今回は、Google Colab を使って話題のStyleGANの学習済みモデルで、サクッと遊んでみたいと思います。
こんにちはcerdoです。
皆さん、StyleGANをご存じですか。最近、「写真が証拠になる時代は終わった」などと騒がれているあれです。
早速、学習済みモデルをちょっといじってみたわけですが、ランダムベクトルから生成される画像の完成度が半端なく、しかも解像度は1024×1024という高解像度で、ぱっと見るとリアルかフェイクか本当に分かりません。
さらに驚いたのは、2つのランダムベクトルの補完画像を細かく分割して見ても、実に自然な変化をするんです。
ということで、今回は、Google Colabを使って話題のStyleGANの学習済みモデルで、サクッと遊んでみたいと思います。
StyleGANとは?

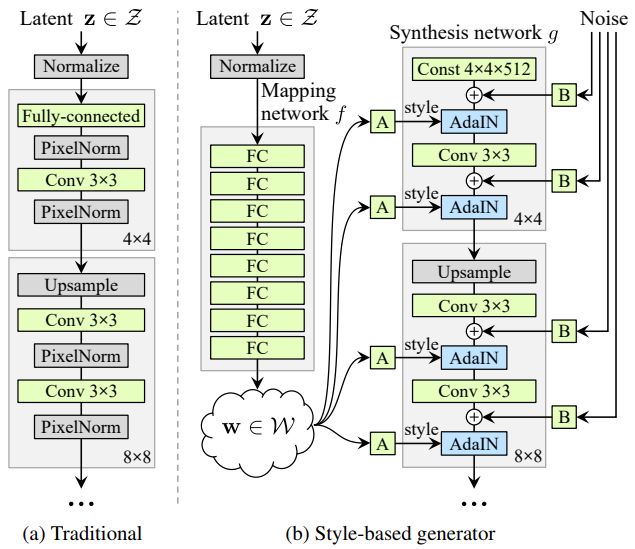
これは、(a)今までのGAN(ProgressiveGAN) と(b) StyleGANのネットワーク構造を比較した図です。StyleGANは今までとは構造をがらりと変えて、Mapping network とSynthesis network の2つで構成されています。
Mapping network は8層の全結合層から成り、潜在変数を潜在空間にマッピングします。
Synthesis networkは18層から成り、入力は4×4×512の定数で、そこへ「スタイル」(潜在変数にアフィン変換を掛けAdaIN処理を行ったもの)と
「ノイズ」が各層に入力されます。
「スタイル」が主に画像生成をコントロールし、「ノイズ」は画像の見た目に大きな影響を与えない特徴(髪質や髪の流れ、ヒゲ、そばかす、肌質など)をコントロールします。Synthesis networkの解像度は4×4から順次アップサンプリングし、最終的には1024×1024になります。
ちなみに、StyleGANの学習は、とてつもなくヘビーです。データセットは1024×1024の画像70,000枚を使って行うのですが、V100というかなりハイグレードのGPUを8台並列で使っても6日と14時間掛かるらしく、もし私のGTX1060でやるとすれば4~5ヶ月掛かるレベルです(GPUのメモリの制約から実際にはやれませんが)。
コードを動かす準備をします
今回は、Githubにある Nvlabs/stylegan のサンプルコードを使います。この後 Google Colab からGit Clone しますので、とりあえず、眺めてみるだけでOKです。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
Google Colab に接続します。ファイル/python3 の新しいノートブックを開いたら、ランタイム/ランタイムのタイプを変更でGPUを選択して保存します。
今回、学習済みモデルを動かすだけですが、StyleGANは学習済みモデルを動かすのでさえ、GPUが必須です。上記コマンドをコピペして実行します。


実行するとこんな表示が出ます。リンクをクリックし、アカウントを選択したら、authorization code が表示されるので、これを四角内にコピぺすれば、Googole Driveがマウントされます。
|
1 2 3 |
cd drive/My Drive !git clone https://github.com/NVlabs/stylegan.git cd stylegan |
Google Drive/My Drive にサンプルコードを git clone し、ディレクトリをstylegan に移すコマンドです。 1行づつコピペして実行します。
A画像からB画像へトランジションさせる
2つのベクトルと、その間を線形補間したベクトルを使って、A画像からB画像へのトランジションをやってみます。
seed の番号を指定してランダムベクトルを生成すると、毎回同じ順番で同じベクトルが生成されます。こうすると再現性があるので、seed の番号を指定してランダムベクトルを生成することにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import os import pickle import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import config def main(): # Initialize TensorFlow. tflib.init_tf() # Load pre-trained network. url = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f: _G, _D, Gs = pickle.load(f) # _G = Instantaneous snapshot of the generator. Mainly useful for resuming a previous training run. # _D = Instantaneous snapshot of the discriminator. Mainly useful for resuming a previous training run. # Gs = Long-term average of the generator. Yields higher-quality results than the instantaneous snapshot. # Print network details. Gs.print_layers() # Pick latent vector. rnd = np.random.RandomState(10) # seed = 10 latents0 = rnd.randn(1, Gs.input_shape[1]) latents1 = rnd.randn(1, Gs.input_shape[1]) latents2 = rnd.randn(1, Gs.input_shape[1]) latents3 = rnd.randn(1, Gs.input_shape[1]) latents4 = rnd.randn(1, Gs.input_shape[1]) latents5 = rnd.randn(1, Gs.input_shape[1]) latents6 = rnd.randn(1, Gs.input_shape[1]) num_split = 39 # 2つのベクトルを39分割 for i in range(40): latents = latents6+(latents0-latents6)*i/num_split # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt) # Save image. os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'photo'+'{0:04d}'.format(i)+'.png') PIL.Image.fromarray(images[0], 'RGB').save(png_filename) if __name__ == "__main__": main() |
seed = 10 の7番目のベクトル(latents6)の画像から1番目のベクトル(latents0)の画像へトランジションさせるコードです。
補間ベクトルは、latents0 と latents6 の差を39分割して作成しています。全部で40枚の画像(png)が生成され、results フォルダーに保存されます。このコードをコピペして実行します。


latents6 ベクトルの画像(photo0000.png)です。どうですか、不自然さは全くなく、しかも1024×1024という高解像度。正にリアル!

latents0 ベクトルの生成画像(photo0039.png)です。こういうレベルのフェイク画像が生成されるようになると、確かに写真は証拠にならないですよね。
|
1 2 3 4 5 6 7 8 |
from PIL import Image import glob files = sorted(glob.glob('results/*.png')) images = list(map(lambda file: Image.open(file), files)) images[0].save('stylegan.gif', save_all=True, append_images=images[1:], duration=200, loop=0) |
results フォルダー内にある40枚の画像(png)を gif 動画に変換するコードです。gif動画はstyleganフォルダーの直下に、stylegan.gif という名前で保存されます。このコードをコピペして実行します。


latents6 から latents0 へのトランジションです。StyleGANが凄いのは、ベクトル補完の画像を細かく見ても、実に自然な変化をするということです。
なお、コードを実行して出来るオリジナルの gif 動画は1024×1024(45MB)と大きいので、ここでは500×500(11MB)に縮小したものを表示しています。
ただ、それでも結構大きなサイズなので、スマホで表示すると読み込みに多少時間が掛かり、動き出すまでしばらく待つ必要があるかもしれません。
Style-mixingをやってみる

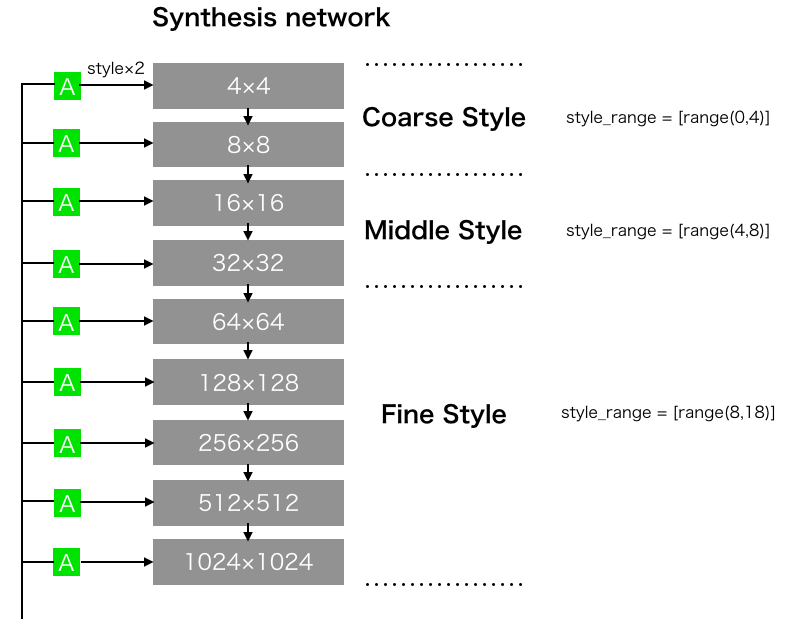
StyleGANで面白いのが、Style-mixingです。これは、Synthesis networkの各層に入力されるスタイルの内、解像度の低い層(4×4〜8×8)、解像度が中程度の層(16×16〜32×32)、あるいは解像度の高い層(64×64〜1024×1024)を他の画像のベクトルに入れ替えることによって、2つの画像の特徴をミックス出来るのです。
解像度の低い層へ入力するスタイルをCoarse Style、解像度が中程度の場合はMiddle Style、解像度が高い場合はFine Style と呼んでいます。どんなミックスが出来るのか見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
import os import pickle import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import config url_ffhq = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8) _Gs_cache = dict() def load_Gs(url): if url not in _Gs_cache: with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f: _G, _D, Gs = pickle.load(f) _Gs_cache[url] = Gs return _Gs_cache[url] # ---------------- Style mixing ------------------- def draw_style_mixing_figure(png, Gs, w, h, src_seeds, dst_seeds, style_ranges): print(png) src_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds) d1 = np.random.RandomState(503).randn(Gs.input_shape[1]) # seed = 503 のベクトルを取得 d2 = np.random.RandomState(888).randn(Gs.input_shape[1]) # seed = 888 のベクトルを取得 dx = (d2 - d1)/3 # 3分割で補間 steps = np.linspace(0,3,4) # stepsに[0,1,2,3] を代入 dst_latents = np.stack((d1+dx*step) for step in steps) # dst_latents にベクトルを4つスタック src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component] dst_dlatents = Gs.components.mapping.run(dst_latents, None) # [seed, layer, component] src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs) dst_images = Gs.components.synthesis.run(dst_dlatents, randomize_noise=False, **synthesis_kwargs) canvas = PIL.Image.new('RGB', (w * (len(src_seeds) + 1), h * 5), 'white') for col, src_image in enumerate(list(src_images)): canvas.paste(PIL.Image.fromarray(src_image, 'RGB'), ((col + 1) * w, 0)) for row, dst_image in enumerate(list(dst_images)): canvas.paste(PIL.Image.fromarray(dst_image, 'RGB'), (0, (row + 1) * h)) row_dlatents = np.stack([dst_dlatents[row]] * len(src_seeds)) row_dlatents[:, style_ranges[row]] = src_dlatents[:, style_ranges[row]] row_images = Gs.components.synthesis.run(row_dlatents, randomize_noise=False, **synthesis_kwargs) for col, image in enumerate(list(row_images)): canvas.paste(PIL.Image.fromarray(image, 'RGB'), ((col + 1) * w, (row + 1) * h)) png_filename = os.path.join(config.result_dir, 'style_mix.png') canvas.save(png_filename) # --------------- main ----------------- def main(): tflib.init_tf() os.makedirs(config.result_dir, exist_ok=True) draw_style_mixing_figure(os.path.join(config.result_dir, 'style_mix.png'), load_Gs(url_ffhq), w=1024, h=1024, src_seeds=[11,701,583], dst_seeds=[888,829,1898,1733,1614,845], style_ranges=[range(0,4)]*4) # style_mixingのレンジ指定 if __name__ == "__main__": main() |
Style-mixing を試すコードです。3つのオリジナル画像(seed = 11, 701, 583)のCoarse Style の部分を、2つの画像をトランジションさせたベクトル(seed =503 → seed = 888)に置き換えます。
結果は、resultsフォルダーの中に、style_mix.pngという名前で保存されます。このコードをコピペして実行します。


最上段の3枚のオリジナル画像のCoarse Style部分を、左端のトランジション画像に入れ替えた時の変化を表示しています。
主に、髪の毛の色や量、肌の色、目と口元などが変化しています。一方、顔の形や顔の向き、メガネはオリジナルのままです。
次に、Middle Styleをみてみましょう。コードの60行目の [range(0,4)]*4 を [range(4,8)]*4 に修正して再度コードを実行します。

Middle Styleの部分を置き換えた場合です。顔の向きや顔の形に変化が現われます。メガネはなくなってしまいましたね。
さらに、Fine Styleをみてみましょう。コードの60行目の [range(4,8)]*4 を [range(8,18)]*4 に修正して再度コードを実行します。

Fine Styleの部分を置き換えた場合です。もはや、トランジション画像の方が支配的になり、オリジナル画像から受け継ぐのは髪の毛の色と肌の色くらいになります。
それにしても、画像の完成度がここまで上がり、ある程度スタイルの制御も可能になって来るとは本当に驚きです。
では、また。