

1.はじめに
2021年1月OpenAIは、画像と画像を説明するテキストのペア4億組を学習させた、汎用画像分類モデルCLIPを発表しました。今回は、このCLIPを使って、大量の画像の中から自分が探したい画像をテキストで検索するシステムを作ってみます。
2.CLIPとは?
まず、CLIPに行っている事前学習の内容を見てみましょう。

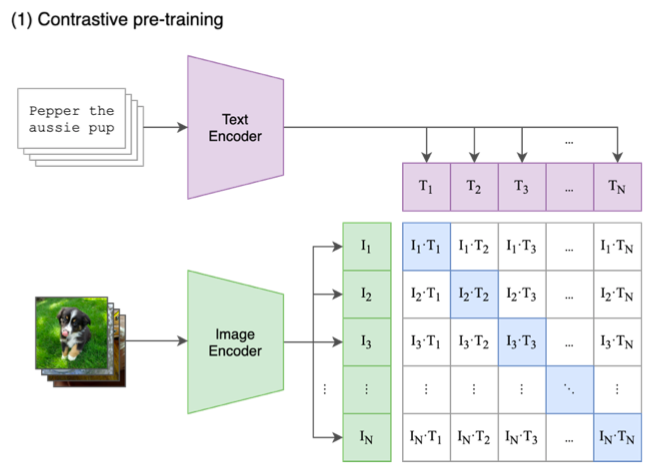
CLIPに入力されるのは、「画像」と「その内容を説明するテキスト」のペアがN個です。Image Encoderは、N個の画像からその特徴を表すベクトル I_1〜I_N を取り出そうとします。TextEncoderは、N個のテキストからその特徴を表すベクトル T_1〜T_N を取り出そうとします。
ベクトルには、2つのベクトルの内積(COS類似度)が大きいほど類似度が高く、内積が小さいほど類似度が低い、という性質があります。CLIPは、この性質を利用して、ペアであるベクトルの内積、I_1・T_1, I_2・T_2, I_3・T_3 , … , I_N・T_N を最大化し、ペアではないベクトルの内積を最小化するように、Image EncoderとText Encoderのパラメータを学習します。
CLIPは、この事前学習によって、画像からもテキストからも、その特徴を適切に表すベクトルを取得できるようになります。次に、事前学習したCLIPを使って画像分類をする段階を見てみましょう。

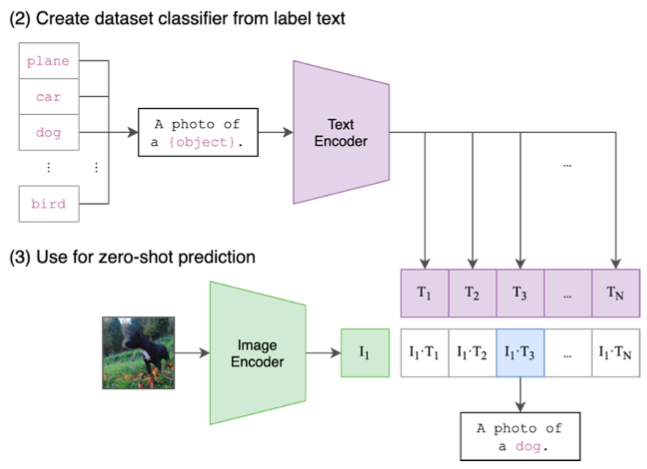
ラベルによる画像分類を考えます。ラベルは普通「単語」なので、「テキスト」を学習して来たCLIPには上手く解釈できません。なので、例えばラベルがdogであれば「A photo of a dog」という文にして、N個のラベルの文をText Encoderへ入力しラベルの特徴ベクトル T_1〜T_N を取り出します。
一方で、分類したい画像からImage Encoderで画像の特徴ベクトル I_1 を取り出します。そして、画像の特徴ベクトルとラベルの特徴ベクトルの掛け算を行った結果をみて、一番大きい値となったところを分類すべきラベルと判断すれば良いわけです。
ということで、CLIPは膨大な量の事前学習を行っているので、全く学習を行わずに分類タスクを解けるのです。
3.CLIPを画像検索に利用する
それでは、大量の画像の中からテキストの内容に最もふさわしい画像を検索するには、どうしたら良いでしょうか。実は、CLIPを使うと簡単です。

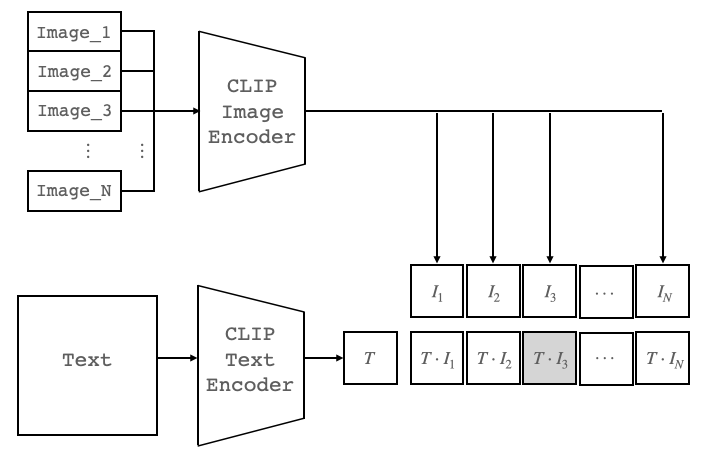
大量の画像から画像の特徴ベクトルI_1〜I_Nを抽出し、テキストからテキストの特徴ベクトル Tを抽出し、内積(COS類似度)が一番大きくなった画像を選べば良いわけです。それでは、早速コードを動かしてみましょう。
4.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Pytorchバージョン変更 ! pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 -f https://download.pytorch.org/whl/torch_stable.html # CLIP関連コードのコピー ! git clone https://github.com/openai/CLIP.git %cd /content/CLIP/ # CLIPのモデル化 ! pip install ftfy regex import clip model, preprocess = clip.load('ViT-B/32', jit=True) model = model.eval() # サンプル画像ダウンロード import gdown gdown.download('https://drive.google.com/uc?id=1xIYYYzw9aZhjhyjMM12nz4XjnWUzpp6v', 'img.zip', quiet=False) ! unzip img.zip |
CLIPのモデル化によって、clip.tokenize() でテキストをトークン(数字)にし、model.encode_text() でトークンからテキストの特徴ベクトルを抽出できるようになります。また、model.encode_image() で画像から画像の特徴ベクトルを抽出できるようになります。
検索に使う画像は、有名な顔画像のデータセット CelebAから先頭の5,000枚を取り出したものをグーグルドライブからダウンロードして使います。画像サイズは、178×218です。
次に、5,000枚の画像を読み込みます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# --- 画像の前処理 ---- import torch import numpy as np from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize from PIL import Image import glob from tqdm import tqdm # 前処理設定 preprocess = Compose([ Resize(224, interpolation=Image.BICUBIC), CenterCrop(224), ToTensor() ]) image_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073]).cuda() image_std = torch.tensor([0.26862954, 0.26130258, 0.27577711]).cuda() # 画像の読み込み images =[] files = glob.glob('./img/*.png') files.sort() for i, file in enumerate(tqdm(files)): image = preprocess(Image.open(file).convert("RGB")) images.append(image) image_input = torch.tensor(np.stack(images)).cuda() image_input -= image_mean[:, None, None] image_input /= image_std[:, None, None] print('image_input.shape = ', image_input.shape) |


img フォルダーからpng画像を1枚づつ読み、サイズを224×224に調整しアペンドします。そしてテンソルに変換し、正規化(輝度の平均を引き、輝度のバラツキで割る)します。結果、image_input のシェイプは(5000,3,224,224)となります。
次に、検索するテキストを入力します。text = She is a charming woman with blonde hair and blue eyes(彼女はブロンドの髪で青い目をしたチャーミングな女性です)でやってみます。
|
1 2 3 4 5 6 |
text = 'She is a charming woman with blonde hair and blue eyes' text_input = clip.tokenize(text) text_input = text_input.cuda() print('text_input = ', text_input) print('text_input.shape = ', text_input.shape) |


clip.tokenize() で、テキストをトークン(数字)に変換します。トークン化した text_input は余分な部分をゼロで埋め、シェイプは (1,77) になっています。
それでは、image_input と text_input を元に、COS類似度を計算します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# --- 画像とテキストのCOS類似度の計算 ---- # 特徴ベクトルを抽出 with torch.no_grad(): image_features = model.encode_image(image_input).float() text_features = model.encode_text(text_input).float() text_features /= text_features.norm(dim=-1, keepdim=True) # COS類似度を計算 text_probs = torch.cosine_similarity(image_features, text_features) print('image_features.shape = ', image_features.shape) print('text_features.shape = ', text_features.shape) print('text_probs.shape = ', text_probs.shape) |


model.encode_image() で画像の特徴ベクトル image_features を抽出し、model.encode_text() でテキストの特徴ベクトル text_features を抽出します。そして、torch.cosine_similarity() でその2つのベクトルのCOS類似度 text_probs を計算します。
それでは、検索結果を見てみましょう。text_probs には5,000枚の画像のCOS類似度計算の結果が格納されているので、高い順にソートしてTOP3に該当するインデックスの画像ファイルを表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# --- 検索結果の表示 --- import matplotlib.pyplot as plt # 検索テキスト表示 print('text = ', text) print() # COS類似度の高い順にインデックスをソート x = np.argsort(-text_probs.cpu(), axis=0) # COS類似度TOP3を表示 fig = plt.figure(figsize=(30, 40)) for i in range(3): name = str(x[i].item()).zfill(6)+'.png' img = Image.open('./img/'+name) images = np.asarray(img) ax = fig.add_subplot(10, 10, i+1, xticks=[], yticks=[]) image_plt = np.array(images) ax.imshow(image_plt) cos_value = round(text_probs[x[i].item()].item(), 3) ax.set_xlabel(cos_value, fontsize=12) plt.show() plt.close() |


おっ!CLIP 中々やりますね。結構イケてる感じです。画像の下に表示されているのがCOS類似度の値です。COS類似度は数字が大きいほど類似度が高く、+1〜 −1の値をとります。
もう1つやってみましょう。画像は読み込み済みなので、テキスト入力のところから再度実行すればOKです。text = He is a dandy middle-aged man wearing glass(彼はメガネを掛けた中年のダンディな男性)でやってみると、


3番目の男性が少し若そうですが、5,000枚の中ではそこそこ類似度が高いのかもしれません。
それにしても、CLIP便利です。色々な応用が考えられそうですね。では、また。
(オリジナルgithub)https://github.com/openai/CLIP