

今回は、フレームワークの「Hello world 」であるMLPを使って、PyTorch の特徴をみてみます。
こんにちは cedro です。
年末に、本屋で「PyTorch ニューラルネットワーク実装ハンドブック」という新刊本を見かけて、何となく気になりました。


後で、Webで調べてみると、PyTorch が中々魅力的なフレームワークなことが分かりました。特徴は3つ、
1)Tensorflow より簡潔にコードが書け、それでいて細かな操作ができるらしい
2)研究者に人気があり、論文発表後に、すぐ実装例がGithubに上がことが多いらしい
3)コミュニティが活発でネット上に参考資料が豊富にあるらしい
特に気に入ったのが、2)の最新の論文の実装が手に入る点で、これはとても刺激的です。今まで、Keras を極めようと思っていた気持ちは何処へやら、もうPyTorch の魔力にかかり、大晦日にこの本を買って帰りました。
ということで、今回は、フレームワークの「Hello world 」であるMLPを使って、PyTorch の特徴をみてみます。
PyTorch のインストール
まず、PyTorch をインストールするために、PyTorch のホームページに行きます。

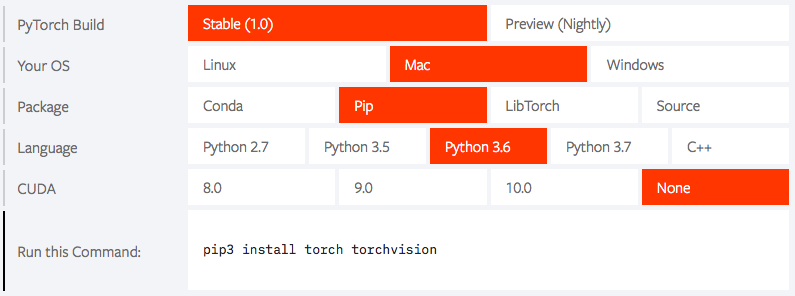
自分のインストールしたい組み合わせを赤色で選ぶと、どういうコマンドでインストールすれば良いかが一目で分かります。特に、GPUを使う場合にCUDAのどのバージョンを使うのかを指定してインストールできるのが、安心です。
ちょっと前までは、Ver0.4がStable(安定板)だったのに、もうVer1.0がStableになっていますね。

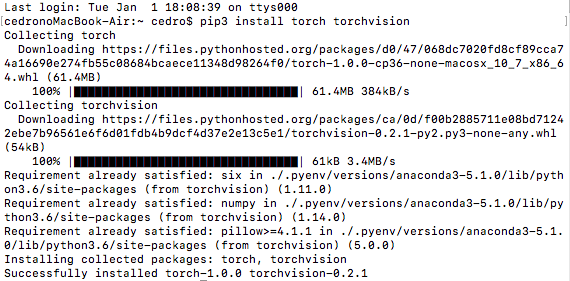
私は、先程の画面で選んだ組み合わせから示されたコマンド、pip3 install torch torchvison でインストールしました。
MLP_MNISTのコードを順に見て行きます
まずは、MLPでMNISTの分類をするコードを順番に見て行きましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import torchvision.datasets as dsets import torchvision.transforms as transforms # load MNIST data train_Dataset = dsets.MNIST( root='./data_mnist/', # rootで指定したフォルダーを作成して生データを展開 train=True, # 学習かテストかの選択 transform=transforms.ToTensor(), # PyTroch のテンソルに変換 download=True) # ダウンロードするかどうかの選択 test_dataset = dsets.MNIST( root='./data_mnist/', train=False, transform=transforms.ToTensor(), download=True) train_dataset, valid_dataset = torch.utils.data.random_split( # データセットの分割 train_Dataset, # 分割するデータセット [48000, 12000]) # 分割数 print('train_dataset = ', len(train_dataset)) print('valid_dataset = ', len(valid_dataset)) print('test_dataset = ', len(test_dataset)) |
データセットを読み込む部分です。Keras でMNISTを読み込む時は、(x_train, y_train), (x_test, y_test)= mnist.load_data() と1行で読めるので一見簡単にみえます。しかし、その後、型を変えたり、正規化したり、ラベルをOne_hotにしたりと、バラバラと色々な処理が必要です。
PyTorch の場合は、データセットを読み込む時に、transform = transforms.ToTensor() と引数で指定しておくだけで、その後の処理を自動で行ってくれますし、そもそもラベルをOne_hotにする必要がありません。しかも、データセットを数値とラベルに分けずにまとめて処理できるので、非常にすっきりします。
もちろん、データセットをそのまま分割する、torch.utils.data.random_split というのがあります。ここでは、train_Dataset(60000個) をさらに、train_dataset(48000個) とvalid_dataset(12000個) に分割しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# set data loader train_loader = torch.utils.data.DataLoader( dataset=train_dataset, # データセットの指定 batch_size=64, # ミニバッチの指定 shuffle=True, # シャッフルするかどうかの指定 num_workers=2) # コアの数 valid_loader = torch.utils.data.DataLoader( dataset=valid_dataset, batch_size=64, shuffle=False, num_workers=2) test_loader = torch.utils.data.DataLoader( dataset=test_dataset, batch_size=64, shuffle=False, num_workers=2) |
データローダの部分です。データセットからミニバッチ単位でデータを取り出し、ネットワークへ供給することが出来ます。シンプルで分かりやすいです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Multi Layer Perceptron Network class MLPNet (nn.Module): def __init__(self): super(MLPNet, self).__init__() self.fc1 = nn.Linear(28 * 28 * 1, 512) self.fc2 = nn.Linear(512, 512) self.fc3 = nn.Linear(512, 10) self.dropout1 = nn.Dropout2d(0.2) self.dropout2 = nn.Dropout2d(0.2) def forward(self, x): x = F.relu(self.fc1(x)) x = self.dropout1(x) x = F.relu(self.fc2(x)) x = self.dropout2(x) return F.relu(self.fc3(x)) # select device device = 'cuda' if torch.cuda.is_available() else 'cpu' net = MLPNet().to(device) # optimizing criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4) |
ネットワークを構築する部分です。まず、MLPNetクラスでネットワークを定義しています。ネットワークの記述には、色々な方法があるみたいですが、これは nn.Moduleを継承した記法で、前半にブロックを書いて、後半に接続を書いています。
後は、デバイス(GPUかCPU)を選択して、損失関数と最適化関数を設定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
### training print ('training start ...') num_epochs = 50 # initialize list for plot graph after training train_loss_list, train_acc_list, val_loss_list, val_acc_list = [], [], [], [] for epoch in range(num_epochs): # initialize each epoch train_loss, train_acc, val_loss, val_acc = 0, 0, 0, 0 # ======== train_mode ====== net.train() for i, (images, labels) in enumerate(train_loader): # ミニバッチ回数実行 #viewで28×28×1画像を1次元に変換し、deviceへ転送 images, labels = images.view(-1, 28*28*1).to(device), labels.to(device) optimizer.zero_grad() # 勾配リセット outputs = net(images) # 順伝播の計算 loss = criterion(outputs, labels) # lossの計算 train_loss += loss.item() # train_loss に結果を蓄積 acc = (outputs.max(1)[1] == labels).sum() # 予測とラベルが合っている数の合計 train_acc += acc.item() # train_acc に結果を蓄積 loss.backward() # 逆伝播の計算 optimizer.step() # 重みの更新 avg_train_loss = train_loss / len(train_loader.dataset) # lossの平均を計算 avg_train_acc = train_acc / len(train_loader.dataset) # accの平均を計算 # ======== valid_mode ====== net.eval() with torch.no_grad(): # 必要のない計算を停止 for images, labels in valid_loader: images, labels = images.view(-1, 28*28*1).to(device), labels.to(device) outputs = net(images) loss = criterion(outputs, labels) val_loss += loss.item() acc = (outputs.max(1)[1] == labels).sum() val_acc += acc.item() avg_val_loss = val_loss / len(valid_loader.dataset) avg_val_acc = val_acc / len(valid_loader.dataset) # print log print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}' .format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc)) # append list for polt graph after training train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) val_loss_list.append(avg_val_loss) val_acc_list.append(avg_val_acc) |
学習部分です。ここは、細かな記述が必要ですが、こうなっているからこそ、複雑なネットワークを試す時に、細かくデバッグができるわけですね。
train_mode とvalid_mode に分けているのは、Dropout や BatchNomalization などの学習の時には効かせて、評価の時には効かせないブロックがあるためです。
ログの出力や後でグラフを描かせるためのデータ保持をする部分があり、ここはもうちょっと簡略化しても良い気もしますが、まあ良いでしょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# ======== fainal test ====== net.eval() with torch.no_grad(): total = 0 test_acc = 0 for images, labels in test_loader: images, labels = images.view(-1, 28 * 28 * 1 ).to(device), labels.to(device) outputs = net(images) test_acc += (outputs.max(1)[1] == labels).sum().item() total += labels.size(0) print('test_accuracy: {} %'.format(100 * test_acc / total)) # save weights torch.save(net.state_dict(), 'mnist_net.ckpt') # plot graph import matplotlib.pyplot as plt plt.figure() plt.plot(range(num_epochs), train_loss_list, color='blue', linestyle='-', label='train_loss') plt.plot(range(num_epochs), val_loss_list, color='green', linestyle='--', label='val_loss') plt.legend() plt.xlabel('epoch') plt.ylabel('loss') plt.title('Training and validation loss') plt.grid() plt.figure() plt.plot(range(num_epochs), train_acc_list, color='blue', linestyle='-', label='train_acc') plt.plot(range(num_epochs), val_acc_list, color='green', linestyle='--', label='val_acc') plt.legend() plt.xlabel('epoch') plt.ylabel('acc') plt.title('Training and validation accuracy') plt.grid() |
学習後の部分です。テストデータセットを使って、モデルの最終的な精度を計算します。その後、学習した重みファイルを保存し、ロスと精度の推移グラフを描きます。
とりあえず、動かしてみましょう。

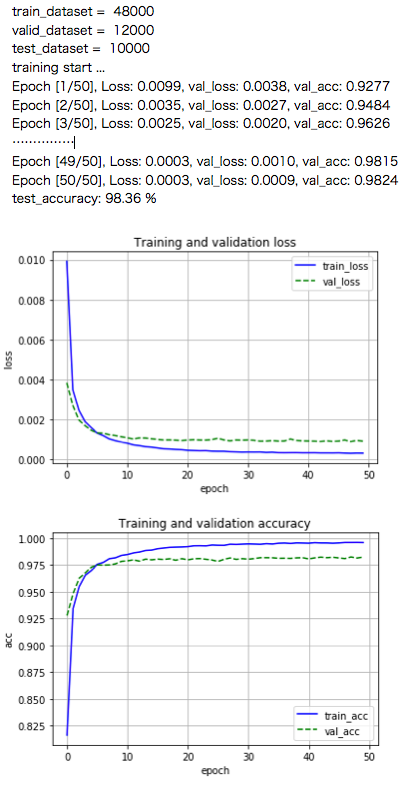
50epoch後にテストデータを使って計測した精度は Test_accuracy = 98.36%でした。
オリジナルデータを読み込んでみる
あらかじめ用意されたデータセットは簡単に読み込めて当たり前です。問題は、オリジナルデータを読み込む場合がどうかが重要です。ここでは、具体的なオリジナルデータを読み込んでみます。

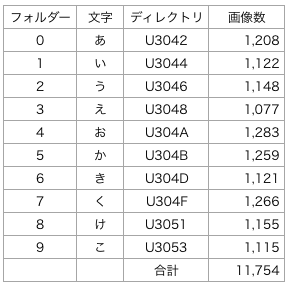
今回用意したデータは、NDL Lab の平仮名73文字から「あ、い、う、え、お、か、き、く、け、こ」の10種類を抜き出したものです。たぶん、オリジナルデータの典型的な形ではないでしょうか。
各文字の画像数は1,200枚前後で、で合計11,754枚。各画像は、カラー48×48ピクセルのPNG形式です。

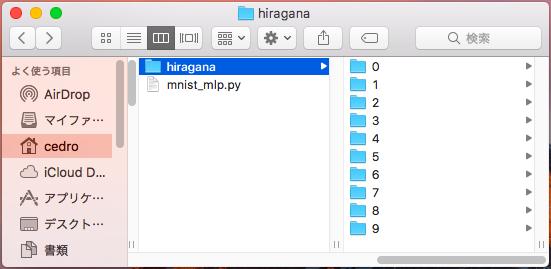
root に、hiragana フォルダーを置いて、その下に0〜9のフォルダーを作成し、「あ」〜「こ」の文字画像を格納します。PyTorch では、このデータをどうやって読み込むかと言うと、
|
1 2 3 4 5 6 7 8 9 10 11 |
# load original dataset data_transform = transforms.Compose([ # データ変換する内容を列挙 transforms.Resize((28, 28)), # 48*48 から 28*28 にリサイズ transforms.Grayscale(1), # カラーからグレースケールに変換 transforms.ToTensor()]) # PyTorch 指定のテンソルに変換 hiragana_dataset = dsets.ImageFolder( root = './hiragana', # 親フォルダーの指定 transform = data_transform) # データ変換の指定 |
データの読み込は、実質8–10行目のたった3行だけです。これだけで、0〜9のフォルダー名をラベルとして認識し、データセットとして読み込みます。ふと思い出しましたが、これって、SONY Neural Network Console の画像データを読み込んでデータセットを作成する場合と同じですね。凄く懐かしい。
そして、データに何らかの前処理を加えたい場合は、その内容を3−6行目の様に transforms_Comose で列挙しておけば、前処理も一気にやってくれます。これは便利!
では、実際にオリジナルデータを読み込んで表示させてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import torchvision.datasets as dsets import torchvision.transforms as transforms import torchvision import numpy as np import matplotlib.pyplot as plt data_transform = transforms.Compose([ transforms.Resize((28, 28)), transforms.Grayscale(1), transforms.ToTensor()]) hiragana_dataset = dsets.ImageFolder( root = './hiragana', transform = data_transform) train_dataset, test_dataset = torch.utils.data.random_split( hiragana_dataset, [9754, 2000]) train_dataset, valid_dataset = torch.utils.data.random_split( train_dataset, [8000, 1754]) print('train_dataset = ', len(train_dataset)) print('valid_dataset = ', len(valid_dataset)) print('test_dataset = ', len(test_dataset)) # set data loader train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=64, shuffle=True, num_workers=2) valid_loader = torch.utils.data.DataLoader( dataset=valid_dataset, batch_size=64, shuffle=True, num_workers=2) test_loader = torch.utils.data.DataLoader( dataset=test_dataset, batch_size=64, shuffle=False, num_workers=2) # make_images_grid images, labels = iter(train_loader) .next() # train_loader のミニバッチの image を取得 img = torchvision.utils.make_grid(images, nrow=8, padding=1) # nrom*nrom のタイル形状の画像を作る plt.imshow(np.transpose(img.numpy(), (1, 2, 0))) # 画像を matplotlib 用に変換 plt.show() # check image.shape and label print ('images[0].shape = ',images[0].shape) print ('labels[0] = ',labels[0]) |
オリジナルデータを読み込んで、データセットとデータローダを作り、内容を確認するコードです。
まず、データに必要な前処理を加えて読み込み hiragana_dataset を作り、troch.utils.random_split で train_dataset, valid_dataset, test_dataset に分割し、それぞれデータローダ(これは先程と同じ)を作成します。そして、最後に train_dataset のimageを8×8のタイル状に表示させ、シェイプ等を確認します。
54行目の torchvision.utils.make_grid が優れもので、ミニバッチの画像入力を受け取って、N*Nのタイル状の画像を自動で作ってくれます。今回の様に入力画像の確認に使っても良いですし、特に生成系の画像の出力には重宝しそうです。
59-60行目は train_loaderのimagesの先頭のシェイプとlabels の先頭のデータを確認する部分です。
では、コードを動かしてみます。


作成したデータセットが狙い通りになっているのか、train_loader のミニバッチ画像を可視化して確認が出来ます。これ、地味に嬉しくないですか。
そして、imagesの先頭のシェイプは troch.Size( [1, 28, 28] ) 、labelの先頭は tensor(7) で、可視化した画像の左角の「く」のフォルダー名「7」と合っていますね。
それでは、改造したMLP全体のコードを動かしてみます。


20epoch後にテストデータを使って計測した精度は Test_accuracy = 99.4% でした。ひらがなのデータセットは、MNISTより簡単なようです。
今回、初めてPyTorchに触ってみたわけですが、メリハリが効いた良いフレームワークだなという感じがします。
データセットを読み込むとか、画像をタイル形状で表示するとか、開発に直接関係ないが良く使う部分は高度に自動化してある一方で、ネットワークを構築するとか、学習・評価するとか、開発に直接関係する部分は細かく記述出来るようになっていて、非常に好印象です。
しばらく、PyTorch を中心に触ってみて、早く慣れたいと思います。最後に mlp_mnist.py の全体のコードを載せておきます。
では、また。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 |
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import torchvision.datasets as dsets import torchvision.transforms as transforms # load MNIST data train_Dataset = dsets.MNIST( root='./data_mnist/', # rootで指定したフォルダーを作成して生データを展開 train=True, # 学習かテストかの選択 transform=transforms.ToTensor(), # PyTroch のテンソルに変換 download=True) # ダウンロードするかどうかの選択 test_dataset = dsets.MNIST( root='./data_mnist/', train=False, transform=transforms.ToTensor(), download=True) train_dataset, valid_dataset = torch.utils.data.random_split( # データセットの分割 train_Dataset, # 分割するデータセット [48000, 12000]) # 分割数 print('train_dataset = ', len(train_dataset)) print('valid_dataset = ', len(valid_dataset)) print('test_dataset = ', len(test_dataset)) # set data loader train_loader = torch.utils.data.DataLoader( dataset=train_dataset, # データセットの指定 batch_size=64, # ミニバッチの指定 shuffle=True, # シャッフルするかどうかの指定 num_workers=2) # コアの数 valid_loader = torch.utils.data.DataLoader( dataset=valid_dataset, batch_size=64, shuffle=False, num_workers=2) test_loader = torch.utils.data.DataLoader( dataset=test_dataset, batch_size=64, shuffle=False, num_workers=2) # Multi Layer Perceptron Network class MLPNet (nn.Module): def __init__(self): super(MLPNet, self).__init__() self.fc1 = nn.Linear(28 * 28 * 1, 512) self.fc2 = nn.Linear(512, 512) self.fc3 = nn.Linear(512, 10) self.dropout1 = nn.Dropout2d(0.2) self.dropout2 = nn.Dropout2d(0.2) def forward(self, x): x = F.relu(self.fc1(x)) x = self.dropout1(x) x = F.relu(self.fc2(x)) x = self.dropout2(x) return F.relu(self.fc3(x)) # select device device = 'cuda' if torch.cuda.is_available() else 'cpu' net = MLPNet().to(device) # optimizing criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4) ### training print ('training start ...') num_epochs = 50 # initialize list for plot graph after training train_loss_list, train_acc_list, val_loss_list, val_acc_list = [], [], [], [] for epoch in range(num_epochs): # initialize each epoch train_loss, train_acc, val_loss, val_acc = 0, 0, 0, 0 # ======== train mode ====== net.train() for i, (images, labels) in enumerate(train_loader): # ミニバッチ回数実行 #viewで28×28×1画像を1次元に変換し、deviceへ転送 images, labels = images.view(-1, 28*28*1).to(device), labels.to(device) optimizer.zero_grad() # 勾配リセット outputs = net(images) # 順伝播の計算 loss = criterion(outputs, labels) # lossの計算 train_loss += loss.item() # train_loss に結果を蓄積 acc = (outputs.max(1)[1] == labels).sum() # 予測とラベルが合っている数の合計 train_acc += acc.item() # train_acc に結果を蓄積 loss.backward() # 逆伝播の計算 optimizer.step() # 重みの更新 avg_train_loss = train_loss / len(train_loader.dataset) # lossの平均を計算 avg_train_acc = train_acc / len(train_loader.dataset) # accの平均を計算 # ======== valid mode ====== net.eval() with torch.no_grad(): # 必要のない計算を停止 for images, labels in valid_loader: images, labels = images.view(-1, 28*28*1).to(device), labels.to(device) outputs = net(images) loss = criterion(outputs, labels) val_loss += loss.item() acc = (outputs.max(1)[1] == labels).sum() val_acc += acc.item() avg_val_loss = val_loss / len(valid_loader.dataset) avg_val_acc = val_acc / len(valid_loader.dataset) # print log print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}' .format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc)) # append list for polt graph after training train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) val_loss_list.append(avg_val_loss) val_acc_list.append(avg_val_acc) # ======== fainal test ====== net.eval() with torch.no_grad(): total = 0 test_acc = 0 for images, labels in test_loader: images, labels = images.view(-1, 28 * 28 * 1 ).to(device), labels.to(device) outputs = net(images) test_acc += (outputs.max(1)[1] == labels).sum().item() total += labels.size(0) print('test_accuracy: {} %'.format(100 * test_acc / total)) # save weights torch.save(net.state_dict(), 'mnist_net.ckpt') # plot graph import matplotlib.pyplot as plt plt.figure() plt.plot(range(num_epochs), train_loss_list, color='blue', linestyle='-', label='train_loss') plt.plot(range(num_epochs), val_loss_list, color='green', linestyle='--', label='val_loss') plt.legend() plt.xlabel('epoch') plt.ylabel('loss') plt.title('Training and validation loss') plt.grid() plt.figure() plt.plot(range(num_epochs), train_acc_list, color='blue', linestyle='-', label='train_acc') plt.plot(range(num_epochs), val_acc_list, color='green', linestyle='--', label='val_acc') plt.legend() plt.xlabel('epoch') plt.ylabel('acc') plt.title('Training and validation accuracy') plt.grid() |