

1.はじめに
ご無沙汰しております、cedroです。ずいぶんと長い間、ブログの更新をお休みしていましたが、再開します。
顔画像を学習したGANモデルは、潜在変数を変化させることによって、様々な顔画像を生成出来るようになります。学習に使った顔画像の要素を色々組み合わせることによって、学習に使わなかった画像も生成することが出来るわけです。言い換えれば、顔画像を学習したGANの潜在空間には無数の顔が分布してると言うことが出来ます。
ということは、そのGANの潜在空間には、新垣結衣さんに似た顔もあるかもしれないと思ったのが、今回のテーマを考えたきっかけです。
今回は、顔画像生成の最新モデルであるStyleGAN2を使って、「GANの潜在空間に新垣結衣は住んでいるのか?」というテーマを検証してみたいと思います。
2.StyleGAN2とは?
まず、StyleGANについて簡単におさらいします。

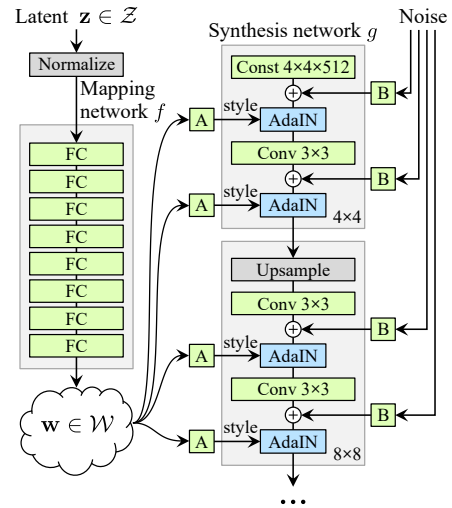
左側のMapping network は8層の全結合層で、入力の潜在変数z(1, 512)を中間出力の潜在変数w(18, 512)にマッピングします。
右側のSynthesis network は9層で、入力は定数(4×4×512)、そこへ先程の潜在変数w(18, 512)とノイズが各層に入ります。潜在変数wは、各層に2本づつ入っているので、合計9×2=18となるわけです。そして、生成する画像の解像度を、4×4, 8×8, 16×16と順次上げて行き、最終的に1024×1024にします。
潜在変数wは主な画像生成をコントロールし、ノイズは細部の特徴(髪の流れ, 肌質など)をコントロールします。
StyleGAN2は、このStyleGANの改良版なので、改良点を簡単に説明すると、
- データ正規化の手法を見直し、特徴的な水滴状パターンの発生を防止
- Progressive growingをやめ、頻出特徴を生成してしまう不具合を防止
- 潜在空間の知覚的な滑らかさを示す指標をモデルに組み込み画像品質を向上
3.新垣結衣の顔をどうみつけるか?

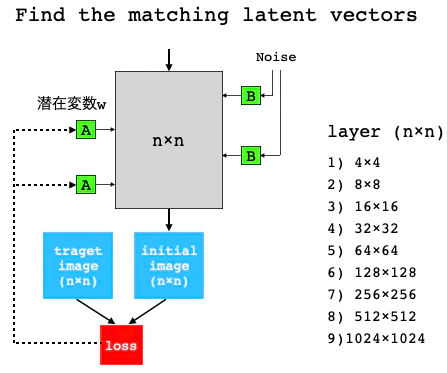
主な画像生成をコントロールするのは、潜在変数z(1, 512)あるいは潜在変数w(18, 512)です。潜在変数wの方が明らかに表現力が豊なので、潜在変数wの探索を行うことにします。
アルゴリズムは、Synthesis networkの9個ある各層において、潜在変数wを適当に初期化して inital image を出力し、target image (新垣結衣の画像)との差をロスとします。そして、ロスが出来るだけ小さくなるような潜在変数wを見つけるものです。
そのために、target image は9種類の解像度の画像(4×4〜1024×1024)を用意します。
今回使用するコードは、NVIDIAが公開しているStyleGAN2の公式コードを元に、Google Colabで動かすような形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
4.セットアップ
最初に、tensorflow1.15.0 を動かすために必要な cuda10.0 をインストールします(2022.10よりgoogle colab からcuda10.0が削除されたため)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#@title install cuda10.0 # download data !wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !sudo dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb !rm /etc/apt/sources.list.d/cuda.list !sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub !sudo apt-get update !wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt install -y ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb !sudo apt-get update # install NVIDIA driver !sudo apt-get -y installnvidia-driver-418 # install cuda10.0 !sudo apt-get install -y \ cuda-10-0 \ libcudnn7=7.6.2.24-1+cuda10.0 \ libcudnn7-dev=7.6.2.24-1+cuda10.0 # install TensorRT !sudo apt-get install -y libnvinfer5=5.1.5-1+cuda10.0 \ libnvinfer-dev=5.1.5-1+cuda10.0 !apt --fix-broken install |
まず、githubよりコードを取得します。
|
1 2 3 4 5 |
# --- githubよりコードを取得 --- !pip install tensorflow==1.15.0 !pip install keras==2.2.4 !git clone https://github.com/cedro3/stylegan2.git %cd stylegan2 |
次に、使用するクラスと関数を定義します。コードの記載は省略しますが、定義する内容だけをメモしておきます。
- class LandmarksDetector: 顔のランドマーク(目、鼻、口、顎など)検出クラス
- def image_align(): 顔画像の切り出し関数
- def unpack_bz2(): bz2ファイルを解凍する関数
- def project_real_images(): マルチ解像度データセットに出来るだけ似た画像を生成する潜在変数を探索する関数
- def generate_gif(): 2つの潜在変数からGIF動画を生成する関数
- def display_pic(): フォルダー内の画像ファイルを表示する関数
- def display(): 潜在変数の画像を表示する関数
そして、最後に顔画像を切り出すモデルの読み込みを行います。
|
1 2 3 4 |
# 顔画像切り出しモデルの読み込み LANDMARKS_MODEL_URL = 'http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2' landmarks_model_path = unpack_bz2(get_file('shape_predictor_68_face_landmarks.dat.bz2', LANDMARKS_MODEL_URL, cache_subdir='temp')) |
5.顔画像の切り出し
sample/picに用意した下記5つの画像から、顔画像を切り出します。


普通はOpenCVでやるわけですが、StyleGAN2が学習に使ったFFHQデータセットは、dlibを使いalign(顔が直立するように回転させる)して独自の設定の範囲を切り取って作成されています。なので、用意した画像から顔画像を切り出す場合も同様な処理を行います。では、下記のコードを実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 顔画像の切り出し RAW_IMAGES_DIR = 'sample/pic' ALIGNED_IMAGES_DIR = 'my/pic' landmarks_detector = LandmarksDetector(landmarks_model_path) for img_name in os.listdir(RAW_IMAGES_DIR): raw_img_path = os.path.join(RAW_IMAGES_DIR, img_name) for i, face_landmarks in enumerate(landmarks_detector.get_landmarks(raw_img_path), start=1): face_img_name = '%s_%02d.png' % (os.path.splitext(img_name)[0], i) aligned_face_path = os.path.join(ALIGNED_IMAGES_DIR, face_img_name) image_align(raw_img_path, aligned_face_path, face_landmarks) display_pic('./my/pic/*.*') |


sample/pic にある各画像について、顔のランドマーク(目、鼻、口、顎など)を検出し、その位置を合わせて顔画像を切り出し、1024×1024にリサイズしてmy/picに保存しています。
目、鼻、口、顎の位置が大体合っていることが分かると思います。これが大体合っていないと上手く潜在変数の探索が出来ないのでご注意下さい。
6.マルチ解像度データセットの作成
切り取った顔画像を9種類の解像度(4×4, 8×8, 16×16,…., 1024×1024)の画像に変換し、Tensorflowの仕様であるマルチ解像度の画像TFRecordで保存するコードです。
|
1 |
!python dataset_tool.py create_from_images ./my/dataset ./my/pic |
dataset_tool.pyを使って、my/picにある顔画像からマルチ解像度の画像TFRecordを作成し、my/datasetへ保存します。

ちなみに、マルチ解像度の画像TFRecordはこんな形をしています。
7.新垣結衣を生成する潜在変数を探索する
それでは、マルチ解像度のデータセットに登録された新垣結衣さんの顔を生成する潜在変数を探索します。
探索途中の生成画像は my/real_imagesフォルダーに順次保存されます。探索した潜在変数はvec_synで返って来ます。探索試行回数の設定値は300です。変更したい場合はprojector.py の self.num_stepsの値をエディター等で変更して下さい。では、コードを実行します。
|
1 2 3 |
vec_syn = project_real_images(5) # ()内はマルチ解像度のデータセットを作成した時の画像枚数 display_pic('./my/pic/*.*') # ターゲット画像の表示 display(vec_syn) # 探索した潜在変数によって生成した画像 |


上段がターゲット画像、下段が探索した潜在変数が生成した画像です。なぜか順番が変わってしまいました。ターゲットに対する再現性は、まずまずですが、もう一味足らないということで70点くらいの出来でしょうか。
検証結果は、「GANの潜在空間には、新垣結衣に良く似た人が住んでいた」です。
探索した潜在変数vec_synをNumpyのバイナリファイルで保存する場合は、下記のコードを実行します。
|
1 2 3 |
# 探索した潜在変数の保存 os.makedirs('my/vector', exist_ok=True) np.save('my/vector/vec_syn', vec_syn) |
ちなみに、このファイルの容量は18×512の行列が5つだけなので、たった188KBです。ふと考えてみると、この情報だけから1024×1024ピクセルのカラー画像を5枚生成出来るのは凄いことですね。
保存したNumpyのバイナリファイルを読み込みには、下記のコードを実行します。
|
1 2 |
# 探索した潜在変数の読み込み vec_syn = np.load('my/vector/vec_syn.npy') |
8.顔画像のトランジション
上手く顔画像を生成できる潜在変数を見つけることが出来ると、興味深いことが出来ます。例えば、顔画像Aを生成する潜在変数Aと顔画像Bを生成する潜在変数Bを見つけたとします。
潜在変数Aと潜在変数Bの各要素の差をn等分したものをCとし、潜在変数を A+C*1, A+C*2, …., A+C*nと変化させながら顔画像を生成すると、顔画像Aから顔画像Bへスムーズへ画像を変化させることが出来ます。
それでは、8.で見つけた潜在変数を使って、やってみましょう。generate_gif ( 潜在変数名, リスト形式で順番指定 )で実行します。
|
1 2 3 |
from IPython.display import Image generate_gif(vec_syn,[1, 0, 3]) # 潜在変数を1番目→0番目→3番目へアニメーション Image('./my/gif/anime_256.gif', format='png') |


潜在変数の1番目→0番目→3番目と少しづつ変化させた結果です。見つけた潜在変数の間にも顔画像がきれいに分布していることが分かります。
作成したGIF動画は、my/gif/ に保存されます。anime.gif は 1024×1024 のサイズ、anime_256.gif は 256×256 のサイズです。
このブログでは、新垣結衣さんを題材にしていますが、例えば自分の写っている写真を使えば自分の顔画像の潜在変数も簡単に取得することが出来ます。ぜひ、色々トライしてみて下さい。
では、また。
(Twitterへの投稿)