
1.はじめに
画像生成するGANの学習には大量のデータが必要で、データが少ないとオーバーフィッティングによるモード崩壊が起こり易く、そうしたことが発生した場合の対策はデータ数の増加しかありませんでした。
一方、画像分類では、データが少ない場合の対策として、データを変換(拡大、回転、シフトなど)して水増しする Data Augmentation が有効であることが以前から知られていました。
今回は、2020/6に発表されたGANの学習における Data Augmentation とも言える、Differentiable Augmentation についてご説明します。
2.Differentiable Augmentationとは
単純に画像分類の場合と同様にリアル画像 x だけをT(x)に変換すると、D (Discriminator) が変換後の画像も実際の画像の分布に含まれていると勘違いしてしまうため、あまり強い変換をかけることが出来ません。

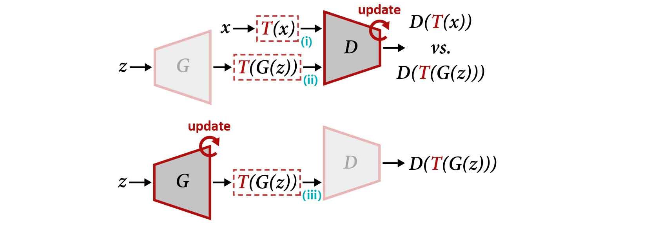
そこで、上記の図の様に、フェイク画像G(z)もT(G(z))に変換することで、強い変換をかけられるようになったというのがポイントです。式で表すと以下の様です。

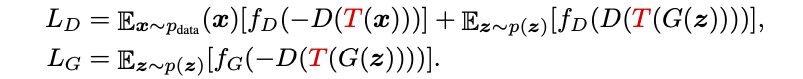
ここで使われる変換T(x)は、カットアウト(画像をランダムな正方形でマスキング), 色・コントラスト・彩度のランダム変化などが使われています。
さらに、T(x)による変換の影響がより小さくなるConsistency正則化という手法も使われています。
それでは、本当に効果があるのかをテストしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
今回、GANはStyleGAN2、データはWebから適当に拾った新垣結衣さんの顔画像100枚を使って Differential Augmentation を試してみます。
最初に、tensorflow 1.15.0をインストールし、Githubからコードをコピーします。そして、新垣結衣さんの画像100枚(64×64)と学習済みの重みをダウンロードします。詳細はGoogle colabを参照下さい。
まず、関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 関数の定義 import tensorflow as tf import os import numpy as np import PIL import IPython from multiprocessing import Pool import matplotlib.pyplot as plt from dnnlib import tflib, EasyDict from training import misc, dataset_tool from metrics import metric_base from metrics.metric_defaults import metric_defaults def _generate(network_name, num_rows, num_cols, seed, resolution): if seed is not None: np.random.seed(seed) with tf.Session(): _, _, Gs = misc.load_pkl(network_name) z = np.random.randn(num_rows * num_cols, Gs.input_shape[1]) outputs = Gs.run(z, None, output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)) outputs = np.reshape(outputs, [num_rows, num_cols, *outputs.shape[1:]]) outputs = np.concatenate(outputs, axis=1) outputs = np.concatenate(outputs, axis=1) img = PIL.Image.fromarray(outputs) img = img.resize((resolution * num_cols, resolution * num_rows), PIL.Image.ANTIALIAS) return img def generate(network_name, num_rows, num_cols, seed=None, resolution=128): with Pool(1) as pool: return pool.apply(_generate, (network_name, num_rows, num_cols, seed, resolution)) |
先程ダウンロードした新垣結衣の画像100枚(100-shot-gakki)からデータセットを作成します。
ご自分のオリジナルデータを使う場合は、同様に 64×64 の画像を100枚集めてフォルダーに入れて使えばOKです。100枚であれば、簡単に集められると思いますので、ぜひトライしてみて下さい。
|
1 2 3 4 5 6 7 8 9 10 |
# 100-shot-gakki を読み込み学習用データセットを作成 data_dir = dataset_tool.create_dataset('100-shot-gakki') training_images = [] for fname in os.listdir(data_dir): if fname.endswith('.jpg'): training_images.append(np.array(PIL.Image.open(os.path.join(data_dir, fname)))) imgs = np.reshape(training_images, [5, 20, *training_images[0].shape]) imgs = np.concatenate(imgs, axis=1) imgs = np.concatenate(imgs, axis=1) PIL.Image.fromarray(imgs).resize((1000, 250), PIL.Image.ANTIALIAS) |

さあ、こんな100枚の画像だけで本当にGANの学習ができるのでしょうか?
***************************************
学習に入る前に、ご自分のGoogle Colabに割り当てられているGPUのタイプを確認します。
|
1 2 |
# GPUの確認 !nvidia-smi |

試行回数(kimg)を300とした場合に、P100で7.3時間、V100で4.1時間かかりますので、それを確認後下記のコードを実行し学習を開始して下さい。
なお、GPUがK80の場合や学習に時間を掛けたくない方は、下記のコードの実行はパスして下さい。
|
1 2 |
# 学習の実行 !python3 run_few_shot.py --dataset=100-shot-gakki --resolution=64 --total-kimg=300 |
※学習をした場合は、学習完了後 resultsフォルダーの中に( network-snapshot-XXXXXX.pkl)が作成されますので、それをDiffAugment-stylegan2のディレクトリーに移動して下さい。そして、この後の generate() , generate_gif.py の引数をそのファイル名に変更して下さい。
**************************************
先程ダウンロードした学習済みの重みを使って画像生成します。
|
1 2 |
# 学習済みの重みを使って画像生成 generate('network-snapshot-gakki-000500.pkl', num_rows=3, num_cols=5, seed=3) |


さすがに学習画像100枚では生成画像の質は高くないですが、なんとかガッキーを再現しています。
先程ダウンロードした学習済みの重みを使ってGIF動画を作成し interp.gif で保存します
|
1 2 3 |
# 学習済みの重みを使って、GIF動画を作成 !python3 generate_gif.py -r network-snapshot-gakki-000500.pkl -o interp.gif --num-rows=2 --num-cols=3 --seed=1 IPython.display.Image(open('interp.gif', 'rb').read()) |


GIF動画を作成してみました。それにしても、以前は事前学習無しで100枚の画像だけでGANをやるなんて考えれなかったわけですが、技術の進歩は凄いですね。
では、また。