

今回もニューラルネットワークの設計をやってみます
こんにちは cedro です。
前回のAlexnetに続き、今回も過去に発表された有名なモデルを参考に、ニューラルネットワークの設計をしてみます。


使用するデータセットは、前回同様CIFAR-10で、カラー32×32ピクセルの10種類の画像が、学習ファイル50,000枚、評価ファイル10,000枚あるものです。
VGGnet とは?
さて、今回参考にするニューラルネットワークは、画像認識コンテストILSVRCの2014年に2位になったVGGnet です。
この年の優勝はGooglenetなのですが、VGGnet は前回参考にしたAlexnetの進化形で、構造がシンプルで美しく、今でも良く使われるニューラルネットワークなので、こちらを参考にします。
早速設計図を見てみましょう。

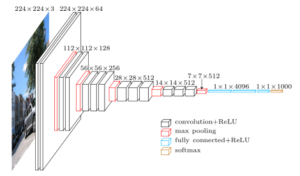
作ったのは、オックスフォード大学のVGG(Visual Geometry Group)というチームで、色々なバリエーションがありますが、良く見るのはこのVGG-16というやつ。なんか正統派って感じですね。
名前の由来は、VGGチームが作った、畳み込み13層+全結合層3層=16層のニューラルネットワークということで、VGG-16となっているそうです。
mini_VGGnet の設計
さて、これを参考に、どうニューラルネットワークを設計するかですが。
例によって、ILSVRの入力サイズは224×224、CIFAR-10のサイズは32×32なので、大胆にも最初の畳み込み4層分は省略して、畳み込み層の5層目からスタートすることにします。
また、GPU無し環境を考慮して、畳み込み各層の画像枚数はオリジナルの1/4にしておきます。

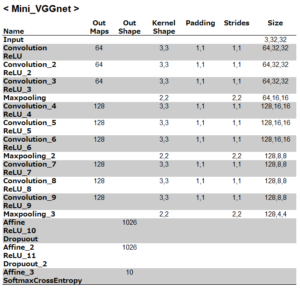
設定をまとめてみるとこんな感じです。


上記の設定をSONY Neural Network Console に入力すると、こんな感じになります。長くなるので、2列表記にしています。
基本的にはmini_ALexnetと同じ様な構造ですが、畳み込み層が5→9へ増え、よりディープなニューラルネットワークになっています。このモデルの名前は、mini_VGGnetと名付けます。
なお、先回mini_Alexnet の時に畳み込み層1と2に入れていた、Batch Normazilation は、省いておきました。なぜなら、Batch Normazilation が発表されたのは2015年で、VGG16の発表は2014年ですから、時代考証すると、入れてはまずいからです(笑)。
学習・評価の実行
まず例によって、5epoch やってみて感触を掴みます。

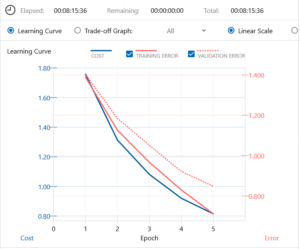
畳み込み層5→9のアップは伊達じゃなく、5epoch に何と8時間15分掛かりました。さあ、これだけ時間を掛けたんだから、精度はさぞや期待できそうかな、と思って評価結果を見てみると。

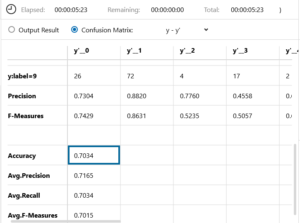
ガーン!なんと精度は70.34% ! mini_Alexnet の5epoch の時の精度は73.07%ですから、mini_Alexnet より悪い結果なんです。うーん、何が悪いんだろう。
何が影響しているのか?
なぜ、2014年モデルが2012年モデルに負けてしまうのか。
思い当たるのは、mini_Alexnet には時代考証を無視して、Batch Normazilation を畳み込み層の1と2に入れた事くらいですが、それがそんなに効くとも思えないし、と悩んでいました。
しかし、Webで調べていると、こんな記述がありました。
Batch Normalizationは2015年にSergey IoffeとChristian Szegedyが提案した手法。具体的には、ミニバッチごとに平均が0,分散が1になるように正規化を行うことで、学習の収束速度の向上、Dropoutの必要性の低下、事前学習の必要性低下 などの効果が得られる。
また、こんな強烈なコメントもありました。
Batch Normalization を使っていないやつは、人生を無駄にしている。
もしかしたら、意外に効果があるのかもしれない。しかし、もし本当に効果がある手法であれば、最新のモデルには必ず使ってあるはず、どんな使い方をしているのかも含めて、調べてみようと思いました。
そういえば、ILSVRCの2015年に優勝したResnetが、Neural Network Consoleのサンプルプロジェクトの中にあったなーと思い出し、確認してみると。

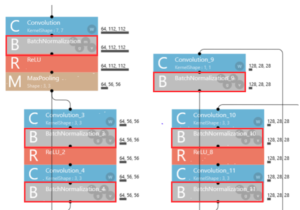
なんと驚いたことに、Resnetには全ての畳み込み層の後に、必ずBatch Normalization が入っていました。
なるほど、そういうことですか。それならと、mini_VGGnet の9つの畳み込み層の後には全部 Batch Normalization を入れてみることにしました。Mini_VGGnet_MarkⅡと名付けます(笑)。
mini_VGGnet MarkⅡの設計

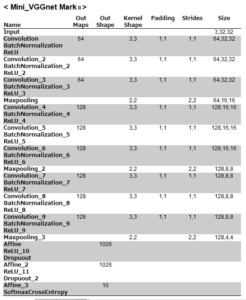
設定をまとめると、こうなります。Batch Normalization 9 個追加!


Neural Network Console に入力すると、こんな形。とりあえず学習を 5epoch やります。
再度、学習・評価

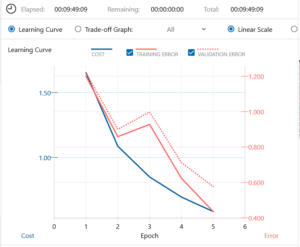
Batch Normalization を9層追加した結果、学習時間は1時間34分伸びましたが、Validation Error は明らかに改善されているようです。

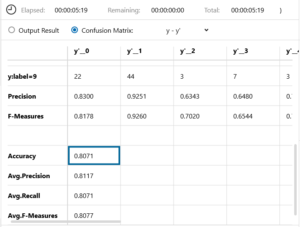
恐る恐る、Confusion Mtrix を見てみると、なんと驚いたことに、精度が10%以上もアップして、80.71%に!
Batch Normalization の威力凄い!何か、ネットワーク構造の革新より、この手法の方が効きが大きいんじゃないかと思うほどでした。


最終的には、10epoch の学習まででギブアップ。掛かった時間は17時間16分。私の MacbbokAir くん大変お疲れ様でした。

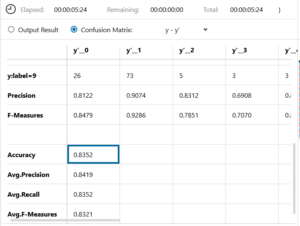
精度は83.52%でした。もっとやってみたい気はするが、ここまでにしました。
しかし、こういう展開になって来ると、GPUが付いた本格的なマシンが欲しくなりますねー。少なくとも10倍くらい早くなるとすると、17時間掛かったのが2時間かからずに終わってしまうわけですから。
ちょっと危険ですねー、この展開(笑)。
では、また。