1.はじめに
画像生成するGANの学習には大量のデータが必要で、データが少ないとオーバーフィッティングによるモード崩壊が起こり易く、そうしたことが発生した場合の対策はデータ数の増加しかありませんでした。
一方、画像分類では、データが少ない場合の対策として、データを変換(拡大、回転、シフトなど)して水増しする Data Augmentation が有効であることが以前から知られていました。
今回は、2020/6に発表されたGANの学習における Data Augmentation とも言える、Differentiable Augmentation についてご説明します。
2.Differentiable Augmentationとは
単純に画像分類の場合と同様にリアル画像 x だけをT(x)に変換すると、D (Discriminator) が変換後の画像も実際の画像の分布に含まれていると勘違いしてしまうため、あまり強い変換をかけることが出来ません。
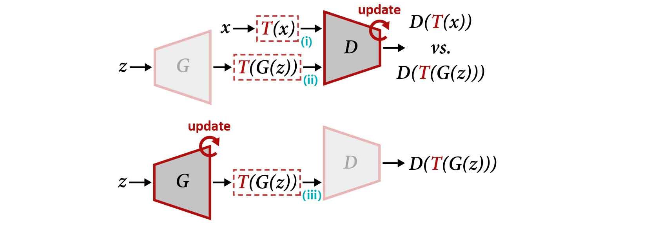
そこで、上記の図の様に、フェイク画像G(z)もT(G(z))に変換することで、強い変換をかけられるようになったというのがポイントです。式で表すと以下の様です。
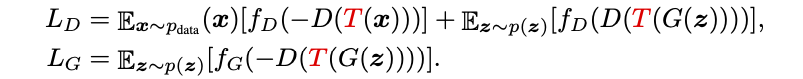
ここで使われる変換T(x)は、カットアウト(画像をランダムな正方形でマスキング), 色・コントラスト・彩度のランダム変化などが使われています。
さらに、T(x)による変換の影響がより小さくなるConsistency正則化という手法も使われています。
それでは、本当に効果があるのかをテストしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
今回、GANはStyleGAN2、データはWebから適当に拾った新垣結衣さんの顔画像100枚を使って Differential Augmentation を試してみます。
最初に、tensorflow 1.15.0をインストールし、Githubからコードをコピーします。そして、新垣結衣さんの画像100枚(64×64)と学習済みの重みをダウンロードします。詳細はGoogle colabを参照下さい。
まず、関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 関数の定義 import tensorflow as tf import os import numpy as np import PIL import IPython from multiprocessing import Pool import matplotlib.pyplot as plt from dnnlib import tflib, EasyDict from training import misc, dataset_tool from metrics import metric_base from metrics.metric_defaults import metric_defaults def _generate(network_name, num_rows, num_cols, seed, resolution): if seed is not None: np.random.seed(seed) with tf.Session(): _, _, Gs = misc.load_pkl(network_name) z = np.random.randn(num_rows * num_cols, Gs.input_shape[1]) outputs = Gs.run(z, None, output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)) outputs = np.reshape(outputs, [num_rows, num_cols, *outputs.shape[1:]]) outputs = np.concatenate(outputs, axis=1) outputs = np.concatenate(outputs, axis=1) img = PIL.Image.fromarray(outputs) img = img.resize((resolution * num_cols, resolution * num_rows), PIL.Image.ANTIALIAS) return img def generate(network_name, num_rows, num_cols, seed=None, resolution=128): with Pool(1) as pool: return pool.apply(_generate, (network_name, num_rows, num_cols, seed, resolution)) |
先程ダウンロードした新垣結衣の画像100枚(100-shot-gakki)からデータセットを作成します。
ご自分のオリジナルデータを使う場合は、同様に 64×64 の画像を100枚集めてフォルダーに入れて使えばOKです。100枚であれば、簡単に集められると思いますので、ぜひトライしてみて下さい。
|
1 2 3 4 5 6 7 8 9 10 |
# 100-shot-gakki を読み込み学習用データセットを作成 data_dir = dataset_tool.create_dataset('100-shot-gakki') training_images = [] for fname in os.listdir(data_dir): if fname.endswith('.jpg'): training_images.append(np.array(PIL.Image.open(os.path.join(data_dir, fname)))) imgs = np.reshape(training_images, [5, 20, *training_images[0].shape]) imgs = np.concatenate(imgs, axis=1) imgs = np.concatenate(imgs, axis=1) PIL.Image.fromarray(imgs).resize((1000, 250), PIL.Image.ANTIALIAS) |

さあ、こんな100枚の画像だけで本当にGANの学習ができるのでしょうか?
***************************************
学習に入る前に、ご自分のGoogle Colabに割り当てられているGPUのタイプを確認します。
|
1 2 |
# GPUの確認 !nvidia-smi |
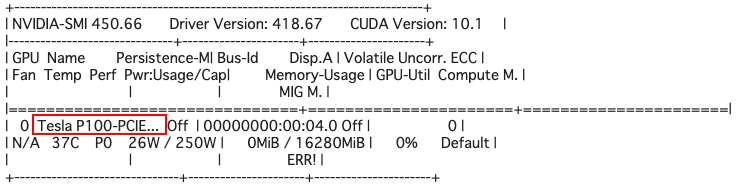
試行回数(kimg)を300とした場合に、P100で7.3時間、V100で4.1時間かかりますので、それを確認後下記のコードを実行し学習を開始して下さい。
なお、GPUがK80の場合や学習に時間を掛けたくない方は、下記のコードの実行はパスして下さい。
|
1 2 |
# 学習の実行 !python3 run_few_shot.py --dataset=100-shot-gakki --resolution=64 --total-kimg=300 |
※学習をした場合は、学習完了後 resultsフォルダーの中に( network-snapshot-XXXXXX.pkl)が作成されますので、それをDiffAugment-stylegan2のディレクトリーに移動して下さい。そして、この後の generate() , generate_gif.py の引数をそのファイル名に変更して下さい。
**************************************
先程ダウンロードした学習済みの重みを使って画像生成します。
|
1 2 |
# 学習済みの重みを使って画像生成 generate('network-snapshot-gakki-000500.pkl', num_rows=3, num_cols=5, seed=3) |

さすがに学習画像100枚では生成画像の質は高くないですが、なんとかガッキーを再現しています。
先程ダウンロードした学習済みの重みを使ってGIF動画を作成し interp.gif で保存します
|
1 2 3 |
# 学習済みの重みを使って、GIF動画を作成 !python3 generate_gif.py -r network-snapshot-gakki-000500.pkl -o interp.gif --num-rows=2 --num-cols=3 --seed=1 IPython.display.Image(open('interp.gif', 'rb').read()) |

GIF動画を作成してみました。それにしても、以前は事前学習無しで100枚の画像だけでGANをやるなんて考えれなかったわけですが、技術の進歩は凄いですね。
では、また。














すいません、別の画像群に変えようと思い、URLをその画像のZIPファイルに変更しました
ただ、100-shot-gakki という名称がどこで指定された値かがわからずご教示お願いできますでしょうか。
horieighturtleさん
コメントありがとうございます。
まず、コードにある画像群のダウンロード方法は、Google drive 専用であることにご注意下さい(https://qiita.com/jun40vn/items/66fff06abe48e01e23e3)
以下の3ステップで進めればOKです。
1)指定された方法で、画像群のzipファイルを DiffAugment-stylegan2 の下にダウンロードし、解凍する
2)解凍して出来たフォルダー名でデータセットを作成する(data_dir = dataset_tool.create_dataset(‘***’) の ***にフォルダー名を入れる)
3)解凍して出来たフォルダー名で学習を行う(!python3 run_few_shot.py –dataset=*** –resolution=△△ –total-kimg=□□□ の ***にフォルダー名を入れる)
cedro様こんにちは
このサイトのGANを使って画像生成を行い、生成した画像を一枚づつpngまたはjpg形式で保存する方法はあるでしょうか。
分かり次第ご教示いただけますと幸いに存じ上げます。
hrhrttさん
#学習済みモデルでJPG画像を生成 で、–num-image-tiles {画像結果の数} オプションを付けると生成する画像数を調整できるようです。お試し下さい。
とても興味深かったのでColaboratoryで実行してみました。上から順に実行していき、
学習の実行のところで、下記の様にエラーが出てしまいどうやってもpklファイルが生成されません。
NotImplementedError: Cannot convert a symbolic Tensor (Inputs/minibatch_gpu_in:0) to a numpy array.
対策をご教示いただけましたら幸いです。
gan面白いさん
エラーが復旧しましたので、再度お試しください。
原因:https://qiita.com/jun40vn/items/0f9bd5353197d3f14f3e
ご対応いただきまして、大変ありがとうございます。
オリジナルの画像を100枚用意して学習し、GIF作成まで実行できました!
まだking30程でしか出来ていませんが非常におもしろいです。(Tesla K80で学習に約2h30mかかりました 汗
いつかcolabの時間制約にとらわれないローカル環境のビデオカードでも、構築してみたいです。
gan面白いさん
オリジナル画像でのGAN学習が上手くいったとのこと、おめでとうございます!
cedro様こんにちは
私もとても興味深かったので、「セットアップ」のところで、下記を実行しているコードを使ったのですが
———————————————————-
# gdownアップデート
! pip install –upgrade gdown
———————————————————-
「学習の実行」のところで、下記の様にエラーが出てしまいました。
Google ColabでGPUはK80を使用しています。
dataset.pyの例外が出ているところの値など見てみたのですが、全く見当がつかず、追加で対策がありましたら、教えていただければと思っております。
———————————————————-
Building TensorFlow graph…
Traceback (most recent call last):
File “run_few_shot.py”, line 171, in
main()
File “run_few_shot.py”, line 165, in main
run(**vars(args))
File “run_few_shot.py”, line 94, in run
dnnlib.submit_run(**kwargs)
File “/content/data-efficient-gans/DiffAugment-stylegan2/dnnlib/submission/submit.py”, line 343, in submit_run
return farm.submit(submit_config, host_run_dir)
File “/content/data-efficient-gans/DiffAugment-stylegan2/dnnlib/submission/internal/local.py”, line 22, in submit
return run_wrapper(submit_config)
File “/content/data-efficient-gans/DiffAugment-stylegan2/dnnlib/submission/submit.py”, line 280, in run_wrapper
run_func_obj(**submit_config.run_func_kwargs)
File “/content/data-efficient-gans/DiffAugment-stylegan2/training/training_loop.py”, line 217, in training_loop
G_loss, D_loss, D_reg = dnnlib.util.call_func_by_name(G=G_gpu, D=D_gpu, training_set=training_set, minibatch_size=minibatch_gpu_in, reals=reals_read, real_labels=labels_read, **loss_args)
File “/content/data-efficient-gans/DiffAugment-stylegan2/dnnlib/util.py”, line 256, in call_func_by_name
return func_obj(*args, **kwargs)
File “/content/data-efficient-gans/DiffAugment-stylegan2/training/loss.py”, line 16, in ns_DiffAugment_r1
labels = training_set.get_random_labels_tf(minibatch_size)
File “/content/data-efficient-gans/DiffAugment-stylegan2/training/dataset.py”, line 193, in get_random_labels_tf
return tf.zeros([minibatch_size], dtype=tf.int32)
File “/usr/local/lib/python3.7/dist-packages/tensorflow_core/python/ops/array_ops.py”, line 2338, in zeros
output = _constant_if_small(zero, shape, dtype, name)
File “/usr/local/lib/python3.7/dist-packages/tensorflow_core/python/ops/array_ops.py”, line 2295, in _constant_if_small
if np.prod(shape) < 1000:
File "”, line 6, in prod
File “/usr/local/lib/python3.7/dist-packages/numpy/core/fromnumeric.py”, line 3052, in prod
keepdims=keepdims, initial=initial, where=where)
File “/usr/local/lib/python3.7/dist-packages/numpy/core/fromnumeric.py”, line 86, in _wrapreduction
return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
File “/usr/local/lib/python3.7/dist-packages/tensorflow_core/python/framework/ops.py”, line 736, in __array__
” array.”.format(self.name))
NotImplementedError: Cannot convert a symbolic Tensor (Inputs/minibatch_gpu_in:0) to a numpy array.
Kkさん
ご連絡ありがとうございます。
Numpyのアップデートに伴い、tensorflowとの相性で不具合が発生したようです。
下記を追加し、修正済みです。再度、お試しください。
# numpy 1.19.4のインストール
! pip install numpy==1.19.4
gan面白いさん
このエラーは、#google driveから新垣結衣の画像と学習済みの重みをダウンロード の箇所が正常に動いていないために発生しています。
その原因は、google driveに保存されているファイルの共有リンクからのダウンロードが2/17からgoogle によって一時的に制限されいているからだと思われます。しばらくお待ちください。
cedro様
ありがとうございます。
学習開始できました。感動です。
Numpyのバージョンが原因というのもあるのですね。
自分では気づけなかったと思います。
オリジナルの画像にもチャレンジしていこうと思います。
早くに対応していただき、本当にありがとうございました。