
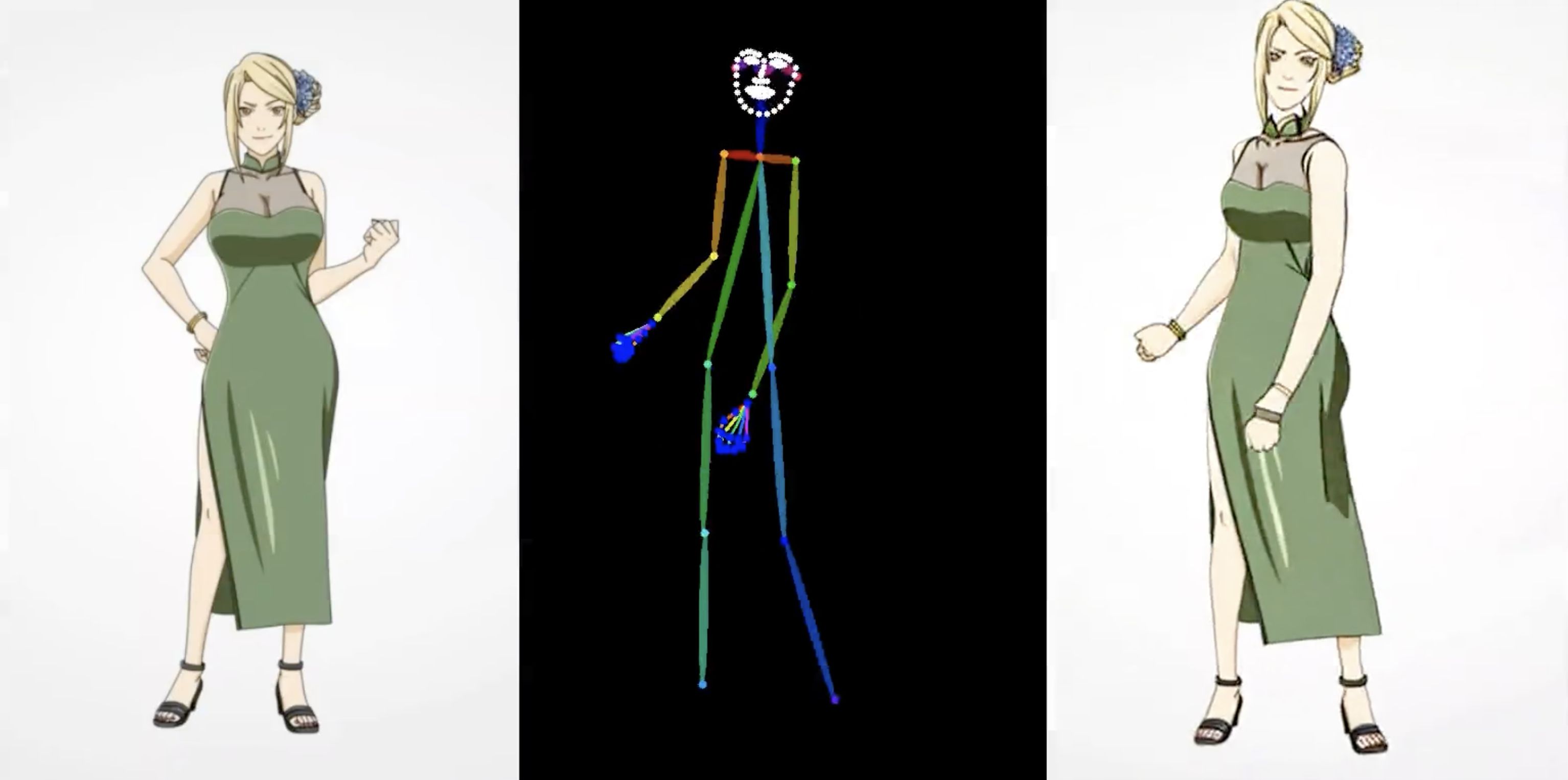
1.はじめに
今回ご紹介するのは、昨年11月にアリババが発表した、1枚の画像から動画を生成する「Animate Anyone」という技術です。
*この論文は、2023.12に提出されました。
2.Animate Anyoneとは?
下記がAnimate Anyoneのフロー図です。 まず、Pose SequenceをPose Guiderでエンコードし、Noiseと融合し、 Denoising UNet がビデオ生成のためのノイズ除去プロセスを実行します。
Denoising UNetの計算ブロックは、右側の破線のボックスに示すように、空間アテンション、クロスアテンション、および時間アテンションで構成されます。
参照画像の統合には 2 つの側面が含まれます。 まず、ReferenceNet を通じて詳細な特徴が抽出され、空間アテンションに利用されます。 次に、クロスアテンション用の CLIP 画像エンコーダを通じて意味的特徴が抽出されます。 時間的注意は時間次元で機能します。 最後に、VAE デコーダは結果をビデオ クリップにデコードします。


3.コード
今回のコードはアリババが公式に公開したものではなく、論文の実証結果に基づいて別の方が作成したものです。そして、今回使用するcolabは、[このリンク]をクリックすると動かせます。なお、このcolabは@camenduru氏によって作成されたものです。
コードは、先頭の動作ボタンを1回押すだけです。そうすると、必要なコードとデータが自動的にダウンロードされ、処理が行われます。ログに、Running on public URLが表示されたら、それをクリックするとGUI画面が表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
%cd /content !git clone -b dev https://github.com/camenduru/Moore-AnimateAnyone %cd /content/Moore-AnimateAnyone !pip install -q gradio==3.50.2 diffusers==0.24.0 av==11.0.0 decord==0.6.0 einops==0.4.1 accelerate==0.21.0 !pip install -q omegaconf==2.2.3 !pip install -q https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip !apt -y install -qq aria2 !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/model_index.json -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5 -o model_index.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/unet/config.json -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5/unet -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/resolve/main/stable-diffusion-v1-5/unet/diffusion_pytorch_model.bin -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5/unet -o diffusion_pytorch_model.bin !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/v1-inference.yaml -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5 -o v1-inference.yaml !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5/feature_extractor -o preprocessor_config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/denoising_unet.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o denoising_unet.pth !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/motion_module.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o motion_module.pth !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/pose_guider.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o pose_guider.pth !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/reference_unet.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o reference_unet.pth !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/stabilityai/sd-vae-ft-mse/raw/main/config.json -d /content/Moore-AnimateAnyone/pretrained_weights/sd-vae-ft-mse -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/stabilityai/sd-vae-ft-mse/resolve/main/diffusion_pytorch_model.bin -d /content/Moore-AnimateAnyone/pretrained_weights/sd-vae-ft-mse -o diffusion_pytorch_model.bin !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/stabilityai/sd-vae-ft-mse/resolve/main/diffusion_pytorch_model.safetensors -d /content/Moore-AnimateAnyone/pretrained_weights/sd-vae-ft-mse -o diffusion_pytorch_model.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lambdalabs/sd-image-variations-diffusers/raw/main/image_encoder/config.json -d /content/Moore-AnimateAnyone/pretrained_weights/image_encoder -o config.json !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lambdalabs/sd-image-variations-diffusers/resolve/main/image_encoder/pytorch_model.bin -d /content/Moore-AnimateAnyone/pretrained_weights/image_encoder -o pytorch_model.bin !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/resolve/main/dw-ll_ucoco_384.onnx -d /content/Moore-AnimateAnyone/pretrained_weights/DWPose -o dw-ll_ucoco_384.onnx !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/resolve/main/yolox_l.onnx -d /content/Moore-AnimateAnyone/pretrained_weights/DWPose -o yolox_l.onnx !python app.py |
これがGUI画面です。Refetence Image に人の画像を、Motion Sequence に動きの動画をセットして、Animateボタンを押すだけです。
この画面のさらに下に、Exampleがありますので、クリックするとサンプルをそのまま使うことが出来ます。ここでは、Exampleの先頭のものをクリックしています。Video Lengthを120に設定して、Animateボタンを押します。しばらくすると、動画が生成されます。

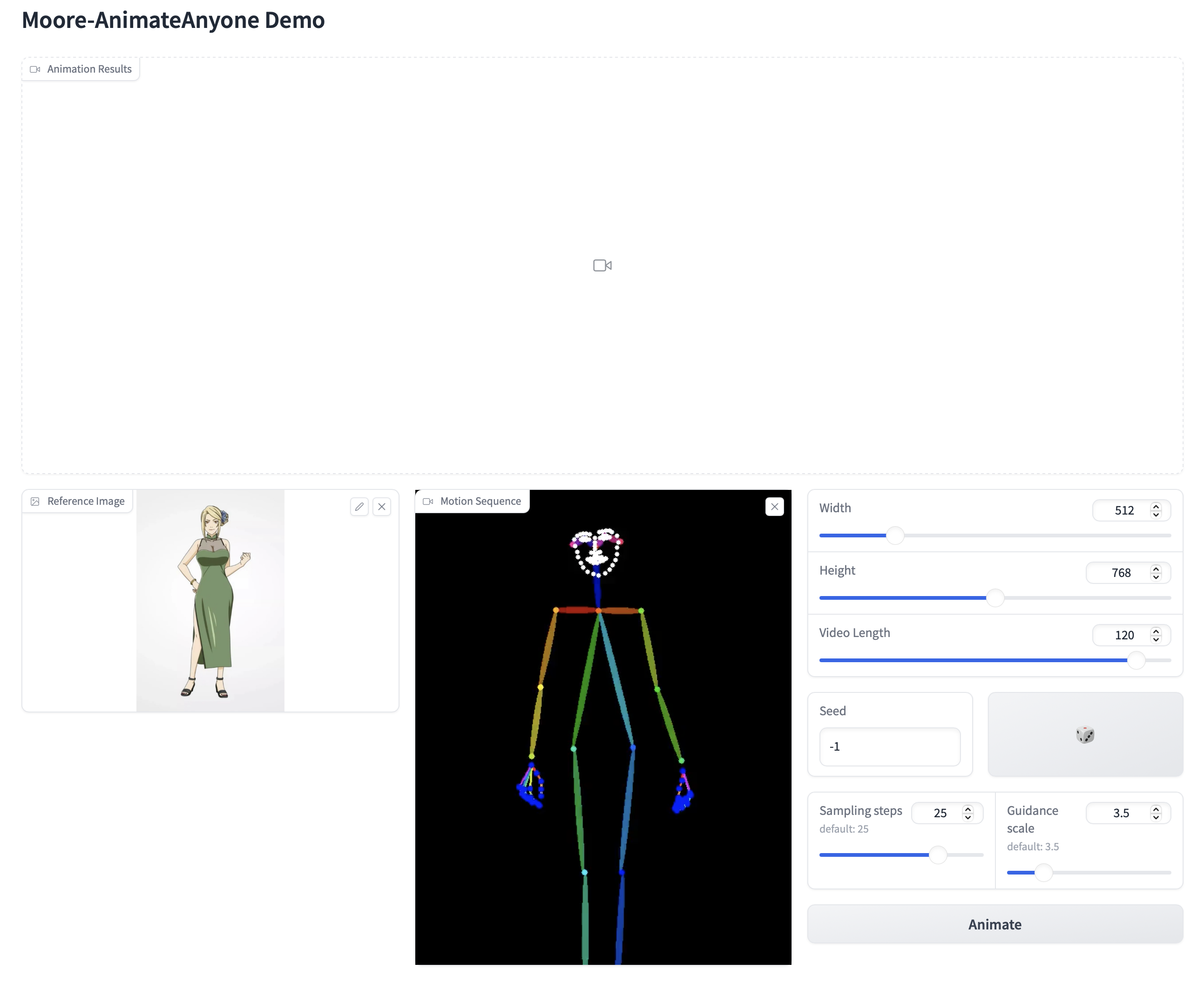
これが生成された動画です。
(オリジナルgithub)https://github.com/MooreThreads/Moore-AnimateAnyone