

前回に続き、Tensorflow hub にある Progressive GAN の学習済みモデルを使って、入力ベクトルのオフセット、特徴量ベクトルの操作などをして遊んでみたいと思います
こんにちは cedro です。
GAN(64×64ピクセル以上)は、訓練データの収集はもちろん、ネットワーク構成やハイパーパラメータ設定を調整して、いかに発散させず学習させるかというところに結構苦労します。なので、なんとか学習が完了すると、新たな画像生成ができたことを確認したら、直ぐどうもお疲れ様でした、という感じで終わってしまいます。
ところが、今回、Progressive GAN の学習済みモデルが手に入ったことで、学習完了のフェーズから、取り組みがスタートできて、とても新鮮な気持ちになり、色々なことを試してみたくなりました。
ということで今回も、前回に引き続き、Tensorflow hub にある Progressive GAN の学習済みモデルを使って、入力ベクトルのオフセット、特徴量ベクトルの操作などをして遊んでみたいと思います。
*前回のブログをご覧になっていない場合は、ここから前回のブログに飛びます。
入力ベクトルにオフセットをかける
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import tensorflow as tf import tensorflow_hub as hub import matplotlib.pyplot as plt import numpy as np # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") # 64個の 512次元乱数をモデルに入力する np.random.seed(seed=17) z_values = np.random.randn(64, 512) images = gan(z_values) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 8行 8列で表示する r, c = 8, 8 fig, axs = plt.subplots(r, c, figsize=(10,10)) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(out[cnt]) axs[i,j].axis('off') cnt += 1 fig.savefig("images.png") plt.show() plt.close() |


これが生成結果です。よく見ると、とんでもない画像が混じっていることに気付きます。少なくとも、赤枠で囲った12個はなんとかならないでしょうか。
どういう理由かは分かりませんが、赤枠の12個には、画像を崩す色々な要素が含まれているはずです。従って、この要素を抽出し、入力ベクトルから引いてやれば(オフセットをかければ)、生成画像の質は改善するはずです。
|
1 2 3 4 5 6 7 8 |
# 64個の 512次元乱数をモデルに入力する np.random.seed(seed=17) z = np.random.randn(64, 512) offset = (z[9]+z[12]+z[25]+z[27]+z[29]+z[35]+z[39]+z[46]+z[50]+z[58]+z[59]+z[60])/12 z_values = z - offset images = gan(z_values) |
先ほどのプログラムの一部を修正します。オフセットのかけ方は単純で、赤枠の12個のベクトルの単純平均を取って、乱数から引き算するだけです。


とんでもない画像は減りましたね。さて、赤枠を付けたところだけ、befor ,afterを見てみましょう。




画像を崩すベクトルを見つけて単純平均をして引くだけでも結構効果がありますね。まだ充分ではありませんが、生成画像は確実に良い方向に向かっているようです。
ということであれば、今度は、出来の良いベクトルを見つけて単純平均をとって、足してやれば、さらに生成画像は改善するのでしょうか。やってみます。


出来の良いベクトルとして、緑枠の12個を選んで、単純平均をとり、今度は乱数に足してみます。
|
1 2 3 4 5 6 7 8 9 |
# 64個の 512次元乱数をモデルに入力する np.random.seed(seed=17) z = np.random.randn(64, 512) offset1 = (z[9]+z[12]+z[25]+z[27]+z[29]+z[35]+z[39]+z[46]+z[50]+z[58]+z[59]+z[60])/12 offset2 = (z[2]+z[3]+z[6]+z[14]+z[17]+z[26]+z[31]+z[32]+z[43]+z[44]+z[52]+z[62])/12 z_values = z - offset1 + offset2 images = gan(z_values) |
先ほどのプログラムの一部をさらに修正します。画像を崩すベクトルの平均を引いて、出来栄えの良いベクトルの平均を足します。


これは素晴らしい!少し多様性が失われた感はありますが、オフセットをかけない時と比べれば、見違えるように画像生成レベルが向上しました。
笑いの特徴量ベクトル


女性の笑いの特徴量ベクトルを抽出し、笑っていない女性を笑わせてみようと思います。理屈は極めて単純で、笑っている女性のベクトルの平均 x1 から、笑っていない女性のベクトルの平均 x2 を引くだけです。
ここに表示したのは、seed = 17で乱数を初期化して100枚画像を生成し、その中から笑っている女性5枚、笑っていない女性5枚をピックアップした例です。
それでは、実際に試してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import tensorflow as tf import tensorflow_hub as hub from PIL import Image import numpy as np # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") # seed=17 で 100個の 512次元乱数を生成 np.random.seed(seed=17) z = np.random.randn(100, 512) # woman smile vector 生成 x1 = (z[2]+z[26]+z[31]+z[32]+z[81])/5 ### woman smile x2 = (z[34]+z[66]+z[69]+z[75]+z[97])/5 ### woman not smile x = (x1 - x2)/5 ### smile vector *1/5 y = z[66] ### target image img = [] for i in range(6): img.append(y) y = y + x img = np.asarray(img) images = gan(img) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 画像保存 for i, image in enumerate(out): Image.fromarray(np.uint8(image * 255)).save(f"result_{i}.png") |
女性の笑いの特徴量を抽出し、笑っていない女性を笑わせるプログラムです。乱数は seed = 17 で初期化しています。抽出した特徴量ベクトルを1/5し、ターゲット画像 z[66] に順次加算して、画像生成にどう作用するかをみてみます。


z [66]をターゲット画像にして、女性の笑いの特徴量ベクトルを1/5づつ加えた結果です。顔全体はほとんど変形することなく、口元のみ連続的に変化し、笑い顔になりました。


z [69] をターゲット画像にした例です。同じく、顔全体はほとんど変形することなく、口元のみ連続的に変化し、笑い顔になりました。


男性の場合も同様です。笑っている男性のベクトルの平均 x1 から、笑っていない男性のベクトルの平均 x2 を引くだけです。あまり気が進みませんが、男性も、ついでに試してみます(笑)。


ま、見ていて楽しくはありませんが、男性もちゃんと出来ます(笑)。
性別の特徴量ベクトル


男性に性別の特徴量を加えて女性にしたいとします。男性+性別の特徴量=女性にしたいとすると、性別の特徴量 x =女性の平均 x1 ー 男性の平均 x2 で計算できるはずです。
先ほどのプログラムが、そのまま流用できます。


男性の女性化です。たぶん、ターゲットの男性が女装をすると、こんな感じになるのかなー、という気がします。


女性の男性化です。男性を女性化する場合は、男性に性別特徴量を足しましたが、女性を男性化する場合は、女性から性別特徴量を引いてやればOKです。結果を見ると、z [66] の場合はなんとか男装で対応できそうですが、z [75] の場合は男装で対応するのは難しいかもしれませんね(笑)。
特徴量ベクトルの可視化
特徴量ベクトルを上手く可視化できると、何か新たな発見があるかもしれません。以前、100次元のベクトルを面グラフで表示してみましたが、今回はヒートマップで表現してみることにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import seaborn as sns import numpy as np import matplotlib.pyplot as plt np.random.seed(seed=17) z = np.random.randn(64, 512) x1 = (z[9]+z[12]+z[25]+z[27]+z[29])/5 ### woman x2 = (z[2]+z[3]+z[6]+z[14]+z[17])/5 ### man x = x1 - x2 arr_2d = x.reshape((16, 32)) plt.figure(figsize=(18, 9)) sns.heatmap(arr_2d, vmax=3.5, vmin=-3.5, center=0, cmap='bwr', square=True, annot=True, fmt='.1f') plt.savefig('./sex_vec.png') |
512次元の性別の特徴量ベクトルを32×16(32×16=512)のヒートマップで可視化するプログラムです。ヒートマップを表示する為に、seaborn ライブラリーをインポートします。表示したいベクトル x を計算したら、arr_2d = x.reshape ((16,32)) で 512 → 32×16にリシェイプします。後は、seaborn に渡せば、OK。実に簡単!
seaborn の引数は、データ、vmax(最大値)、vmin(最小値)、center(中央値)、cmap(カラーパレットの選択)、square(Trueでセルを正方形に)、annot(Trueでセルに数値を表示)、fmt(’.1f’で小数点1位まで表示)です。なお、cmap(カラーパレット)の選び方は、このリンクが分かりやすいので参考にどうぞ。
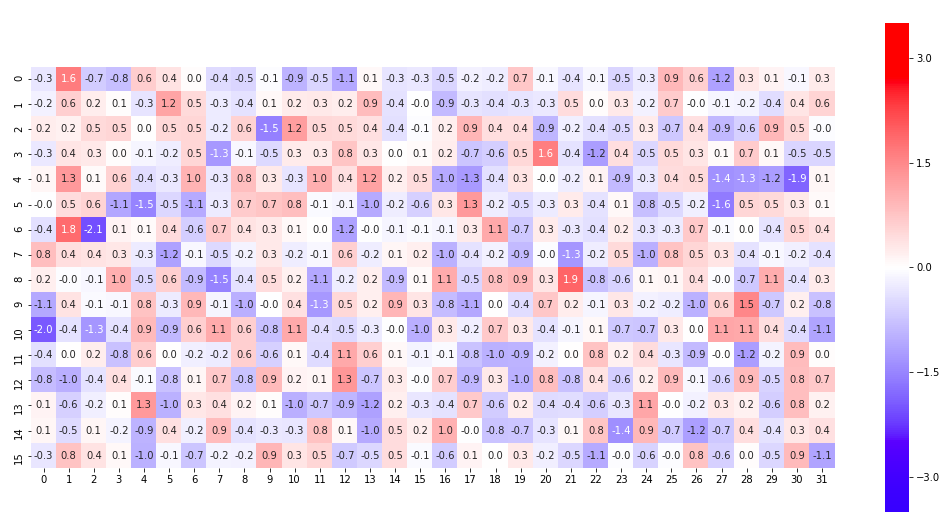

様々な特徴量を可視化して比較すると、新たな発見があるかもしれませんが、ここを突っ込んで行くとかなり時間がかかりそうなので、今回はここまでにしておきます(笑)。
ベクトルの要素を直接操作する
ベクトル x の1つ1つの要素を直接いじった時に、どう生成画像が変化するのかを調べると、新たな発見があるかもしれません。例えば、10番目の要素をいじると髪の毛が伸びたり、25番目の要素をいじるとメガネを掛けたりとか。画像生成に影響を与えるツボのようなものがあるのではないかという発想です。
ということで、ベクトル x の x [0] から x [511] までの512個の要素1つづつに、定数を足し算した時に、生成画像がどう変化するかみて見ます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import tensorflow as tf import tensorflow_hub as hub import matplotlib.pyplot as plt import numpy as np # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") # 512個の 512次元乱数をモデルに入力する np.random.seed(seed=17) z = np.random.normal(0,1,(512, 512)) img = [] list = np.array(range(0,511,1)) ### 0〜511までの整数のリストを作成 x = np.eye(512)[list] ### 0〜511のワンホットベクトルを生成 x = x*10 ### ワンホットベクトルに10を描ける for i in range(64): y = z[8] + x[i] ### ターゲットは z[8] img.append(y) img = np.asarray(img) images = gan(img) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 8行 8列で表示する r, c = 8, 8 fig, axs = plt.subplots(r, c, figsize=(10,10)) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(out[cnt]) axs[i,j].axis('off') cnt += 1 fig.savefig("images.png") plt.show() plt.close() |
ターゲット画像のベクトル x の x [0] から x [63] までの各要素1つ1つに、+10をプラスした時の生成画像を表示させるプログラムです。
まず、range関数で 0〜511の整数のリストを作成し、512個のワンホットベクトル(該当する要素のみ1でそれ以外は0)を生成し、10を掛けています。10を掛けているのは、変化を大きくし見やすくするためです。


ターゲット画像 x = z [8] の各要素に、+10をプラスした場合の画像の変化です。左上角が x [0]、右上角が x [7]、左下角が x [56]、右下角が x [63] です。
なんか、やたらメガネが生成されていますが、「おっ!これがメガネを生成する要素か!」と思うのは気が早いというもの。別の画像では、全く関係なかったりします。
画像生成に影響を与えるツボは絶対あるはずですが、要素の1つ1つに機能が割り当てられているという単純なものではなさそうです。
いやー、それにしても Progressive GAN の学習済みモデル、面白いです。本当にこれ、大人のおもちゃですね(笑)。
では、また。