

今回は、生成するクラスのコントロールが可能な Conditional GAN をやってみたいと思います。
こんにちは cedro です。
先回、LSGANをやってみて、その学習安定性に驚きました。ただ、LSGANは自分の生成したいクラスを指定することは出来ません。
CelebAのデータで言えば、 ランダムベクトルの入力に対して、 ブロンドの女性が出て来るか、黒髪の男性が出てくるか、メガネを掛けているのかいないのか、は成り行きです。
つまり生成するクラスはコントロールできません。そこで、生成するクラスをコントロールする機能を加えたGANの登場です。
ということで、今回は、生成するクラスのコントロールが可能な Conditional GAN をやってみたいと思います。
Conditional GANの仕組み

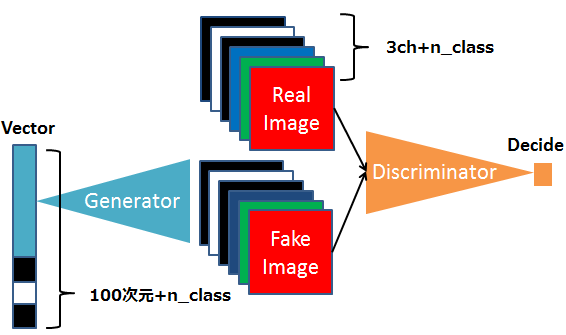
これが、Conditional GAN が学習する時の概念図です。n_class = 3 で、ラベル番号1の画像を学習する時を想定しています。
ランダムベクトル入力には、ラベル番号1をOne-Hot形式にした [ 0 , 1, 0 ] を加算します。 その結果、ランダムベクトル入力は 100次元+3 = 103 次元となります。
画像の方は、ラベル番号1をOne-Hot形式にした [ 0, 1, 0 ] を、さらに画像のサイズに拡大します。0だけで埋まった64×64の画像(真っ黒な画像)と1だけで埋まった64×64の画像(真っ白な画像)を作って、チャンネルに追加します。従って、 3ch +3 = 6 ch となります。
このような形で、画像を学習する時に、ラベル情報も合わせて学習することで、学習後は、Generator のランダムベクトル入力に、指定したラベル番号を付加することで、生成画像のクラスのコントロールが可能になります。
コードで書いてみる
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# traning loop for epoch in range(n_epoch): for itr, data in enumerate(dataloader): real_image = data[0].to(device) # 本物画像 real_label = data[1].to(device) # 本物画像のラベル real_image_label = concat_image_label(real_image, real_label, device) # 本物画像とラベルを連結 sample_size = real_image.size(0) noise = torch.randn(sample_size, nz, 1, 1, device=device) # ランダムベクトル生成(ノイズ) fake_label = torch.randint(7, (sample_size,), dtype=torch.long, device=device) # 偽物画像のラベル fake_noise_label = concat_noise_label(noise, fake_label, device) # ランダムベクトルとラベルを連結 real_target = torch.full((sample_size,), 1., device=device) fake_target = torch.full((sample_size,), 0., device=device) #---------- Update Discriminator ----------- netD.zero_grad() output = netD(real_image_label) errD_real = criterion(output, real_target) D_x = output.mean().item() fake_image = netG(fake_noise_label) # Generatorが生成した偽物画像 fake_image_label = concat_image_label(fake_image, fake_label, device) # 偽物画像とラベルを連結 output = netD(fake_image_label.detach()) errD_fake = criterion(output, fake_target) D_G_z1 = output.mean().item() errD = errD_real + errD_fake errD.backward() optimizerD.step() #---------- Update Generator ------------- netG.zero_grad() output = netD(fake_image_label) errG = criterion(output, real_target) errG.backward() D_G_z2 = output.mean().item() |
学習ループのところです。基本的にLSGANと同じで、ランダムベクトル、本物画像、偽物画像、それぞれにラベルの情報を加算する部分だけを追加します。なお、One-Hot形式への変換 、画像とラベルの連結、ランダムベクトルとラベルの連結 は、関数を呼び出して使っています。
データセットを準備する
データセットは、CelebAから 属性ファイルを使って 抽出します。ブログ「CelebA データセットから好みのデータセットを抽出する」を参照下さい。


今回の抽出条件がこれです。フォルダー0~6まで7つのクラスを設定します。やっぱり見たいのは女性の顔なので、女性限定で、髪の色、笑っているかいないかで分けて、最後にメガネを掛けている人(これは性別・髪の色・笑顔かどうか不問)を加えています。
ルートに、celeba フォルダーを作成し、その下に0~6のフォルダーを置きます。先程の条件で画像を抽出しながら、センターから160×160でクロップし、128×128にリサイズしたものを各フォルダーへ順次格納します。
各フォルダーで枚数がバラツキますので、10,000枚で揃えます(画像枚数が不揃いだと画像生成が上手く行かないようです)。
動かしてみます

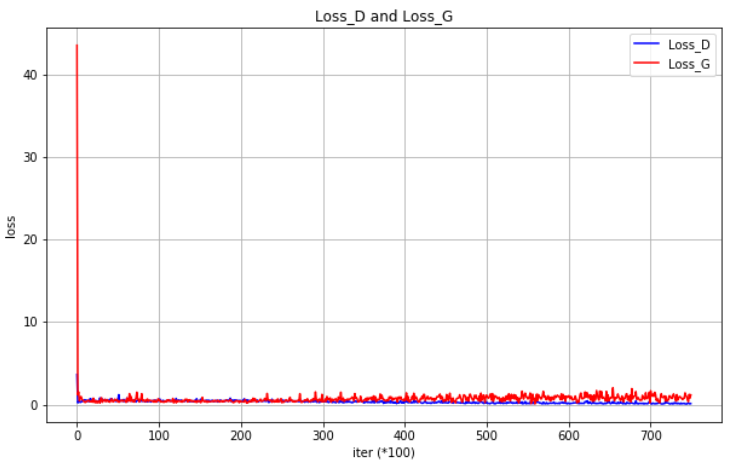
ロス推移グラフです。LSGAN同様、学習安定性は非常に高いです。 70,000枚の画像、batch_size49、50 epochをGTX1060 で学習させるのに、2時間強かかりました。


1 epoch 毎に生成した fake_image をGIF動画にしたものです。fake_imageを生成するランダムベクトルには、適切なラベル情報(0~6の繰り返し)を加えています。
その結果、左から縦2列が黒髪の女性(笑っている、いない)、次の縦2列がブロンドの女性(笑っている、いない)、その次の縦2列がブラウンの女性(笑っている、いない)、そして一番右1列がメガネを掛けた人、という様に、狙ったクラスの画像生成が出来ていることが分かると思います。
狙ったクラスだけの画像を生成できるのは、中々興味深いですね。最後に、コード全体を載せておきます。
では、また。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 |
import os import random import numpy as np import torch.nn as nn import torch.optim as optim import torch.utils.data import torchvision.datasets as dset import torchvision.transforms as transforms import torchvision.utils as vutils import matplotlib.pyplot as plt # グラフ作成用ライブラリー # Initial setting workers = 2 batch_size = 49 nz = 100 nch_g = 64 nch_d = 64 n_epoch = 50 lr = 0.0002 beta1 = 0.5 outf = './result_cgan' display_interval = 100 plt.rcParams['figure.figsize'] = 10, 6 # グラフの大きさ指定 try: os.makedirs(outf) except OSError: pass random.seed(0) np.random.seed(0) torch.manual_seed(0) def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) m.bias.data.fill_(0) elif classname.find('Linear') != -1: m.weight.data.normal_(0.0, 0.02) m.bias.data.fill_(0) elif classname.find('BatchNorm') != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) class Generator(nn.Module): def __init__(self, nz=100, nch_g=64, nch=3): super(Generator, self).__init__() self.layers = nn.ModuleDict({ 'layer0': nn.Sequential( nn.ConvTranspose2d(nz, nch_g * 8, 4, 1, 0), nn.BatchNorm2d(nch_g * 8), nn.ReLU() ), # (100, 1, 1) -> (512, 4, 4) 'layer1': nn.Sequential( nn.ConvTranspose2d(nch_g * 8, nch_g * 4, 4, 2, 1), nn.BatchNorm2d(nch_g * 4), nn.ReLU() ), # (512, 4, 4) -> (256, 8, 8) 'layer2': nn.Sequential( nn.ConvTranspose2d(nch_g * 4, nch_g * 2, 4, 2, 1), nn.BatchNorm2d(nch_g * 2), nn.ReLU() ), # (256, 8, 8) -> (128, 16, 16) 'layer3': nn.Sequential( nn.ConvTranspose2d(nch_g * 2, nch_g, 4, 2, 1), nn.BatchNorm2d(nch_g), nn.ReLU() ), # (128, 16, 16) -> (64, 32, 32) 'layer4': nn.Sequential( nn.ConvTranspose2d(nch_g, nch, 4, 2, 1), nn.Tanh() ) # (64, 32, 32) -> (3, 64, 64) }) def forward(self, z): for layer in self.layers.values(): z = layer(z) return z class Discriminator(nn.Module): def __init__(self, nch=3, nch_d=64): super(Discriminator, self).__init__() self.layers = nn.ModuleDict({ 'layer0': nn.Sequential( nn.Conv2d(nch, nch_d, 4, 2, 1), nn.LeakyReLU(negative_slope=0.2) ), # (3, 64, 64) -> (64, 32, 32) 'layer1': nn.Sequential( nn.Conv2d(nch_d, nch_d * 2, 4, 2, 1), nn.BatchNorm2d(nch_d * 2), nn.LeakyReLU(negative_slope=0.2) ), # (64, 32, 32) -> (128, 16, 16) 'layer2': nn.Sequential( nn.Conv2d(nch_d * 2, nch_d * 4, 4, 2, 1), nn.BatchNorm2d(nch_d * 4), nn.LeakyReLU(negative_slope=0.2) ), # (128, 16, 16) -> (256, 8, 8) 'layer3': nn.Sequential( nn.Conv2d(nch_d * 4, nch_d * 8, 4, 2, 1), nn.BatchNorm2d(nch_d * 8), nn.LeakyReLU(negative_slope=0.2) ), # (256, 8, 8) -> (512, 4, 4) 'layer4': nn.Conv2d(nch_d * 8, 1, 4, 1, 0) # (512, 4, 4) -> (1, 1, 1) }) def forward(self, x): for layer in self.layers.values(): x = layer(x) return x.squeeze() def onehot_encode(label, device, n_class=7): # ラベルをOne-Hoe形式に変換 eye = torch.eye(n_class, device=device) # ランダムベクトルあるいは画像と連結するために(B, c_class, 1, 1)のTensorにして戻す return eye[label].view(-1, n_class, 1, 1) def concat_image_label(image, label, device, n_class=7): # 画像とラベルを連結する B, C, H, W = image.shape # 画像Tensorの大きさを取得 oh_label = onehot_encode(label, device) # ラベルをOne-Hot形式に変換 oh_label = oh_label.expand(B, n_class, H, W) # ラベルを画像サイズに拡大 return torch.cat((image, oh_label), dim=1) # 画像とラベルをチャネル方向(dim=1)で連結 def concat_noise_label(noise, label, device): # ランダムベクトルとラベルを連結する oh_label = onehot_encode(label, device) # ラベルをOne-Hot形式に変換 return torch.cat((noise, oh_label), dim=1) # ランダムベクトルとラベルを連結 def main(): dataset = dset.ImageFolder(root='./celeba', transform=transforms.Compose([ transforms.RandomResizedCrop(64, scale=(0.9, 1.0), ratio=(1., 1.)), transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.05, contrast=0.05, saturation=0.05, hue=0.05), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])) dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=int(workers)) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print('device:', device) netG = Generator(nz=nz+7, nch_g=nch_g).to(device) # 入力ベクトルの次元は、nz+クラス数7 netG.apply(weights_init) print(netG) netD = Discriminator(nch=3+7, nch_d=nch_d).to(device) # 入力Tensorのチャネル数は、nch+クラス数7 netD.apply(weights_init) print(netD) criterion = nn.MSELoss() optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5) optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5) fixed_noise = torch.randn(batch_size, nz, 1, 1, device=device) fixed_label = [i for i in range(7)] * (batch_size // 7) # 0〜6のラベルの繰り返し fixed_label = torch.tensor(fixed_label, dtype=torch.long, device=device) fixed_noise_label = concat_noise_label(fixed_noise, fixed_label, device) Loss_D_list, Loss_G_list = [], [] # グラフ作成用リスト初期化 # traning loop for epoch in range(n_epoch): for itr, data in enumerate(dataloader): real_image = data[0].to(device) # 本物画像 real_label = data[1].to(device) # 本物画像のラベル real_image_label = concat_image_label(real_image, real_label, device) # 本物画像とラベルを連結 sample_size = real_image.size(0) # 画像枚数 noise = torch.randn(sample_size, nz, 1, 1, device=device) # ランダムベクトル生成(ノイズ) fake_label = torch.randint(7, (sample_size,), dtype=torch.long, device=device) # 偽物画像のラベル fake_noise_label = concat_noise_label(noise, fake_label, device) # ランダムベクトルとラベルを連結 real_target = torch.full((sample_size,), 1., device=device) fake_target = torch.full((sample_size,), 0., device=device) #---------- Update Discriminator ----------- netD.zero_grad() output = netD(real_image_label) errD_real = criterion(output, real_target) D_x = output.mean().item() fake_image = netG(fake_noise_label) # Generatorが生成した偽物画像 fake_image_label = concat_image_label(fake_image, fake_label, device) # 偽物画像とラベルを連結 output = netD(fake_image_label.detach()) errD_fake = criterion(output, fake_target) D_G_z1 = output.mean().item() errD = errD_real + errD_fake errD.backward() optimizerD.step() #---------- Update Generator ------------- netG.zero_grad() output = netD(fake_image_label) errG = criterion(output, real_target) errG.backward() D_G_z2 = output.mean().item() optimizerG.step() if itr % display_interval == 0: print('[{}/{}][{}/{}] Loss_D: {:.3f} Loss_G: {:.3f} D(x): {:.3f} D(G(z)): {:.3f}/{:.3f}' .format(epoch + 1, n_epoch, itr + 1, len(dataloader), errD.item(), errG.item(), D_x, D_G_z1, D_G_z2)) Loss_D_list.append(errD.item()) # Loss_Dデータ蓄積 (グラフ用) Loss_G_list.append(errG.item()) # Loss_Gデータ蓄積 (グラフ用) if epoch == 0 and itr == 0: vutils.save_image(real_image, '{}/real_samples.png'.format(outf), normalize=True, nrow=7) # --------- save fake image ---------- fake_image = netG(fixed_noise_label) vutils.save_image(fake_image.detach(), '{}/fake_samples_epoch_{:03d}.png'.format(outf, epoch + 1), normalize=True, nrow=7) # --------- save model ---------- if (epoch + 1) % 10 == 0: torch.save(netG.state_dict(), '{}/netG_epoch_{}.pth'.format(outf, epoch + 1)) torch.save(netD.state_dict(), '{}/netD_epoch_{}.pth'.format(outf, epoch + 1)) # グラフ作成 plt.figure() plt.plot(range(len(Loss_D_list)), Loss_D_list, color='blue', linestyle='-', label='Loss_D') plt.plot(range(len(Loss_G_list)), Loss_G_list, color='red', linestyle='-', label='Loss_G') plt.legend() plt.xlabel('iter (*100)') plt.ylabel('loss') plt.title('Loss_D and Loss_G') plt.grid() plt.savefig('Loss_graph.png') if __name__ == '__main__': main() |