

今回は、PyTorch で Alexnetを作り CIFAR-10を分類してみます。
こんにちは cedro です。
新年から、「PyTorchニューラルネットワーク実装ハンドブック」を斜め読みしながらコードをいじっています。
第4章に、CIFAR-10をAlexNetを真似た構造のネットワークで画像分類するところがあるのですが、実はこれと同じ様な内容のブログ「SONY Neural Network Console でミニAlexnet を作る」を書いたことがあって、とても懐かしい気がしました。
ということで、今回は、PyTorch で Alexnetを作り CIFAR-10を分類してみます。
Alexnet とは?
Alexnet は、画像認識コンテスト ILSVRC で2012年に優勝したネットワークで、コンテストに初めてディプラーニングを持ち込み、それまで人が見つけていた特徴量を機械自からが見つける形に転換することで認識精度の驚異的な改善を図り、画像認識の世界に革命を起こしました。
Alexnet 以降、画像認識はディープラーニング一辺倒になり、その将来性に目を付けたGoogle やFacebook や百度は、ディープラーニングを研究している会社をどどん買収して行くことになります。
さて、その設計図を見てみましょう。

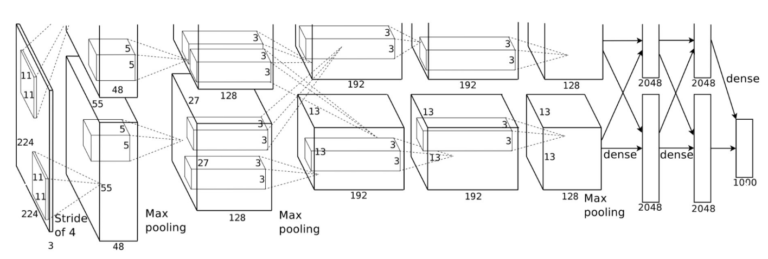
入力は 3チャンネルの244×244で、そこから後は上下に分かれて上の方は図が切れていますが、上下は同じものです。2つに分かれている理由は、2012年当時のGPUの性能から、全部を1枚のGPUに載せることはできなかったため2枚に分けたのです。
1) 3*224*224 を Convolution で kernel_size=11, stride=4, padding=2 → size=55*55
2) 96*55*55 を Max_pooling で kernel_size=3, stride=2 → size=27*27
3) 256*27*27 を Convolution で kernel_size=5, stride=1, padding=2 → size=27*27
4) 256*27*27 を Max_pooling で kernel_size=3, stride=2 → size=13*13
5) 384*13*13 を Convolution で kernel_size=3, stride=1, padding=1 → size=13*13
6) 384*13*13 を Convolution で kernel_size=3, stride=1, padding=1 → size=13*13
7) 256*13*13 を Convolution で kernel_size=3, stride=1, padding=1 → size=13*13
8) 256*13*13 を Max_pooling で kernel_size=3, stride=2 → size=6*6
8) dense_4096
9) dense_4096
10) dense_1000
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
class AlexNet(nn.Module): def __init__(self, num_classes=1000): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), ) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = x.view(x.size(0), 256 * 6 * 6) x = self.classifier(x) return x |
ネットワークをPyTorch のコードで書くと、こんな形。但し、このモデルはILSVRCのコンテスト用のため入力は3*224*224が前提、一方CIFAR-10は3*32*32なので、修正が必要です。
そのため、最初のConv2dの設定を(kernel_size=11→3, stride=4→1, padding=2→1)に変更し画像サイズを変更させない様にします。そして、3つあるMaxPool2dの設定を(kernel_size=3→2)に変更します。
こうすることで、画像サイズが変化するのはMaxPool2dの3回だけになり、32*32→16*16→8*8→4*4 と全結合層の直前でなんとか4*4になるはずです。本当に、そうなるかチェックしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import torch import torch.nn as nn features1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2)) test1 = torch.FloatTensor(1, 3, 224, 224) print('original_version_shape = ',features1(test1).shape) features2 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1), # change nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), # change nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), # change nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2)) # change test2 = torch.FloatTensor(1, 3, 32, 32) print('cifar10_version_shape =',features2(test2).shape) |
![]()

オリジナルバージョンとCIFAR-10バージョンで、全結合に繋がる直前の画像サイズを比較するコードです。もくろみ通りオリジナルは6*6、CIFAR-10は4*4 になっています。
後は、全結合層の nn.Linear(256 * 6 * 6, 4096) → nn.Linear(256 * 4 * 4, 4096) に変更し、接続の x = x.view(x.size(0), 256 * 6 * 6) → x = x.view(x.size(0), 256 * 4 * 4) に変更すればOKです。
以下に全体のコードを記載します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 |
import torch import torchvision import torch.nn as nn import torch.nn.init as init import torch.optim as optim import torch.nn.functional as F import torchvision.transforms as transforms import numpy as np from matplotlib import pyplot as plt # load CIFA-10 data train_dataset = torchvision.datasets.CIFAR10( root='./data/', train=True, transform=transforms.ToTensor(), download=True) test_dataset = torchvision.datasets.CIFAR10( root='./data/', train=False, transform=transforms.ToTensor(), download=True) print ('train_dataset = ', len(train_dataset)) print ('test_dataset = ', len(test_dataset)) image, label = train_dataset[0] print (image.size()) # set data loadser train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=64, shuffle=True, num_workers=2) test_loader = torch.utils.data.DataLoader( dataset=test_dataset, batch_size=64, shuffle=False, num_workers=2) # Alexnet class AlexNet(nn.Module): def __init__(self, num_classes): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), ) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 4 * 4, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = x.view(x.size(0), 256 * 4 * 4) x = self.classifier(x) return x # select device num_classes = 10 device = 'cuda' if torch.cuda.is_available() else 'cpu' net = AlexNet(num_classes).to(device) # optimizing criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4) # training num_epochs = 20 train_loss_list, train_acc_list, val_loss_list, val_acc_list = [], [], [], [] ### training for epoch in range(num_epochs): train_loss, train_acc, val_loss, val_acc = 0, 0, 0, 0 # ====== train_mode ====== net.train() for i, (images, labels) in enumerate(train_loader): images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = net(images) loss = criterion(outputs, labels) train_loss += loss.item() train_acc += (outputs.max(1)[1] == labels).sum().item() loss.backward() optimizer.step() avg_train_loss = train_loss / len(train_loader.dataset) avg_train_acc = train_acc / len(train_loader.dataset) # ====== val_mode ====== net.eval() with torch.no_grad(): for images, labels in test_loader: images = images.to(device) labels = labels.to(device) outputs = net(images) loss = criterion(outputs, labels) val_loss += loss.item() val_acc += (outputs.max(1)[1] == labels).sum().item() avg_val_loss = val_loss / len(test_loader.dataset) avg_val_acc = val_acc / len(test_loader.dataset) print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}' .format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc)) train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) val_loss_list.append(avg_val_loss) val_acc_list.append(avg_val_acc) # plot graph plt.figure() plt.plot(range(num_epochs), train_loss_list, color='blue', linestyle='-', label='train_loss') plt.plot(range(num_epochs), val_loss_list, color='green', linestyle='--', label='val_loss') plt.legend() plt.xlabel('epoch') plt.ylabel('loss') plt.title('Training and validation loss') plt.grid() plt.figure() plt.plot(range(num_epochs), train_acc_list, color='blue', linestyle='-', label='train_acc') plt.plot(range(num_epochs), val_acc_list, color='green', linestyle='--', label='val_acc') plt.legend() plt.xlabel('epoch') plt.ylabel('acc') plt.title('Training and validation accuracy') plt.grid() |
コード全体です。このままノートパソコンで動かすには、ちょっと重過ぎですので、今回は Google Colab のGPUを使ってみます。
|
1 2 3 4 |
!pip install torch==1.0.0 !pip install torchvision==0.2.1 |
Google Colabで、Python3 の新しいノートブックを開いて、ランタイムをGPUにしたら、このコードを入力しPyTorchをインストールします。後は、先程のコードをコピペして実行するだけです。
それにしても、WebでGPU環境が無料で手に入るなんて、素晴らしい時代になったものです。


学習結果です。20epochで、約80%の識別精度に到達しました。
PyTorchは昨年末に、待望のVer1.0がStableになり脂がのった状態になって来ました。Webでググると様々な情報があって楽しそうです。今年、PyTorchさらに大きな広がりを見せそうな予感がします。
では、また。