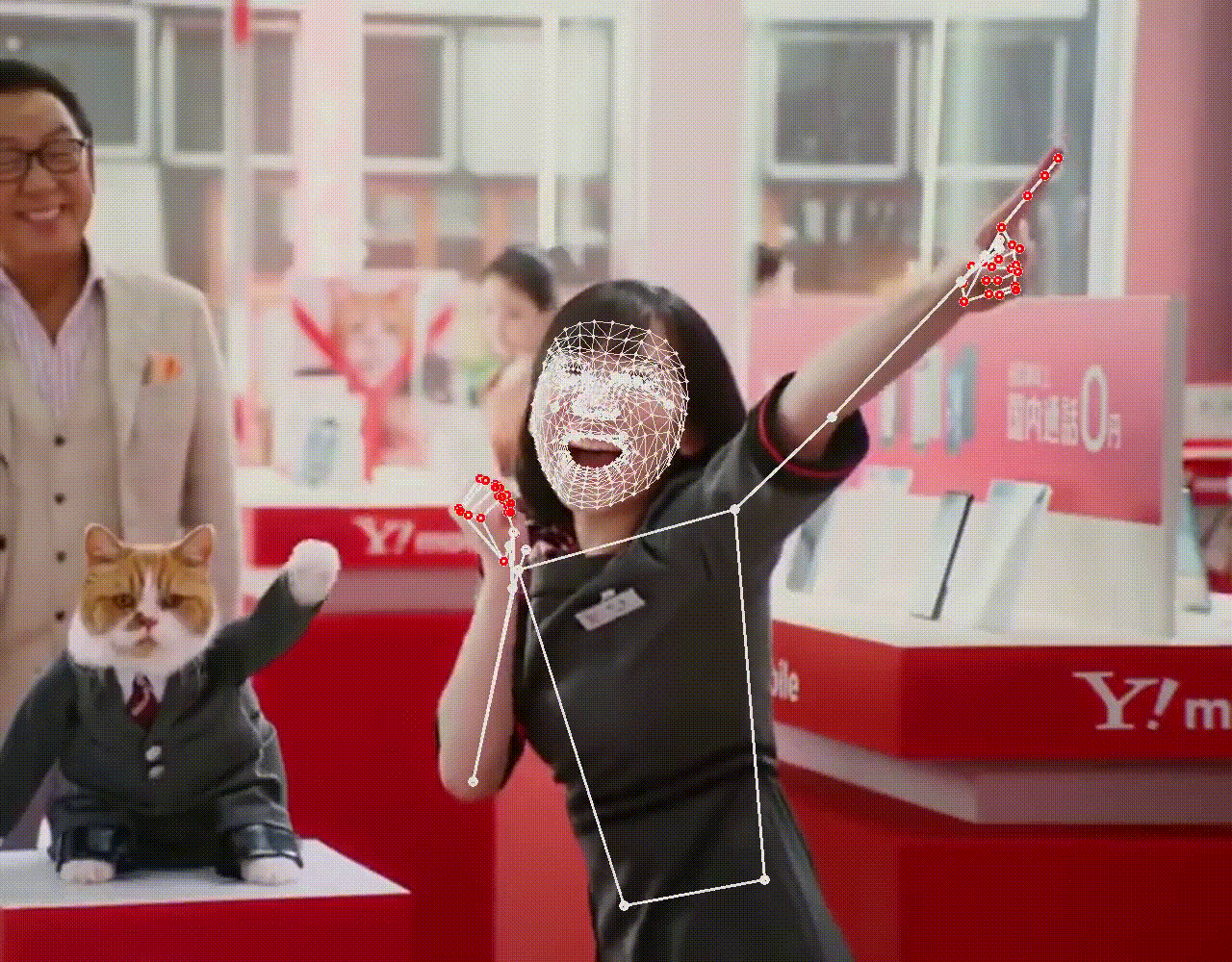
上半身が写ると、ポーズも検出していることが分かります。シングルパーソン用のため、より大きく写っている人物を優先して検出するので、後ろの男性は検出されません。
ビデオ指定のところを、video = dance.mp4 に変更して、それ以降のコードを実行すると、


全身を写した場合の検出例です。一時的に右手の検出が外れますが、まずまずではないでしょうか。
4.コード(PCのカメラから検出)
※ご注意
以下のコードは、google colabでは動作しません。ご自分のPCに、このリンクを参考にJupyter Notebookをインストールして実行して下さい。また、Git(コードをコピーするライブラリー)をインストールしてなければ、このリンクを参考に合わせてインストールして下さい。
いよいよ、メインのリアルタイム検出です。カメラ付きのPCで Jupyter Nootbook を開いて、適当なフォルダーに移動し、下記のコードを実行します。GPUは不要です。
|
1 2 3 4 5 6 |
# MediaPipeをインストール !pip install mediapipe # Gitgub からコードをコピー !git clone https://github.com/cedro3/mediapipe.git %cd mediapipe/ |
ホリスティック検出(顔・手・ポーズの統合検出)をする場合は、下記のコードを実行するだけです。左上にFPSが表示されています。私のPCは3年前に買った MacbookAir ですが、それでも10FPSくらい出ます。凄い!
|
1 |
!python sample_holistic.py |


顔の検出をする場合は、下記のコードを実行します。顔だけだと、20〜30FPSくらいでしょうか。
|
1 |
!python sample_face.py |


手の検出をする場合は、下記のコードを実行します。手だけだと、15FPSくらいでしょうか。
|
1 |
!python sample_hand.py |

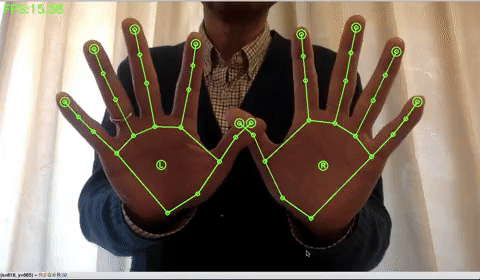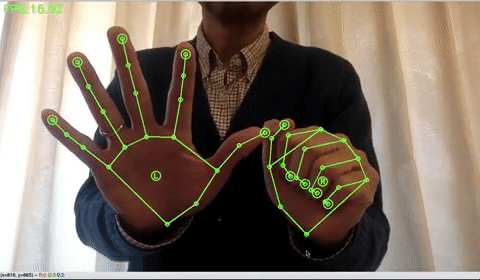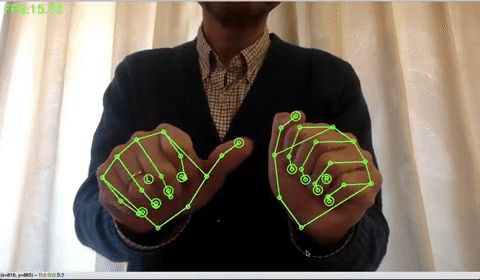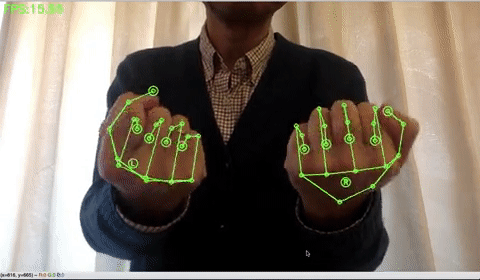
ポーズの検出をする場合は、下記のコードを実行します。ポーズだけだと、15FPSくらいでしょうか。
|
1 |
!python sample_pose.py |
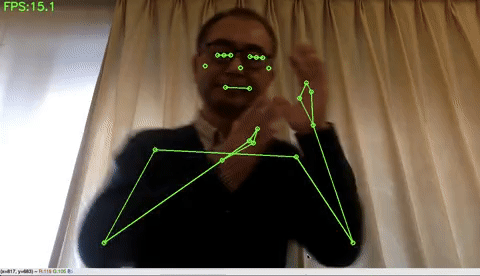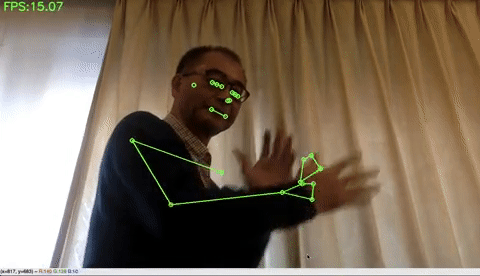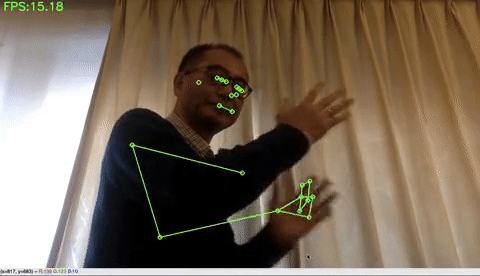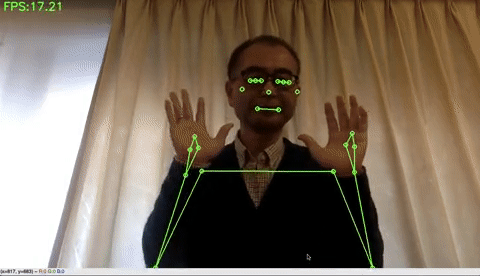
MediaPipeの狙いはエッジデバイスでの検出です。特に、スマホで、顔・手・ポーズなどの検出を使って色々な応用が出来そうですね。
では、また。
(Googleオリジナル) https://mediapipe.dev/index.html
(Githubオリジナル)https://github.com/Kazuhito00/mediapipe-python-sample
(Twitter投稿)