

今回は、Neural Network Libraries のDCGANのサンプルプロジェクトを動かしてみます。
こんにちは cedro です。
先回、Neural Network Console に入っているDCGANのサンプルプロジェクトを改造して顔画像の生成に取り組みました。
実は、DCGANのサンプルプロジェクトは、Neural Network Libraries にもあって、Neural Network Console とは設計仕様が異なっています。
今回は、そのサンプルプロジェクトを動かしてみたいと思います。
まず、サンプルプロジェクトをそのまま動かします
まず、前提条件として、Neural Network Libraries がインストールされている必要があります。まだであれば、こちらを参考にインストールして下さい。
Neural Network Libraries のサンプルプロジェクトは、プログラムには含まれておらず、Web上のここにあります。

この中の、args.py、dcgan.py、mnist_data.py をそれぞれクリックし、表示されたプログラムをエディターにコピーして、自分の適当なフォルダーに同じ名前で保存します。Anacondaには最初からSpyderというエディターで付いているので、これを使うと便利です。

私は、MNISTというフォルダーを作って、そこへ先程の3つのプログラムを保存しました。

Anaconda Navigator からNNabla の仮想環境で、Open Terminal をクリックします。

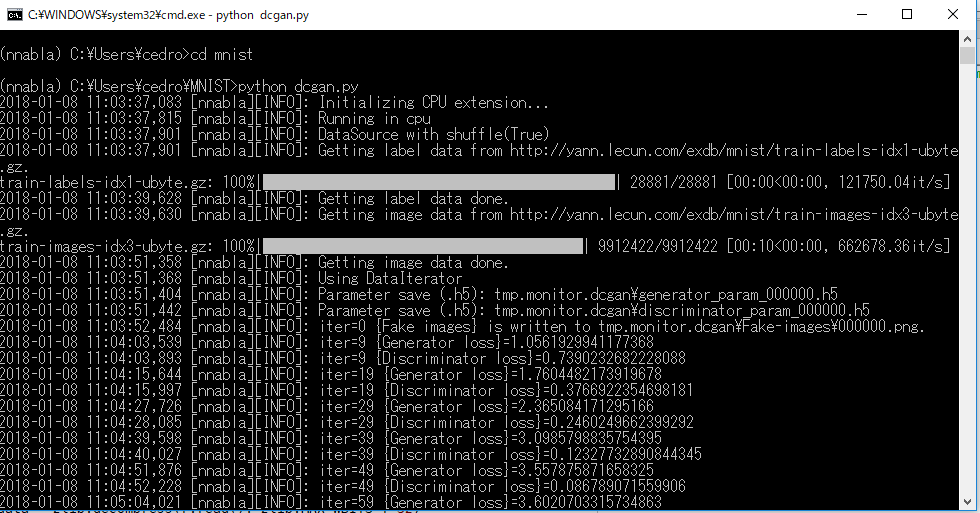
>cd mnist で先程作成したMNISTに移り、>Python dcgan.py を実行すれば、後は自動的に進みます。
Web上にある Mnist のラベルデータと画像データをダウンロードして、学習が開始します。

学習を開始すると、MNISTフォルダーの中には、_pycashe_ というキャッシュフォルダーとtmp.monoitor.dcgan という結果を保存するフォルダーが作られます。
tmp.monoitor.dcgan の中に、画像生成した数字や重みを学習したファイルが収められ、デフォルトでは1,000ステップ毎にそれぞれ新しいファイルが追加されます。

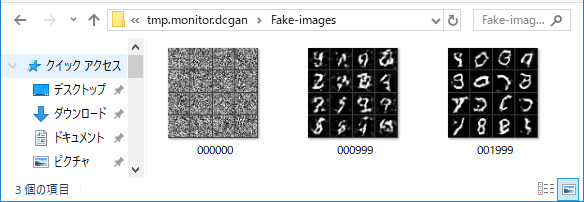
tmp.monoitor.dcgan>Fake-images フォルダーの中に、画像生成した数字が4×4のタイル状に表示され、1,000ステップ毎に追加されて行きます。
常に画像生成の状況がモニターできるのは嬉しいですよね。Neural Network Console では、画像生成した結果は、学習が完了するまで見られないですから。こういうきめ細やかな対応は、Neural Network Libraries ならではというところでしょうか。
さて、Mnistの画像生成は、Neural Network Console でも見ていて新鮮味がないので、早々と切り上げます。
新しいデータセットで画像生成を試してみる
本当は、このサンプルプロジェクトを改造して、直近で作った女性の顔画像のデータセット(カラー64×64)を使った画像生成をしてみたかったのですが、まだ NNabla のプログラムをいじる知識が乏しく、それはあきらめました。
かといって、CIFAR10では、画像がぼやけているので、画像生成にはいい結果が期待できないし、何か良いデータセットはないものかとWebで情報を探していると。


Fashion Mnist というデータセットがありました。これは、モノクロ28×28、10クラスのファッション画像が、学習データ60,000枚、評価データ10,000枚あるものです。


実際の画像です。28×28ピクセルという小さな画像にしては、細部がクッキリしていて完成度が高いです。CIFAR10よりFashion Mnist の方が画質は良いと思います。これなら、画像生成に使えそうです。
中身をみると、0.Tシャツ、1.ズボン、3.ドレス、5.サンダル、7.スニーカー、9.ブーツの識別は容易ですが、2.セーター、4.コート、6.シャツの識別が少し難しそうです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
train-images-idx3-ubyte.gz 訓練セット画像 60,000 26 MBytes http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz train-labels-idx1-ubyte.gz 訓練セット・ラベル 60,000 29 KBytes http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz t10k-images-idx3-ubyte.gz テストセット画像 10,000 4.2 MBytes http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz t10k-labels-idx1-ubyte.gz テストセット・ラベル 10,000 5.0 KBytes http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz |
データは、このURLにあります。
今まで説明した仕様からお気づきになると思いますが、このデータセットは、Mnistと完全互換性があり、そっくりそのまま置き換えが可能です。素晴らしい。
サンプルプロジェクトをFashion Mnist 用に改造して、動かします。
改造します、なんて言いましたが、Mnist と完全互換なので、改造は極めて簡単です。
|
1 2 3 4 5 6 7 8 9 |
if train: image_uri = 'http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz' label_uri = 'http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz' else: image_uri = 'http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz' label_uri = 'http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz' logger.info('Getting label data from {}.'.format(label_uri)) |
Mnist_data.py のラベルデータと画像データのダウンロード先URLを
|
1 2 3 4 5 6 7 8 9 |
if train: image_uri = 'http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz' label_uri = 'http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz' else: image_uri = 'http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz' label_uri = 'http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz' logger.info('Getting label data from {}.'.format(label_uri)) |
先程のURLに入れ替えるだけです。改造と言うのはおこがましいですね。
1つだけ注意事項があります。一度、Mnist データをダウンロードすると、NNabla がMnistデータのキャッシュファイルを作り、以降キャッシュの方を使うプログラムになっているので、キャッシュを削除します。
私の環境では、C:\Users\cedro\nnabla_data\の中に、train-images-idx3-ubyte.gz in cashe (キャッシュファイル)があったので、削除しました。

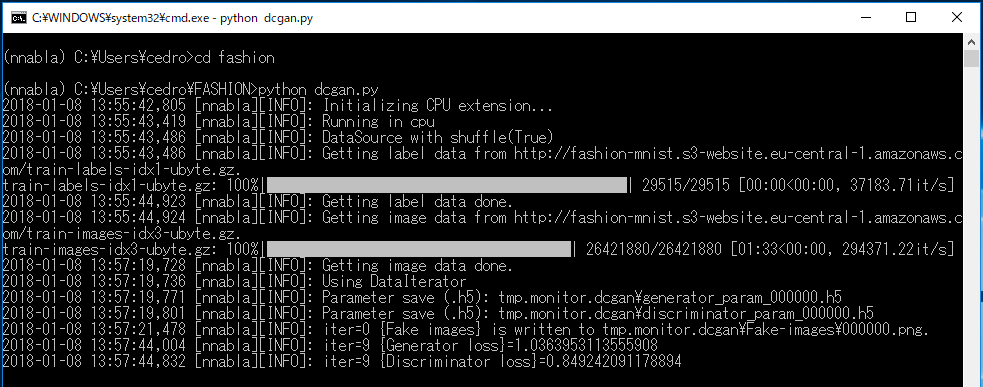
今度は、FASHIONフォルダーを作って、後は先回と同様です。


画像生成状況がこれです。約5時間掛けて、7,000ステップまでやってみました。
1,000ステップで既に画像らしきものが現れており、3,000ステップもすればまあまあな感じになって来ます。学習データが60,000個で、バッチ64個なので、1Epoch=937ステップ。1Epochくらいで片鱗が出るなんて素晴らしい!
結構性能が高いなあと思って、サンプルプロジェクトの構成をみると、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
assert maxh / 4 > 0 with nn.parameter_scope("gen"): # (Z, 1, 1) --> (256, 4, 4) with nn.parameter_scope("deconv1"): d1 = F.elu(bn(PF.deconvolution(z, maxh, (4, 4), with_bias=False))) # (256, 4, 4) --> (128, 8, 8) with nn.parameter_scope("deconv2"): d2 = F.elu(bn(upsample2(d1, maxh / 2))) # (128, 8, 8) --> (64, 16, 16) with nn.parameter_scope("deconv3"): d3 = F.elu(bn(upsample2(d2, maxh / 4))) # (64, 16, 16) --> (32, 28, 28) with nn.parameter_scope("deconv4"): # Convolution with kernel=4, pad=3 and stride=2 transforms a 28 x 28 map # to a 16 x 16 map. Deconvolution with those parameters behaves like an # inverse operation, i.e. maps 16 x 16 to 28 x 28. d4 = F.elu(bn(PF.deconvolution( d3, maxh / 8, (4, 4), pad=(3, 3), stride=(2, 2), with_bias=False))) # (32, 28, 28) --> (1, 28, 28) with nn.parameter_scope("conv5"): x = F.tanh(PF.convolution(d4, 1, (3, 3), pad=(1, 1))) if output_hidden: return x, [d1, d2, d3, d4] return x |
dcgan.py のプログラムの抜粋で、Gneratorの逆畳み込みの構成が書いてあります。
Neural Network Console は7×7が64枚→14×14が32枚の2層構成でしたが、Neural Network Librariesは4×4が256枚→8×8が128枚→16×16が64枚→28×28が32枚と4層構成で、画像枚数も倍増しています。かなり強力な仕様な様です。
ついでに、最近悩んでいた最適化法はどうなっているかチェックすると、Adam で Alpha=0.0002、β1=0.5、weight_decay=0.0001で、論文と一緒でした。
今回、初めてNeural Network Libraries を触ってみましたが、やっぱり痒いところに手が届くようなプログラムにするには、Neural Network Libraries が必要ですね。それと、Neural Network Console を使ってプログラム開発をした後に、何かに実装する時にも、理解しておく必要がありそうです。
少しづつ触って、簡単な改造くらいはできるようにしたいと思います。
では、また。