

今回は、どうやってNNabla にデータセットを読み込ませたら良いのか確認してみます。
こんにちは cedro です。
最近、Neural Network Console で開発したプログラムを実装してみたいと思っていて、その準備として、Neural Network Libraries (NNabla)を触っています。
やっぱり実装しようと思うと、Neural Network Console の下で走っている、NNabla を少し知っておかないとなー、という思いです。
先回、NNabla の example の dcgan をまずそのまま動かして、その後URLを変更し Fashion Mnist を読み込ませて画像生成をさせてみましたが、どういうデータ形式で、どうやって NNabla にデータセットを読み込ませるかはブラックボックスになっていて、全く理解できませんでした。
Neural Network Console であれば、データセットの読み込み機能は、あらかじめアプリケーション中に組み込まれ見える化されていて、丁寧な日本語のマニュアルもあるので、初心者でも直ぐオリジナルデータを作って読み込ませることが出来ます。
しかしながら、NNabla は、英語のDocumentや Example を参考に、データの読み込み機能を自分で組み込む必要があります。その方が自分が本当に必要なものだけを過不足なく組み込めるので上級者にとっては良いのでしょうが、初心者にとっては敷居が高いです。
ということで、今回は、どうやって NNabla にデータセットを読み込ませたら良いのかを実践で確認したいと思います。
Document や Example を見てみる
参考資料は結構あります。
1)NNabla_Master:https://github.com/sony/nnabla
*HP右上にある緑色の「Clone or download」 ボタンからプログラムを一式ダウンロードできます。
2)NNabla_Example_Master:https://github.com/sony/nnabla-examples
*HP右上にある緑色の「Clone or download」 ボタンからプログラムを一式ダウンロードできます。
3)Documet:http://nnabla.readthedocs.io/en/latest/
最初は、どこから読み解いていいものやら、全く分かりませんでした。たぶん、上級者の方なら、これらを斜め読みすればもう十分なんでしょうが、Python の基礎さえ勉強したこともない私にとっては、歯が立たちません。
しばらくすると、キーワードは Data Iterator であることは分かり、ポイントとなるのは NNabla-Master の Utils にある data_iterator.py らしいことは分かったのですが、具体的にどうやって使ったら良いのかが分からない。
data_iterator.py には、様々な場合の処理プログラムが沢山記載してあって、コメントも山ほどあるのですが、具体的な使い方は理解できない。必要なところだけ残して後は削除するのかなとも思いましたが、pyはプログラムなので、それはないだろうと。
色々とプログラムの規則性を見ていたら、別のプログラムの一部の機能を利用したい時は、冒頭に「from プログラム名(.pyは省略) import 機能名」と宣言して、必要な時に「機能名にパラメーターを付けて呼び出せば良い」ことに、やっと気づきました。
これって後で調べたら、「from モジュール名 import クラス名(もしくは関数名や変数名)」というPythonの基礎文法なんですね。やっぱり、基礎は大事ですわ。
ずいぶん時間が掛かりましたが、分かってしまえば、なんてことはない。
まず、data_iterator.py だけを使ってやってみて、エラーが出る度にその対応をすれば、関連するプログラムが後3つあり、一部プログラムの修正が必要であることは直ぐ分かりました。
結果、データ読み込みに必要なプログラムは、 NNabla-Master の nnabla/python/src/nnabla/utils にある ①data_iterator.py、②data_source.py、③data_source_implements.py、④data_source_lodaer.py の4つでした。
なぜ4つ必要なのか。①が②と③を呼び出し、③が④を呼び出すからです。
プログラムの修正箇所は2箇所あって、1つは data_iterator.py の冒頭部分。
|
1 2 3 4 5 6 7 8 9 |
from .data_source import DataSourceWithFileCache from .data_source import DataSourceWithMemoryCache from .data_source_implements import SimpleDataSource from .data_source_implements import CsvDataSource from .data_source_implements import CacheDataSource from .data_source_implements import ConcatDataSource |
.data_source の先頭に付いている「.」を6箇所削除します。
|
1 2 3 4 5 6 7 8 9 |
from data_source import DataSourceWithFileCache from data_source import DataSourceWithMemoryCache from data_source_implements import SimpleDataSource from data_source_implements import CsvDataSource from data_source_implements import CacheDataSource from data_source_implements import ConcatDataSource |
こんな形にします。簡単ですね。
もう一つは、data_source_implements.py の冒頭部分。
|
1 2 3 4 5 |
from .data_source import DataSource from .data_source_loader import FileReader, load from nnabla.logger import logger |
同じく、.data_source の先頭に付いている「.」を2箇所を削除します。
|
1 2 3 4 5 |
from data_source import DataSource from data_source_loader import FileReader, load from nnabla.logger import logger |
こんな形にします。
この2つの修正をしたら、後はこの4つのプログラムは一切いじる必要はなく、読み込みたいデータセットの種類が変わったらメインプログラムからの呼び出し方を変えるだけで対応が出来ます。上手い仕組みですね。
それにしても、なぜ素人でも直ぐ気づくようなミスをプログラムに残しておくかの理由はよく分かりませんが、もしかしたら、まだデバック中であるというサインなのかもしれません(?)。
そういう心配もあるので、次にしっかり検証してみます。
3つの方法を検証する
NNabla の example にある classification.py (MNISTの0~9の数字を識別するプログラム)を使って、3つの方法でデータセットを読み込ませ、それぞれ識別を行なってみます。
1)URLからダウンロードして読み込む

まず、example そのままで実行します。必要なファイルは上記の3個で、nnabla-example/mnist-collection の中にあります。

Anaconda Navigator を起動し、NNabla の仮想環境で Open Terminal を開きます。

>cd C:\Users\cedro\classification で自分の作ったフォルダーに移動し
>python classification.py で実行します。
実行すると、指定したURLからダウンロードが始まり、自動的に処理が進んで行きます。
見ていて気持ちは良いですが、Mnist にしか使えないのが残念なところ。

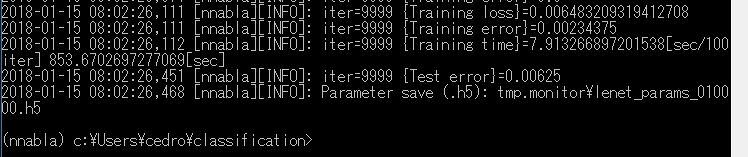
約14分かけて、iter=9999(10,000ステップ) で学習が終了しました。学習データは50,000、バッチ数は64ですから、10,000÷(50,000÷64)=12.8 epoch です。
結果は、[Test error]=0.00625 ですから、精度は99.38%ということになります。良い感じです。
2)Neural Network Console で作った csv 形式で読み込む

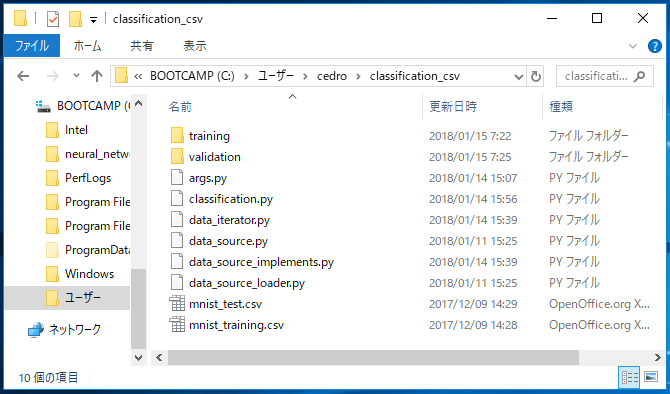
今度は、Neural Network Console で作った、CSV形式で読み込んでみましょう。必要なファイルは、この10個。
さっき使っていた mnist_data.py は不要となり、代わりに例の4つのプログラムが入ります。
それから、Neural_network_console_110¥samples¥sample_dataset¥MNISTにある、mnist_training.csv (学習ファイル)、mnist_test.csv (評価ファイル)、そして画像が入っている training フォルダーとvalidation フォルダーをコピーして来ます。
classification.py で2箇所、呼び出し方を修正します。
|
1 2 3 |
from mnist_data import data_iterator_mnist |
これを
|
1 2 3 |
from data_iterator import data_iterator_csv_dataset |
こう修正します。data_iterator.py プログラムの data_iterator_csv_dataset の部分を使うよ、と宣言しているわけです。
|
1 2 3 4 |
data = data_iterator_mnist(args.batch_size, True, rng=RandomState(1223)) vdata = data_iterator_mnist(args.batch_size, False) |
もう一つ、これを
|
1 2 3 4 |
data = data_iterator_csv_dataset(".\\mnist_training.csv",args.batch_size, True, rng=RandomState(1223)) vdata = data_iterator_csv_dataset(".\\mnist_test.csv",args.batch_size, False) |
data = data_iterator_csv_dataset (” CSVファイルのある場所 ”, ・・・・)と修正しています。冒頭で宣言した data_iterator_csv_dataset を使ってここで、パラメーターを加えて呼び出しているわけですね。
今回、分かりやすくするために、CSVファイルと画像フォルダーを classification_csv フォルダーの中にコピーしているので “.¥¥mnist_training.csv” と相対パスで指定していますが、
CSVファイルと画像データフォルダーをコピーせずに、例えば “C:¥¥Neural_Network_console_110¥¥samples¥¥sample_dataset¥¥MNIST¥¥mnist_training.csv” と絶対パスで指定(自分が何処にNeural Network Console をインストールしたかで指定の仕方は変わります)する方法もあります。
後、補足ですが、こういう場合のパス指定は、¥ ( \ ) ではなく、¥¥ ( \\ ) とダブルで書きます。

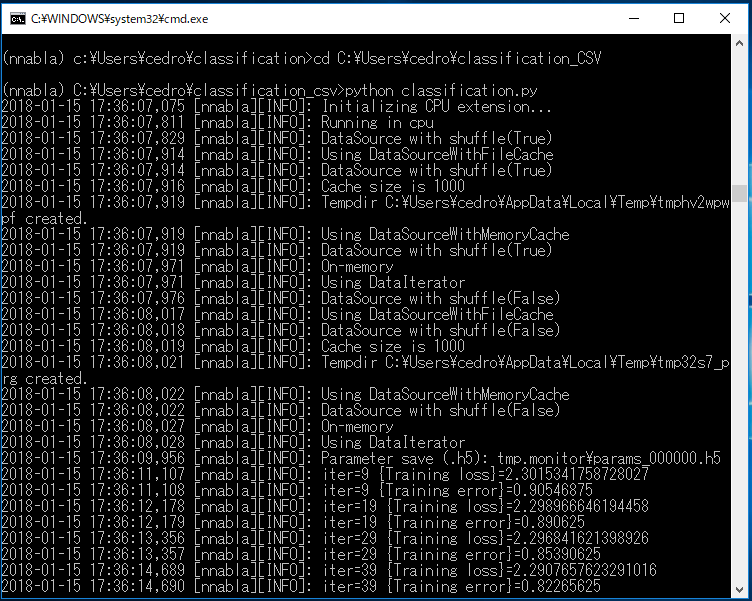
>cd C:\Users\cedro\classification_csv で自分の作ったフォルダーに移動し
>python classification.py で実行します。

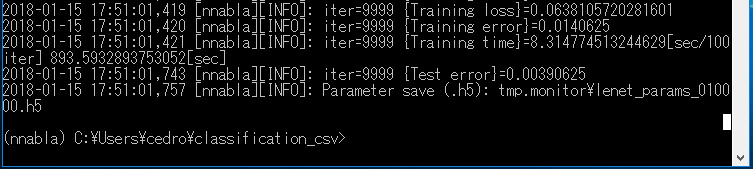
iter=9999(10,000ステップ) やった結果は、前とほぼ同じ [Test error]=0.00390625 で、精度は99.61%です。
ちゃんとデータセットを読み込んでいますね。
3)Neural Network Console で作った cache ファイルで読み込む

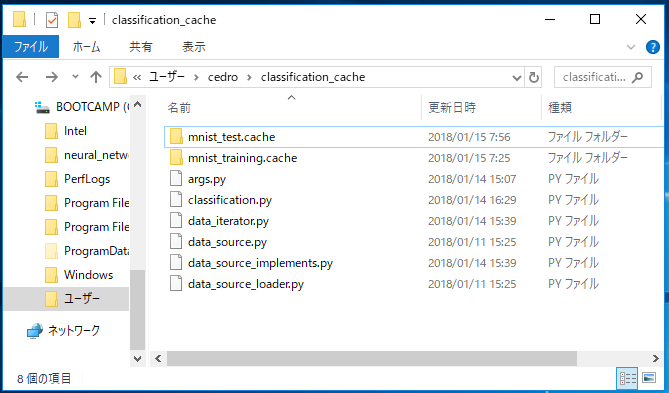
今度は、Neural Network Console で作った(というかシステムが勝手に作りますが)Cacheファイル形式で読み込んでみましょう。必要なファイルは、この8個。
先程の学習ファイル、評価ファイルと2つの画像フォルダーは不要となって、代わりに mnist_test.cache フォルダーと mnist_training.cache フォルダーが入っています。
この2つのフォルダーには、Neural Network Console の学習をスタートすると、システムが自動的に作るキャッシュファイル(cache_00000000_00000099.h5 という様な名前が付いています)が格納されています。
この2つのキャッシュファイルフォルダーは、Neural_network_console_110¥samples¥sample_dataset¥MNIST からコピーして来ます。
classification.py で2箇所、呼び出し方を修正します。
|
1 2 3 |
from mnist_data import data_iterator_mnist |
これを
|
1 2 3 |
from data_iterator import data_iterator_cache |
こう修正します。
|
1 2 3 4 |
data = data_iterator_mnist(args.batch_size, True, rng=RandomState(1223)) vdata = data_iterator_mnist(args.batch_size, False) |
もう一つ、これを
|
1 2 3 4 |
data = data_iterator_cache(".\\mnist_training.cache",args.batch_size, True, rng=RandomState(1223)) vdata = data_iterator_cache(".\\mnist_test.cache",args.batch_size, False) |
こう修正します。ここでは、classification_cache フォルダーの中に、キャッシュフフォルダーを2つをコピーしていますので、相対パスで指定をしていますが、先程同様、コピーせず絶対パスで指定をすることも出来ます。

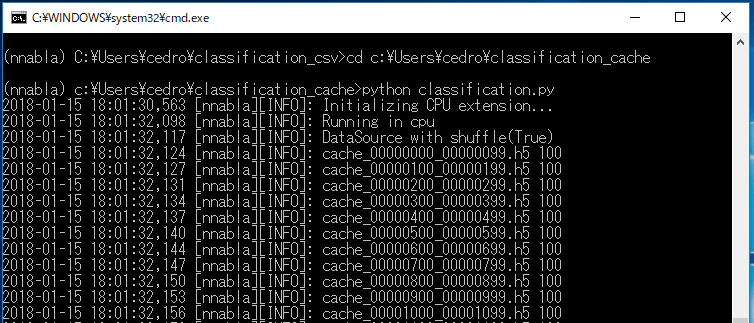
>cd C:\Users\cedro\classification_cache で自分の作ったフォルダーに移動し
>python classification.py で実行します。
まず、キャッシュファイルを一気に読み込んでから、処理が始まります。

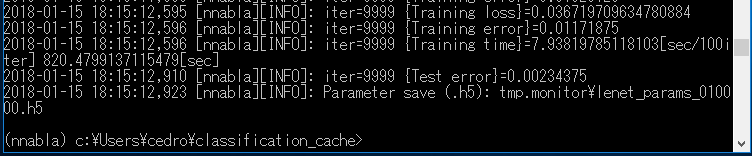
iter=9999(10,000ステップ) やった結果は、前とほぼ同じ [Test error]=0.00234375 で、精度は99.77%ということになりました。
こちらも、ちゃんとデータセットを読み込んでいるようです。
NNabla は Neural Network Console で作ったデータセットをそのまま使える!
今回、データセットの読み込みに関して、頭のモヤモヤがすっきりしました。
NNabla は Neural Network Console で作ったデータセットがそのまま使えるんです。
ということは、Neural Network Console でオリジナルのデータセットを作れば、そのまま NNabla が読めるということです。
さすがSONYさん、シームレスな設計思想が素晴らしい!
NNabla が少し身近になったような気がします。
では、また。
投稿後記
今回、例の4つのプログラムを使って、CSVファイル形式やCacheファイル形式のデータセットの読み込みをやってみました。
しかし、NNabla Document に、もっとスマートな方法があることに気づきました。
実は、CSVファイル形式やCacheファイル形式のデータセットの読み込み機能は、NNablaの標準APIとして組み込まれているので、このAPIを呼び出すだけで実現でき、その場合は例の4つのプログラムは不要なんです。
今回の場合どうなるか、記載しておきます。
|
1 2 3 4 5 6 7 |
#冒頭部分 import nnabla.utils.data_iterator as d #データ読み込みの部分 data = d.data_iterator_csv_datase(".\\mnist_training.csv",args.batch_size, true, rng=RandamState(1223)) vdata = d.data_iterator_csv_dataset(".\\mnist_test_csv",args.batch_size,False) |
CSVファイル形式の場合
|
1 2 3 4 5 6 7 |
#冒頭部分 import nnabla.utils.data_iterator as d #データ読み込みの部分 data = d.data_iterator_cache(".\\mnist_training.cache",args.batch_size, True, rng=RandomState(1223)) vdata = d.data_iterator_cache(".\\mnist_test.cache", args.batch_size, False) |
casheファイル形式の場合
もちろん、ブログで書いた様に例の4つのプログラムを使っても動きますが、標準APIがあるなら、それを利用するのがスマートですよね。
まだまだ修行が足りませんが、1つづつ実践で覚えて行くことにします。
では、また。