

今回は、Tensorflow hub にあるProgressive GAN の学習済みモデルを使って、画像生成、ベクトル演算、モーフィングなどをして遊んでみたいと思います
こんにちは cedro です。
最近、Tensorflow hub という、学習済みモデルが使えるライブラリーの存在に気づいて調べてみると、珍しく CelebAの顔画像で訓練した Progressive GAN の学習済みモデルがありました。
GANの学習はMNISTでもそこそこ時間が掛かり、128×128の顔画像くらいになるとGTX1060を使っても丸2日とか掛かるので中々手を出し難いですが、学習済みモデルをいじるだけであれば、普通のノートパソコンでサクッと動かせます。
ということで、今回は、Tensorflow hub にあるProgressive GAN の学習済みモデルを使って、画像生成、ベクトル演算、モーフィングなどをして遊んでみたいと思います。
GANのおさらい

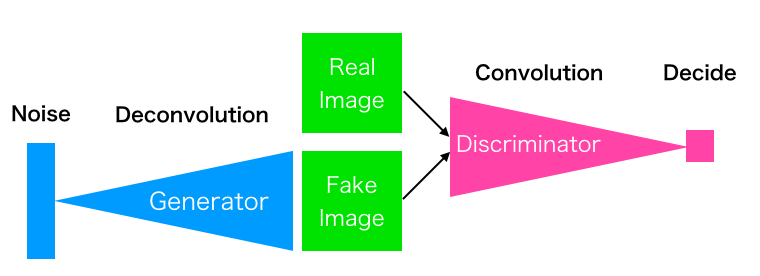
これは GAN の模式図です。Generator は Noise (乱数)を入力として、Discriminator に本物と間違わせるような偽物を作成することを学習します。
一方、Discriminator は本物と偽物を間違えないように学習します。この2つのネットワークが切磋琢磨することで高度な画像生成ができる様になります。

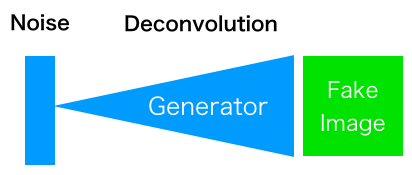
学習完了後は、Noise(乱数)をGeneratorに入力するとFake Image を生成するモデルが完成します。もちろん、Noise(乱数)の代わりに自分で設定したベクトルを入力しても良いです。同じベクトルを入力すれば、必ず同じ Fake Image を生成します。
今回、使うTensoleflow-hub の Progressive GAN の仕様は以下のようです。
■訓練データ:CelebA 顔画像 202,599枚
■訓練内容 :バッチサイズ16、ステップ数636,801(約50 epoch)
■生成画像 :カラー128×128ピクセル
とりあえず、動かしてみる
|
1 2 3 |
pip install tensorflow tensorflow-hub |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import tensorflow as tf import tensorflow_hub as hub import matplotlib.pyplot as plt import numpy as np # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") # 64個の 512次元乱数をモデルに入力 z_values = np.random.randn(64, 512) images = gan(z_values) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 8行 8列で表示 r, c = 8, 8 fig, axs = plt.subplots(r, c, figsize=(10,10)) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(out[cnt]) axs[i,j].axis('off') cnt += 1 fig.savefig("images.png") plt.show() plt.close() |
学習済みモデルを使って、乱数から新たな顔画像を生成するプログラムです。
ポイントは4行だけで、9行目でモデルをダウンロードし、13行目で入力の乱数を発生させ、14行目で関数の形にし、21行目で関数を実行させるだけです。簡単!凄いぞ、Tensorflow-hub !


プログラムを動かすと、こんな形で生成した画像を8行8列で表示します。画像生成に失敗している画像もありますね(笑)。入力は乱数を使っているので、生成される画像は毎回異なります。
さて、普通は学習が完了すると新たな画像を生成してみて、あー良かったねで終わってしまいますが、今回はここから遊んでみたいと思います。
入力の乱数の分布を変えてみる
プログラムでは、−1〜+1の範囲で乱数を発生(平均0・標準偏差1の正規分布)させています。これを0〜+1の範囲に変えてみると、どうなるでしょうか。
乱数を発生させている13行目を z_values = (np.random.randn(64,512)+1)/ 2 に書き換えて、プログラムを実行してみます。


なんと、男性ばかりになってしまいました! 0〜+1の範囲は男性の顔画像が多いということは、逆に −1〜0の範囲は女性の顔画像が多いのでしょうか?
乱数を発生させている13行目を z_values = ( np.random.rand(64,512)ー1)/ 2 に書き換えて、プログラムを実行してみます。

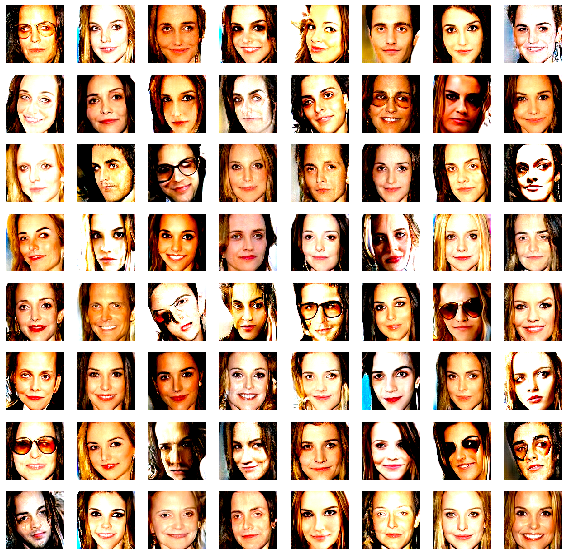
ありゃま、本当に、女性の顔画像ばかりになってしまいました。いやー、それにしても、0〜+1が男性で、−1〜0が女性なんて、出来過ぎな結果なような気がしますが、面白いですね。
入力ベクトルの演算をしてみる
入力は512次元の乱数で、いわゆるベクトルです。ベクトルであるならば演算ができるはずです。
しかし、毎回違う乱数を発生させていては実験がやり難いので、プログラムの乱数発生部分の直前に、np.random.seed (seed=16) というコマンドを追加します(16という数字は何でも良いです)。
こうすることで、乱数発生機能にリセットが掛かり、seed の設定が同じであれば、毎回同じ順番で同じ乱数を発生させることが出来ます。


np.random.seed (seed=16) で初期化した時の生成画像です。赤枠の3つの部分のベクトルを使って演算をしてみます。

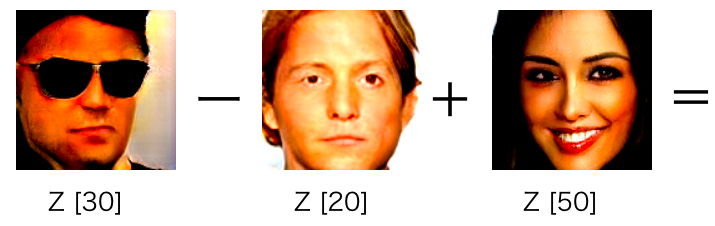
やりたいのは、こういう計算です。サングラスを掛けた男性から、掛けてない男性を引いて、掛けてない女性を加えるとどうなるか。GANの論文にも載っている、有名な計算例ですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import tensorflow as tf import tensorflow_hub as hub from PIL import Image import numpy as np # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") # seed=16 で 64個の 512次元乱数を生成 np.random.seed(seed=16) z = np.random.randn(64, 512) # ベクトルの加減算 x = z[30] - z[20] + z[50] z_values = np.reshape(x,(1,512)) images = gan(z_values) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 画像保存 for i, image in enumerate(out): Image.fromarray(np.uint8(image * 255)).save(f"result_{i}.png") |
ベクトル演算をして結果を保存するプログラムです。np.random.seed (seed=16) で初期化して、64個の乱数を発生させてから、x = z[30] – z[20] + z[50] を計算し、x で画像を生成させます。結果は、pngで保存します。さて、どうなるでしょうか。

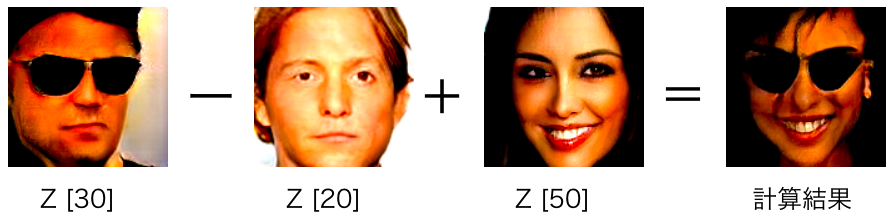
期待通り、ベクトル演算の結果は、サングラスを掛けた女性になりました。論文では、サングラスを掛けた男性、掛けてない男性、掛けてない女性のそれぞれを複数サンプリングし平均をとって計算しているのですが、とりあえずN=1でやってみました。
モーフィングをやってみる
ベクトルAからベクトルBの間を補間したベクトルを作って入力にすれば、ベクトルAの画像からベクトルBの画像へ連続的に変化する、いわゆるモーフィングが出来るはずです。


これは、np.random.seed (seed=5) で初期化した時の生成画像です。赤枠の4つの画像のベクトルを補間して、モーフィングをやってみます。

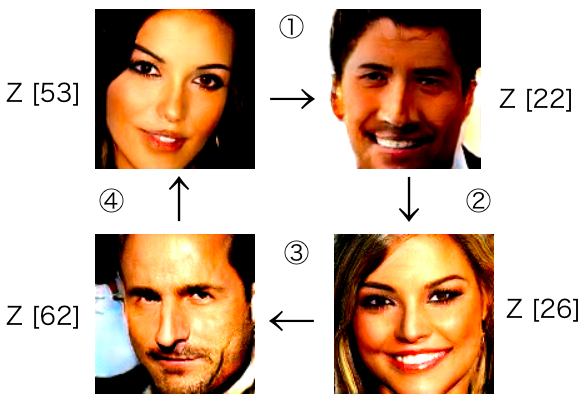
こんな感じで、モーフィングさせてみたいと思います。Z [53] → Z [22] → Z[26] → Z[62] → Z [53] とターゲットとなる画像を決めて、その間を補間します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import tensorflow as tf import tensorflow_hub as hub from PIL import Image import numpy as np np.random.seed(seed=5) z = np.random.randn(64, 512) n = 19 img = [] z0 = z[53] z1 = z[22] z2 = z[26] z3 = z[62] d1 = (z1 - z0)/n d2 = (z2 - z1)/n d3 = (z3 - z2)/n d4 = (z0 - z3)/n for i in range(n+1): img.append(z0) z0 = z0 + d1 for i in range(n+1): img.append(z0) z0 = z0 + d2 for i in range(n+1): img.append(z0) z0 = z0 + d3 for i in range(n+1): img.append(z0) z0 = z0 + d4 img = np.asarray(img) # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") images = gan(img) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 画像保存 for i, image in enumerate(out): Image.fromarray(np.uint8(image * 255)).save(f"result_{i}.png") |
モーフィングを行うプログラムです。兎に角、パッと間違いなく動かせるように、プログラムを組みましたので、美しくなくてすみません(笑)。2つのベクトル間を19分割して、単純に線形補間しているだけです。


プログラムを実行すると、こんな感じでモーフィング画像が80個保存されます。


保存した80個の画像を使ってGIF動画にすると、YouTube にもよくある、例の動画になります。女性→男性→女性→男性と交互に持って来た方が変化が大きくて面白いようです。
VAE風にマッピングしてみる
変分オートエンコーダー(VAE)をご存知ですか。高次のベクトル空間に配置されている画像を見事に2次元マップにマッピングしてくれるアレです。このブログでも、過去4回(①、②、③、④)に渡って記事にしています。
512次元のGANをなんとか2次元マップにマッピングできないだろうかと考えた結果、先ほどの4つの画像を四隅に配置して、8行8列のVAE風に加工してみたいと思います。

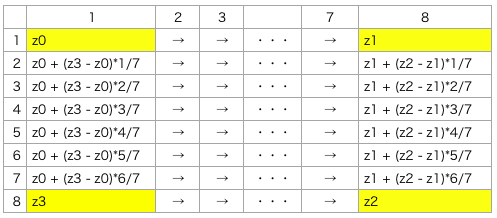
生成ロジックは、四隅にターゲットとする画像のベクトル( z0 〜z3 )を配置し、1列目と8列目を補間してから、1行づつ横へ補間します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
import tensorflow as tf import tensorflow_hub as hub import matplotlib.pyplot as plt import numpy as np np.random.seed(seed=5) z = np.random.randn(64, 512) img = [] z0 = z[53] z1 = z[22] z2 = z[26] z3 = z[62] x1 = z0 x2 = z0 + (z3 - z0)*1/7 x3 = z0 + (z3 - z0)*2/7 x4 = z0 + (z3 - z0)*3/7 x5 = z0 + (z3 - z0)*4/7 x6 = z0 + (z3 - z0)*5/7 x7 = z0 + (z3 - z0)*6/7 x8 = z3 x9 = z1 x10 = z1 + (z2 - z1)*1/7 x11 = z1 + (z2 - z1)*2/7 x12 = z1 + (z2 - z1)*3/7 x13 = z1 + (z2 - z1)*4/7 x14 = z1 + (z2 - z1)*5/7 x15 = z1 + (z2 - z1)*6/7 x16 = z2 d1 = (x9 - x1)/7 d2 = (x10 - x2)/7 d3 = (x11 - x3)/7 d4 = (x12 - x4)/7 d5 = (x13 - x5)/7 d6 = (x14 - x6)/7 d7 = (x15 - x7)/7 d8 = (x16 - x8)/7 for i in range(8): img.append(x1) x1 = x1 + d1 for i in range(8): img.append(x2) x2 = x2 + d2 for i in range(8): img.append(x3) x3 = x3 + d3 for i in range(8): img.append(x4) x4 = x4 + d4 for i in range(8): img.append(x5) x5 = x5 + d5 for i in range(8): img.append(x6) x6 = x6 + d6 for i in range(8): img.append(x7) x7 = x7 + d7 for i in range(8): img.append(x8) x8 = x8 + d8 img = np.asarray(img) # モデルのダウンロード gan = hub.Module("https://tfhub.dev/google/progan-128/1") images = gan(img) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 画像生成 out = sess.run(images) # 8行 8列で表示 r, c = 8, 8 fig, axs = plt.subplots(r, c, figsize=(10,10)) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(out[cnt]) axs[i,j].axis('off') cnt += 1 fig.savefig("images.png") plt.show() plt.close() |
VAE風に8行×8列で表示するプログラムです。何の工夫もないですが、間違いなく動かせるように、プログラムを組みましたので、極めて助長的ですみません(笑)。


簡単に言うと、先ほどのモーフイングは外周だけでしたが、VAE風にすることによって中を埋めた形になりました。さらに、生成する顔画像のバリエーションが増えましたね。
いやー、これは楽しいオモチャですね。Macbook Air でも楽々と動かせて、色々なことが試せます。
次回もまた、Tensorflow hub の Progressive GAN で遊んでみたいと思います。
では、また。