

今回もニューラルネットワークの設計をやってみます(第3弾)
こんにちは cedro です。
前々回の Alexnet、前回の VGGnet に続き、今回も過去に発表された有名なモデルを参考に、ニューラルネットワークの設計をしてみます。


使用するデータセットは、前々回、前回と同じCIFAR-10で、カラー32×32ピクセルの10種類の画像が、学習ファイル50,000枚、評価ファイル10,000枚あるものです。
Resnetとは?
さて、今回参考にするニューラルネットワークは、画像認識コンテストILSVRCの2015年に優勝したResnet を取り上げます。
このモデルの特徴は、とにかく層が深いことで、Alexnetが8層、VGGnetが最大19層だったのが、Resnetは最大152層まであります。
今までは、層がある深さを超えると勾配消失や勾配発散により精度が逆に悪化してしまう問題がありましたが、Resnetは残差学習という手法を取り入れ、この問題を解決しています。
さて、早速設計図をみてみましょう。


Webで良く見かける設計図がこれ。右にあるのが34層のResnet(34‐Layer residual) です。
比較のために、中央に34層の通常のニューラルネットワーク(34‐Layer plain)、左にVGGnet の一番深いモデル VGG-19が記載されています。
特徴的なのは、残渣学習を実現するために、2層おきにあるショートカットで、実線は通常のショートカット、点線は画像を1/2縮小する場合のショートカットです。
また、通常画像サイズを縮小する時には、Max Pooling が使われますが、Resnet では 畳み込み層(Convolution)で画像サイズを縮小しています。そして、最後にAverage Poolingが入り、全結合層は1つだけです。
Neural Network Console には Resnet のサンプルプロジェクトが登録されていますので、こちらも見てみましょう。
サンプルプロジェクト Resnet-34 を見てみる
特徴的な3つのポイントを見てみます。


これは、先頭の前処理です。あらかじめ大きめの画像データを用意しておいて、ImageAugmentation が主になって変形処理(拡大縮小、回転、歪、反転、輝度変更、コントラスト変更など)を行うことで、いわゆるデータの水増し効果を実現するブロックの様です。
今回の画像データセットは32×32ピクセルと極めて小さいので使う余地はありませんが、どこかで一度使ってみたい機能ですね。

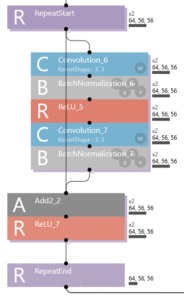
通常のショートカットの場合がこれ。分岐は単に線を2本引き出すだけで、その後の結合はAdd2 に接続すればOKです。後、RepeartStart と RepeartEnd で挟んだ部分は設定回数だけ処理を繰り返す様です。

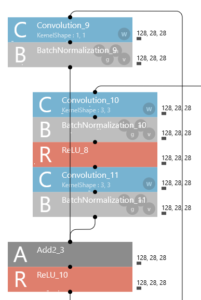
1/2に画像縮小(56×56 → 28×28)するショートカットの場合がこれ。
メインが、Convolution_10で1/2縮小(フィルター3、パディング1、ストライド2)しているので、ショートカットもConvolution_9で1/2縮小(フィルター1、ストライド2)を掛けています。こうしておかないと、Add2_3で画像サイズが合わなくなるので。
ミニResnetを設計します
オリジナルからの変更点は、1段目の畳み込み層(Convolution)を画像を縮小しない設定(フィルター3、パディング1、ストライド1)にしていることと、画像枚数は全て1/4 にしていることだけです。
後は、オリジナルに忠実にして、Neural Network Console のサンプルプロジェクトの様な Repeart 処理は止めにしました(笑)。

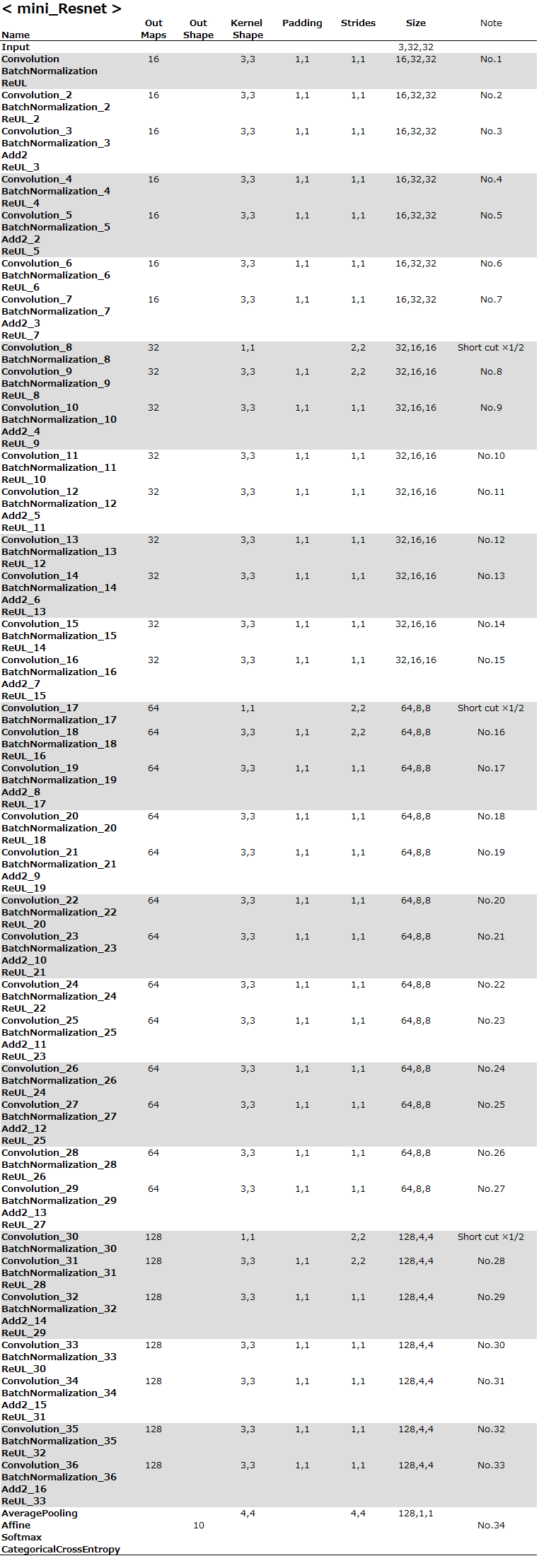
設定表にまとめるとこうなります。いやーとにかく長い、とにかくディープ!(笑)。

Neural Network Console に入力すると、こんな感じになります。1本の長いのを作ってから、後半をカーソルで選択して、まとめて右上に引っ張り上げれば、簡単に2つに折りになります。2つ折りにしても、相当長いです(笑)。
学習・評価してみる

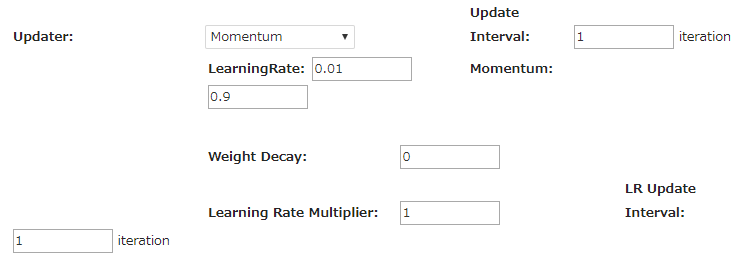
CONFIG>Optimaizer(最適化法)の設定画面です。通常はAdamが使われるようですが、Resnet はちょっと異なっているようです。
サンプルプロジェクトを見ると、Resnet-18,34 は Nesterov、Resnet-50,101,152 は Momentum が使われていますが、今回は Momentum を使ってみます。

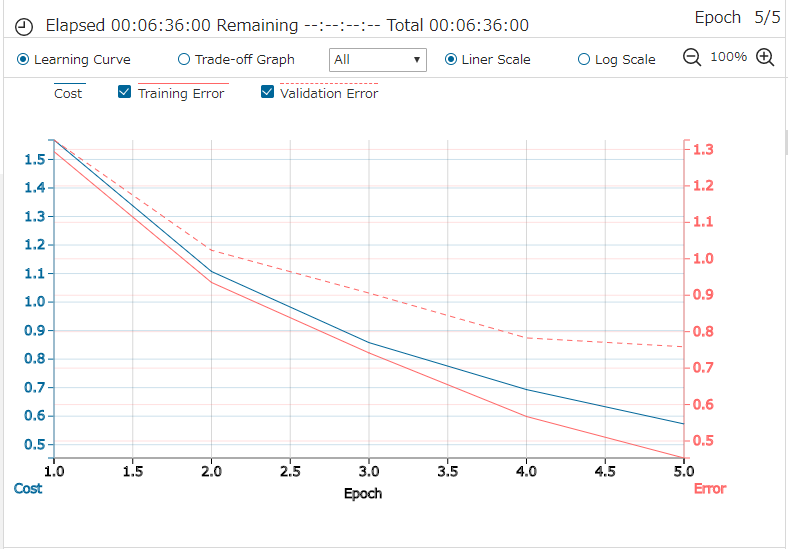
とりあえず、Batch=64、Max Epoch=5 で学習して様子を見てみます。
上のキャプチャー画像を見て気が付かれたと思いますが、今回も Neural Network Console の Cloud 版を活用してます。メールを変えて登録し直すと、何度でも10時間お試しができますので(笑)。

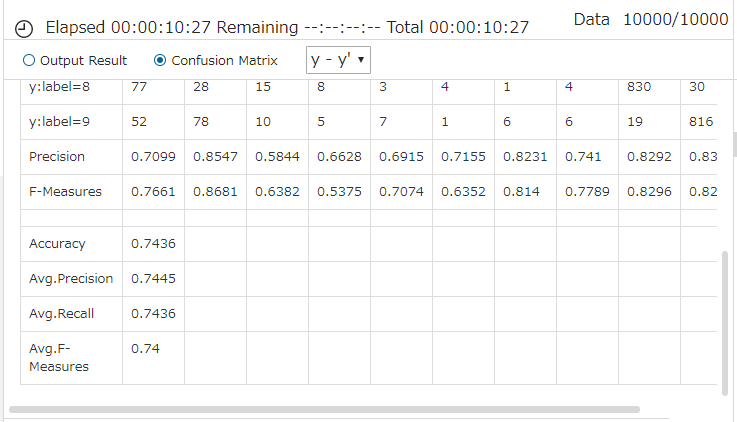
評価結果です。5 epoch での認識精度(Accuracy)=74.36%は、あまり良くないです。ミニAlexnet の73.07%よりは良いですが、ミニVGGnet MarkⅡ の 80.71%には遠く及びません。
まあ、ミニVGGnet MarkⅡ には、時代考証を無視して最新の Batch Normalization で最強にしましたので、その影響もありますが。
ちょっと気になるが、学習が進めば急に精度が上がってくるかもしれないと思い、一気に勝負を付けようと、20 epoch まで回してみることにしました。

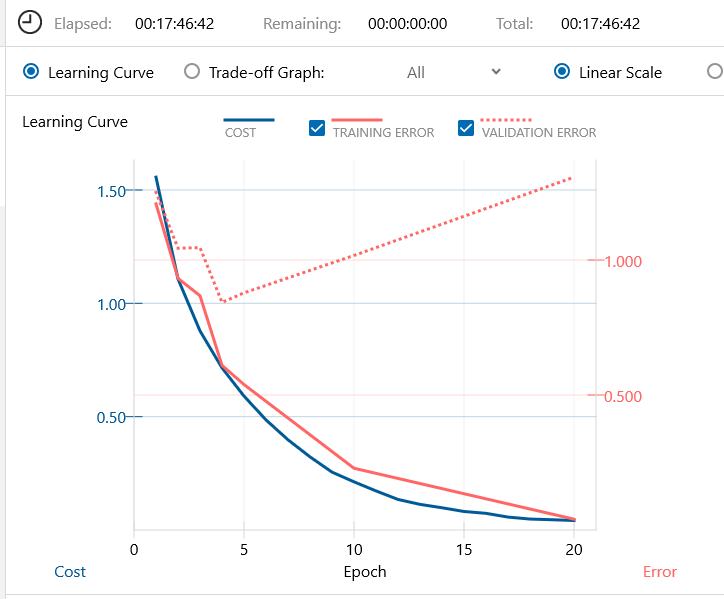
20 epoch の学習曲線がこれ。なんか、過学習っぽい、いやな感じ。

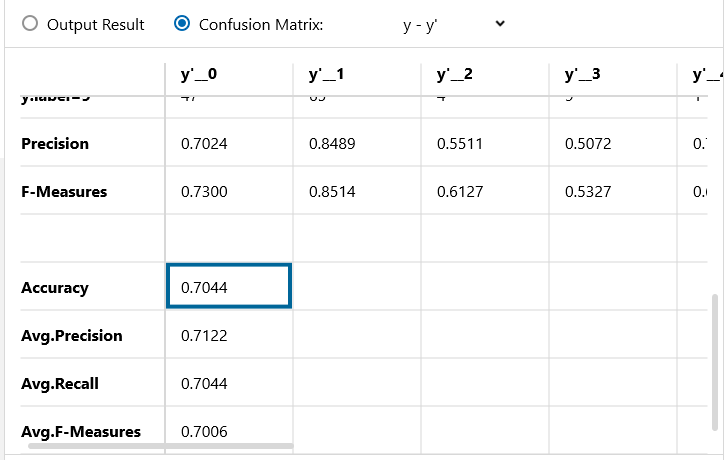
5 epoch の時の精度が74.36%で、20 epoch の時の精度が70.44%で、▲3.92悪化しています。
なんと、20 epochで明らかな過学習の結果となってしまいました。いくらなんでも、ちょっと早すぎる感じがします。
何か根本的な問題な様な気がして、Webで調べてみると「最適化法はSGDが使われており、学習率は0.1でスタートし、学習中に2回学習率を 1/10に減衰する」らしいことが分かりましたので、それを参考に Optimizer の設定を変更してみることにしました。

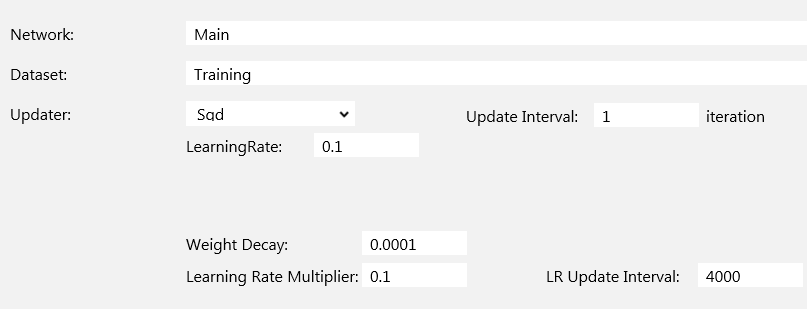
CONFIG>Optimaizer(最適化法)の設定画面です。最適化法はSgd(SGD)を選択し、Learning Rate(学習率)は0.1、Learning Rate Multiplier(学習係数)は0.1、学習係数を効かせるインターバルは4000と設定しました。
*Batch Size 64、学習データ数50,000で、インターバル 4000は 何Epochに相当するか計算すると、約5 epochになります(4000×64÷50,000=5.12)。

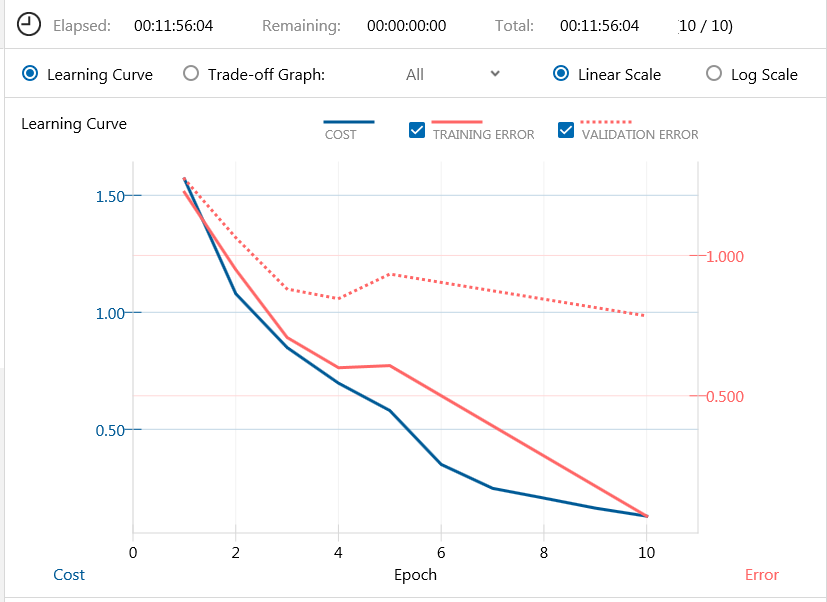
5 epoch の所で学習率を1/10に減衰させ、過学習を防いでいるつもりです(笑)。


10 epoch 時の評価結果がこれ。まだまだ不完全ですが、改善は見られました。
ディープラーニングは、学習法とかパラメターの設定については奥が深そうですね。
では、また。
【 メモ 】
実は、Resnet のサンプルプロジェクトには、初心者がつまずくトラップの様なものがあり、自分自身悩んだので、他の方の参考にメモを残しておきます。
1)サンプルプロジェクトResnet-18、34のCONFIG > Executor(推論実行) は64回評価をして平均を取る設定になっているのでご注意下さい。このサンプルプロジェクトを流用して組むと、評価時間があまりにも長くなり、その理由に気づくのに結構時間がかかります。私、体験済みです(笑)。
2)サンプルプロジェクトResnet-18、34 の MulScalar(先頭から3つ目のレイヤー)の設定値が小さ過ぎて画像データが真っ暗になるので、ご注意下さい。このサンプルプロジェクトを流用して組むと、認識精度があまりにも低くなり、その理由に気づくのに結構時間がかかります。設定値は1でよいと思うし、そもそも無くてもよい(50、101、152にはない)。私、体験済みです(笑)。
3)Resnet のEDITは3画面(Training、Validation、Runtime)あり、ValidationにはSliceというレイヤー(Inputの次)が使ってありますが、これは320×320の画像から224×224の画像を切り抜くレイヤーです。最初何のために使われているか見当がつかず、なんかストレスでした(笑)。