

今回は、VAT ( Virtual Adversarial Training ) による半教師あり学習をやってみます。
ディープラーニングは大量のラベル付きデータ(正解付きデータ)があると学習が上手く行くわけですが、大量のラベル付きデータを作成するには、かなりのコストが掛ります。
ビッグデータから大量のデータを収集することは比較的容易な訳ですが、それにいちいちラベル付けする作業が大変なのです。
そうした中で、少量のラベル付きデータと、残りは大量のラベル無しデータで学習する方法を「半教師あり学習」と言い、サンプルプロジェクトにある VAT ( Virtual Adversarial Training ) は、その中の1つです。
考えてみれば、我々も赤ちゃんの時に、「これは犬だよ」、「これは猫だよ」と教えられるわけですが、教えられるラベル付きデータはほんの少しで、後は大量のラベル無しデータを見ているうちに、犬や猫を正確に識別できるようになります。これと同じですね。
具体的な学習方法ですが、まず少量のラベル付きデータで、ラベル毎に大体の境界線を把握します。その上で、ラベル無しデータをそこにプロットし境界線の方向(一番間違えやすい方向)に少し動かすノイズを加えます。
そして、「ラベル無しデータ」と「ラベル無しデータ+ノイズ」の予測確率分布の差が最小になる様な重みwとバイアスbを学習するというものです。
サンプルプロジェクトを見てみましょう
まずは、サンプルプロジェクト semi_supervised_learning_VAT を見てみましょう。

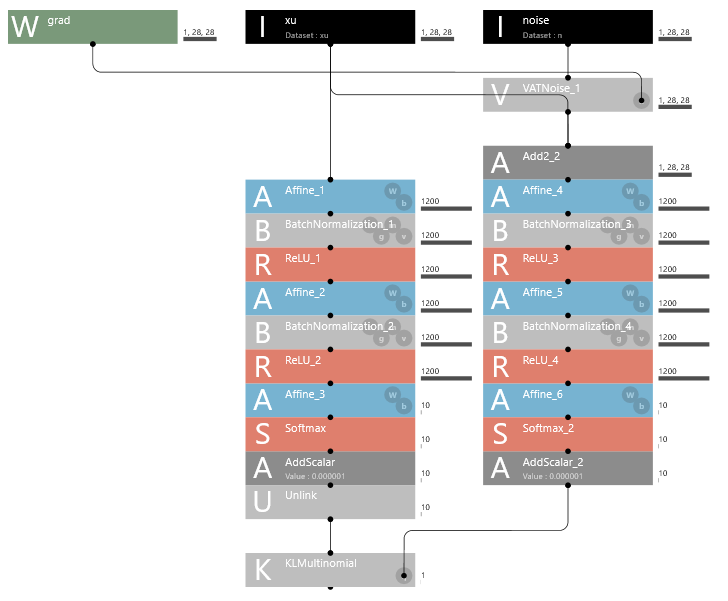
全部で6画面ありますが、これは NoiseEstimati 画面です。「ラベル無しデータ」と「ラベル無しデータ+ノイズ」の2系統の差が小さくなるように学習する雰囲気が分かると思います。
データセットは3つあり、ラベル付きデータが100個、ラベル無しデータが60,000個、評価用データが10,000個です。
但し、このままサンプルプロジェクトの学習を開始しただけでは、VATのありがたみは分かりません。
まず、ベンチマークをやってみます
まずは、ベンチマークとしてラベル付きデータが60,000個と評価用データが10,000個で学習・評価をやってみます。


使うネットワークは、VATの中で使われているこのネットワーク(実際はこれが2系統使われます)です。
全結合層(Affine)が3層だけですが、なにげにBatch Normalization を2つ噛ませて、能力UPを図っています。


バッチ64、エポック50で学習を開始します。1時間1分で学習が完了です。

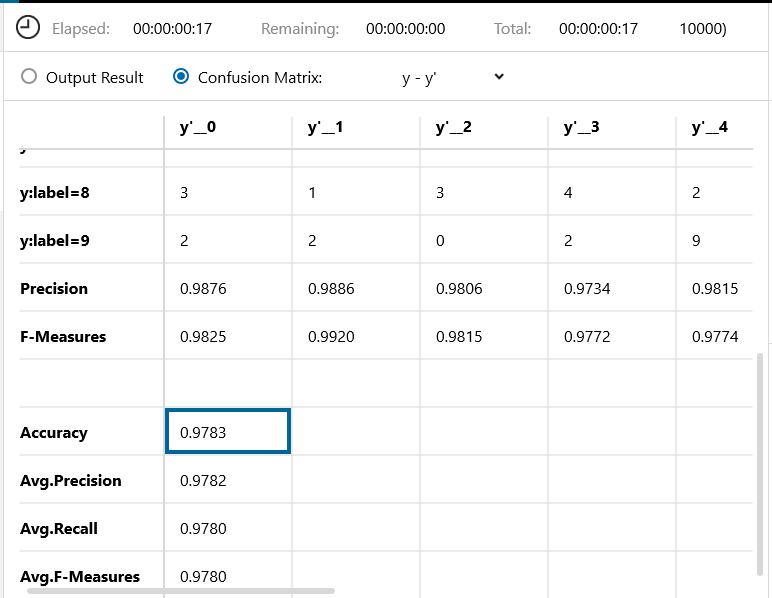
Confusion Matrix です。精度は97.83%です。
さて、今度はラベル付きデータが60,000個から100個に減らしたら、どうなるかを見てみましょう。


バッチ64、エポック100で学習を開始します。1分16秒で学習完了です。

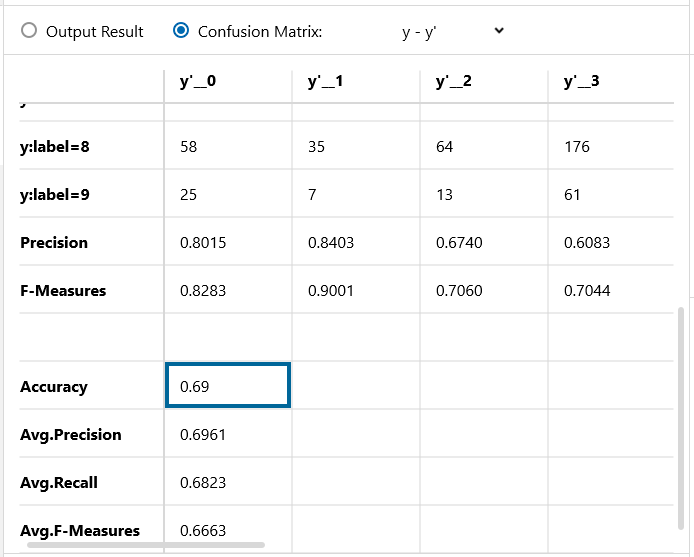
Confusion Matrix です。さすがに、学習データがたった100個では、識別精度は70%くらいが限界の様です。
いよいよ、VATの登場です
さあ、ここで、ラベル付きデータは100個しかないけれど、ラベル無しデータなら60,000個あるけど、何か上手い方法がないの? という場面で登場するのが、VATというわけです。
では、いよいよ、VATを動かしてみます。今度は、ラベル付きデータが100個、ラベル無しデータが60,000個、評価用データが10,000個 と3つのデータを使います。

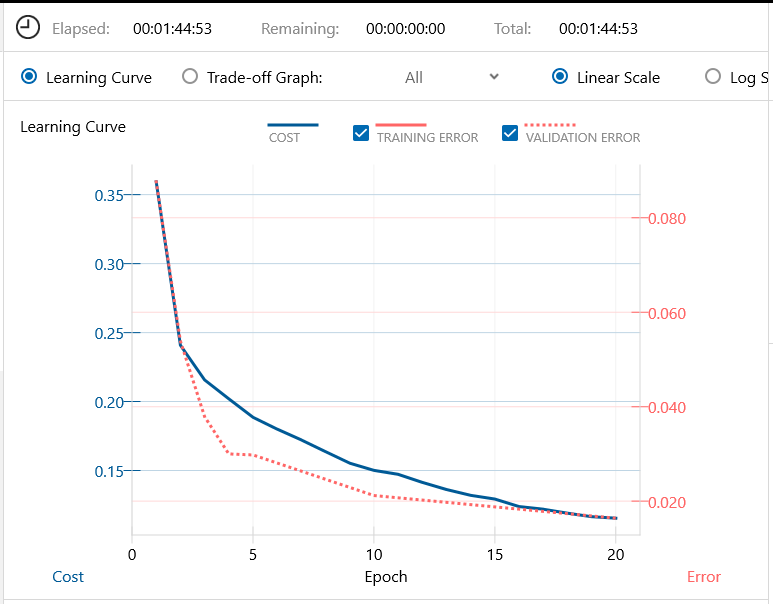
バッチ64、エポック20で学習を開始します。1時間44分で学習完了です。

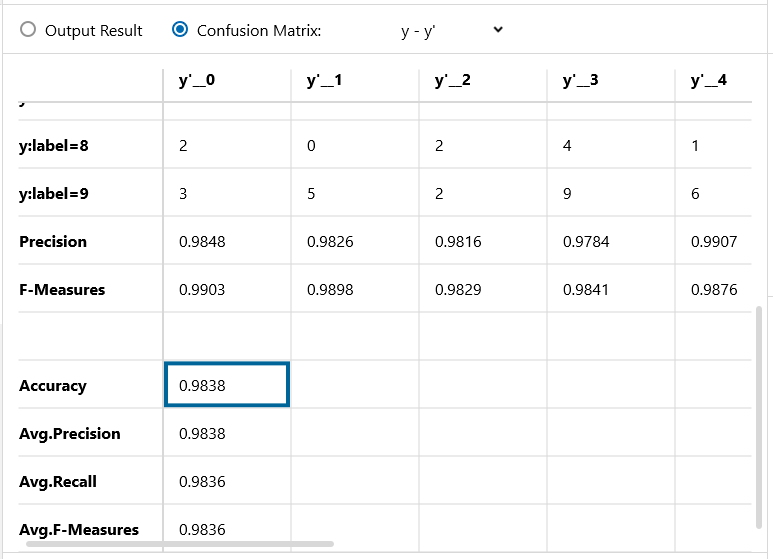
Confusion Matrix です。認識精度は 98.38% です!
驚きました、ベンチマークのラベル付きデータが60,000個と評価用データが10,000個で学習した場合よりも、識別精度が良くなってしまいました。
恐るべし、VAT!
エポック数の設定で多少識別精度がばらついたとしても、VATを使うと、大量のラベル付きデータとほぼ同じ認識精度が実現できそうです。これは、素晴らしい!
半教師あり学習って実践的だと思う
サンプルプロジェクトに「半教師あり学習」が入っているのは知っていたのですが、今回初めて動かしてみて、その威力に驚いています。
世の中には、ラベル無しデータなら大量にあるというのは、結構あるシチュエーションだと思います。
ビッグデータに限らず、例えば、医療現場では、白内障を予測するための眼底画像とその予測結果のペア(ラベル付きデータ)は中々揃わないが、眼底画像のみ(ラベル無しデータ)なら沢山蓄積されているらしいです。
こういった場合、「半教師あり学習」を使うと、白内障を予測するニューラルネットワークが作れそうですよね。
「半教師あり学習」、かなりの潜在能力を感じます。また、別の機会でも使ってみたくなりました。
では、また。