
今回は、昨年9月にやったDCGANによる顔画像の生成に再びトライしてみたいと思います。
こんにちは cedro です。
昨年9月24日のブログでDCGANによる顔画像の生成をやってみましたが、この頃はディープラーニングを始めたばかりで知識・スキルがほとんどなく、生成された顔画像は心霊写真の域を出ないものでした(笑)。
それから3か月経ち、まだまだ分からないことだらけですが、その頃よりも多少マシになって来たので、再び顔画像の生成にトライしてみたいと思います。
前回の反省点は2つあって、
1)顔画像のデータ数量が圧倒的に少なかった
その頃の画像収集は、ブラウザで画像検索して Snipping Tool(Windows標準で付いているやつ)で顔部分を切り取って収集するというスタイルだったので、データ数量はたったの320個でした。
2)ニューラルネットワークの設計が不十分だった
その頃はニューラルネットワークの設計知識はほぼゼロで、サンプルプロジェクトにある0~9の数字を画像生成するモデルをそのまま流用していました。
このあたりを見直しして、再び顔画像生成にトライしてみます。
画像データを効率的に集める
まず、顔画像収集の効率化のために、Webを色々探したところ、よさげなアプリがありました。
その名は「ImageSpider」。このアプリは、キーワードを入力し、サイズ、種類、ダウンロード枚数などを指定すれば、後は自動で画像をダウンロードしてくれるという優れものです。こちらから、ダウンロードできます。
ダウンロードして解凍すると、こんなフォルダーが作成されます。インストールの必要はなく、フォルダーの中にあるアプリケーションをクリックすればアプリが起動します。
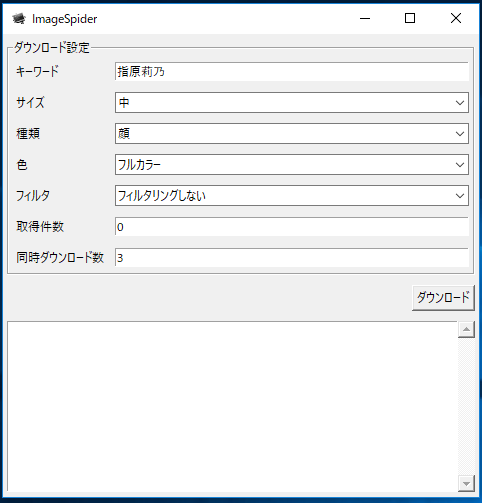
アプリケーションの起動画面です。キーワードに「指原莉乃」と入れて(複数のキーワードでもOK)必要な指定をします。取得件数を「0」にしておけば、最大枚数でダウンロードする指定になります。後は、ダウンロードボタンを押せば、ダウンロードが自動的に行われます。
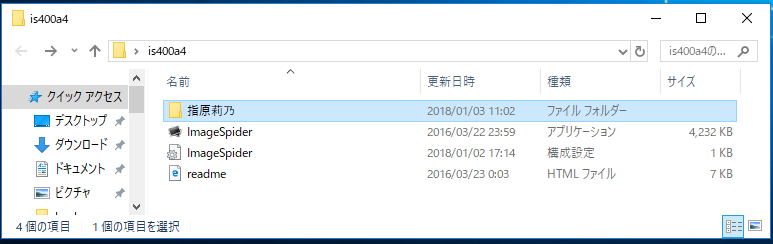
ダウンロードボタンを押すと「指原莉乃」というフォルダーが自動的に作成され、ダウンロードした画像はここに格納されます。便利~!
これを使ってダウンロードするのは本当に楽です。
ただ、自分が名前を良く知っているアイドルを指定してダウンロードすると、自分が頭に描いていた顔よりも相当老けていたり、アイドルの子供が一緒に写っていたりと、時の流れを感じてしまうこともありました(笑)。
そりゃそうですよね、自分も年を取っているのだから、アイドルも年を取ります(笑)。
さて、これで画像収集作業は相当効率化されました。
顔を自動的に切り抜く
顔画像生成の質をあげるためには、収集した画像から顔の部分のみ切り取ってデータを作る必要があります。
この作業を自動化するために、画像処理ライブラリー OpneCVを導入します。(前提条件として、Anacondaがインストールされている必要があります)
ダウンロード先は、こちら。 最新版の opencv_python-3.4.0-cp37-cp37m-win_amd64.whl をダウンロードします。
ANACONDA NAVIGATOR を起動させ、Anaconda3でOpen Termialを開きます。
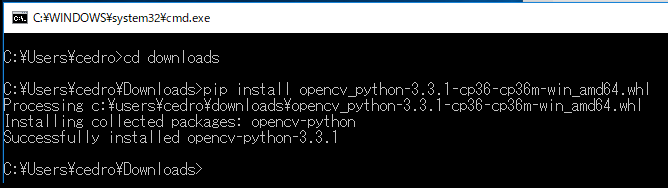
ダウンロードした場所にディレクトリを移し、pip install opencv_python-3.4.0-cp37-cp37m-win_amd64.whl でインストールします。
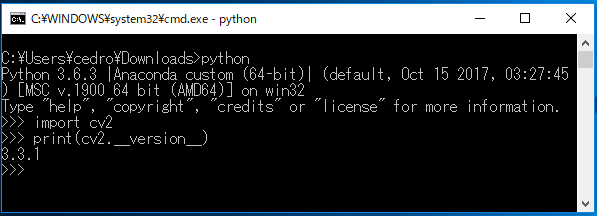
ちゃんとインストールされているか確認します。python を起動し、OpenCVのライブラリーをインポートし、バージョンNo.を表示させてみます。バージョン番号が表示されればOKです。
次に、OpenCVを使った顔画像を切り取るプログラムですが、まだ自分でゼロから作成するスキルはないので、Webで探してみました。その結果「大量の画像から顔の部分のみトリミングして保存する方法」というピッタリな記事を見つけました。
ただ、実際にここに記載のあるプログラムを動かしてみるとエラーが出たり、使い勝手が悪い部分があったので、プログラム修正やファイル追加をしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import cv2 import matplotlib.pyplot as plt import numpy as np import sys, os from PIL import Image #%matplotlib inline #入力ファイルのパスを指定 in_jpg = "./photo/" out_jpg = "./photo_out/" #リストで結果を返す関数 def get_file(dir_path): filenames = os.listdir(dir_path) return filenames pic = get_file(in_jpg) for i in pic: # 画像の読み込み image_gs = cv2.imread(in_jpg + i) # 顔認識用特徴量ファイルを読み込む --- (カスケードファイルのパスを指定) cascade = cv2.CascadeClassifier("./haarcascades\haarcascade_frontalface_alt.xml") # 顔認識の実行 face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(1,1)) # 顔だけ切り出して保存 no = 1; for rect in face_list: x = rect[0] y = rect[1] width = rect[2] height = rect[3] dst = image_gs[y:y + height, x:x + width] save_path = out_jpg + '/' + 'out_(' + str(i) +')' + str(no) + '.jpg' #認識結果の保存 a = cv2.imwrite(save_path, dst) #plt.show(plt.imshow(np.asarray(Image.open(save_path)))) print(no) no += 1 |
これが、顔画像を切り取るプログラムです。修正追加内容をコメントします。
7行目:%matplotlib inline は Jupiter Notebook で使うためのものらしくこのままだとエラーになるので、先頭に#を付けて無効にしています。
43行目:plt.show(plt.imshow(np.asarray(Image.open(save_path)))) は、1つづつ顔画像を切り取る度にストップし、切り取った画像を表示するためのものです。これはこれで悪くないですが、自分としては効率重視で連続して動作して欲しいので、先頭に#を付けて無効にしています。
26行目:cascade = cv2.CascadeClassifier(“./haarcascades\haarcascade_frontalface_alt.xml”) にあるように、今回、haarcascade_frontalface_alt.xml というカスケードファイル(Haar-like特徴分類器)が必要なのですが、自分の環境には見当たりませんでした。
なので、OpenCVの公式サイトから、3.0.0 Win pac をダウンロードし、クリックして出来たフォルダーの opencv \ buid \ etc に、haarcascades フォルダー(カスケードファイルが格納されている)がありますので、これをプログラムと同じフォルダーに置いて対応しました。
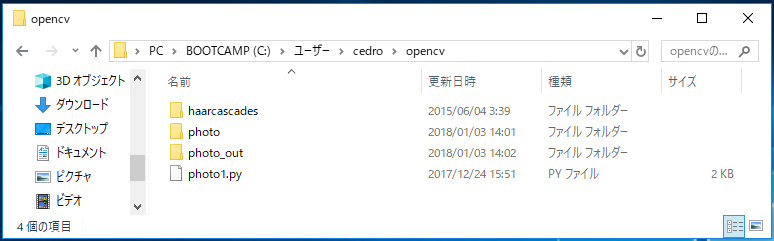
プログラムを、photo1.py で保存します。また、プログラムと同じフォルダーに、photo と photo_out というフォルダーを作成しておきます。
プログラム photo1.py を実行すると、photo フォルダーに入れておいた画像の顔画像を切り取り photo_out フォルダーに格納します。
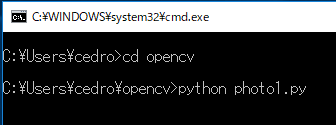
プログラムの実行は、プログラムの入っているディレクトリーに移り、python photo1.py でOKです。
photo_out に格納される顔画像は、一緒に写っている別の人の顔や、顔でないものも結構混じっているので、後で不要なものを削除しなければなりませんが、今までと比べれば断然楽です。
これで顔画像を切り抜く作業も相当効率が上がりました。
サンプルプロジェクトを改造する
Neural Network Console には、mnist_dcgan_with_label.sdcproj という数字の0~9の画像を生成するサンプルプロジェクトが登録されています。
これはConditional GANと呼ばれるモデルで、通常のGANはランダムノイズから画像を生成するため生成される画像を制御することができないのですが、ラベルを付与することにより条件付きモデルに拡張したモデルです。
このサンプルプロジェクトは、数字の0~9の画像を生成する目的には完成度が非常に高いと思います。
しかし、このモデルを今回の顔画像の生成に使おうとすると、ラベル付与機能は余分である一方で、扱う画像サイズが28×28ピクセルのため顔画像を扱うには画質の面で非力さを感じます。
従って、改造方針は「顔画像生成に関して、余分な機能は省き、非力な部分を強化する」で行きたいと思います。
まず、mnist_dcgan_with_label.sdcproj のラベル付与機能を見てみましょう。
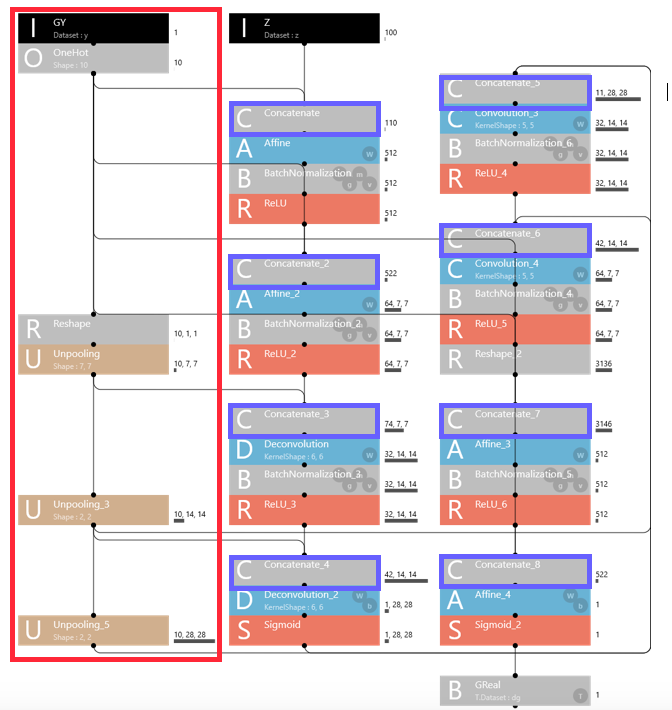
generator の画面です。赤で囲んだ部分が、ラベルを生成する部分です。
Inputでyラベル(0~9)を読み取り 、OneHot でそれに対応して特定の要素だけを1にし、残りは全部0にした10次元ベクトルを作成します。
これを Reshpe で1×1サイズの10枚の画像にしてから、 Unpooling を順次掛けて行くと、7×7、14×14、28×28のサイズの画像が10枚づつ作成されます。各10枚の画像は、いずれも10枚の内1枚だけが1で埋め尽くされ(真っ黒)、残り9枚は0で埋め尽くされています(真っ白)。
これらの画像を、Concatenate(青枠で囲んだレイヤー)で入力画像にプラスすると、重みを学習する Affine、Deconvolution、Convolutionでラベルとして機能します。
例えば、Deconvolution には、7×7サイズの画像64枚と7×7サイズのラベル10枚が入力されます。もし、ラベルの5枚目が1で埋め尽くされている(真っ黒)ならば、yラベル=4という条件で、7×7サイズの画像64枚を学習することになります。
今回の顔画像生成では、このラベル付与機能は使わないので関係するレイヤーをバッサリと切り落とします。
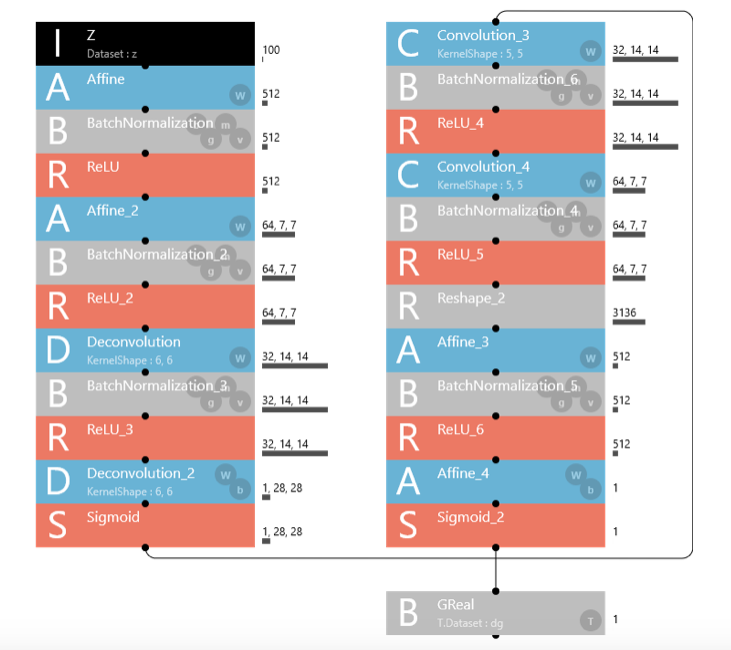
ラベル付与機能を切り落とすと、こんなにシンプルになります。見通しが実に良くなりますね。
しかし見通しが良くなると、今度は逆に非力さもハッキリと見えて来ます。逆畳み込み層(Deconvolution)、畳み込み層(Convolution)が2層づつしかないんです。ここは強化したいところ。
WebでオリジナルのDCGANの設計図を探してみると、こんな感じです。
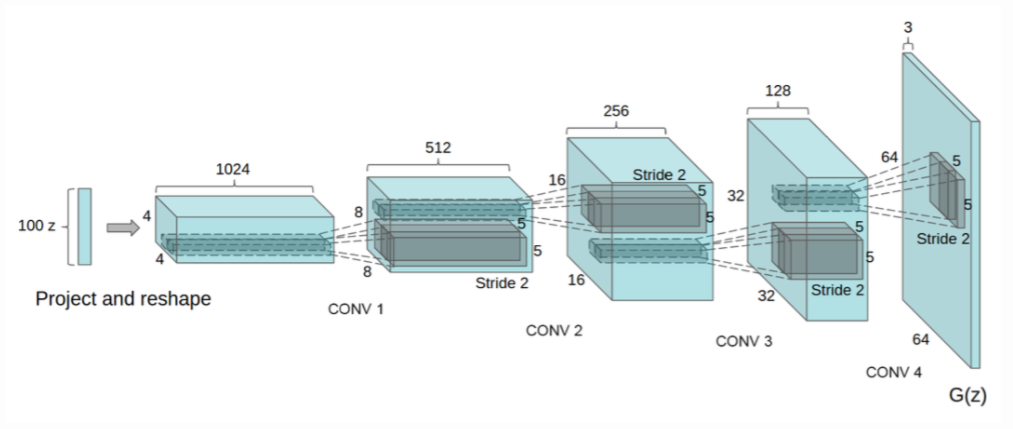
これは、逆畳み込みの部分です(畳み込みの部分はこの逆)。100次元ノイズ → 4×4が1024枚 → 8×8が512枚 → 16×16が256枚 → 32×32が128枚 → カラー64×64 となっていて、4層になっています。
基本的には、この4層構造を採用しようと思いますが、この画像枚数のままでMacbookAir(当然GPU無し)で学習するのは無謀です。学習がいつ終わるのか見当もつきません。
まずは、最小限のセットで試してみようと言うことで、作ったのがこれ。

Generator 画面です。100次元ノイズ → 4×4が128枚 → 8×8が64枚 → 16×16が32枚 → 32×32が16枚 → カラー64×64 ということで、4層構造は同じですが、画像枚数はオリジナルの1/8として、まずは様子を見ることにしました。
mnist_dcgan_with_label.sdcproj はニューラルネットワークが4画面構成(Generator、DiscriminatorFake、DiscriminatorReal、RuntimaGenerator)なので、他の画面も載せておきます。
Discriminator は、Generator と見た目は同じなので割愛します(ハイパーパラメターの設定は微妙に違いまず)。
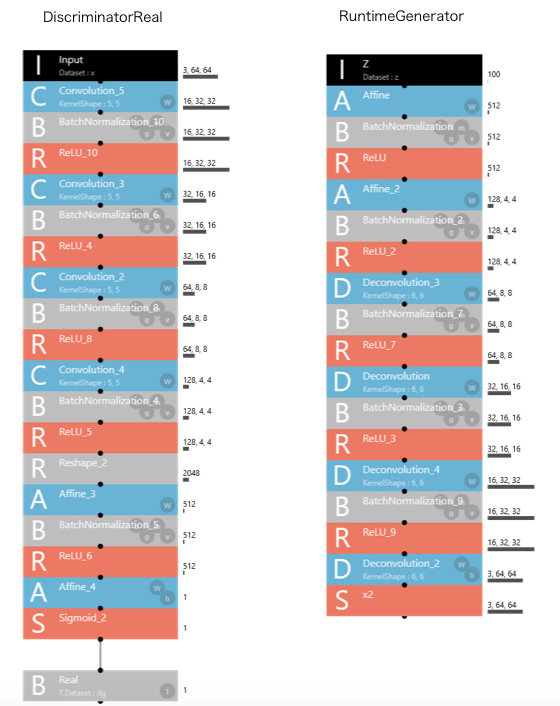
左がDiscriminatorReal、右がRuntimeGeneratorです。
ニューラルネットワークの編集の仕方ですが、基本的に余分な部分をDeleteして、追加する部分はコピペすれば簡単に出来ます。こういう時、Neural Network Console は便利ですね。
注意して欲しいのは、同じレイヤーでも画面によってハイパーパラメーターが変化させてあったりするので、コピペする時は同じ画面で行って下さい。
もう一つは、Generatorの画面で使ってあるレイヤーが他の画面でも使われますが、その時GeneratorのNo.と他の画面のNo.は同じになるようにして下さい(DiscriminatorRealとRuntimeGeneratorに注意)。
画像生成をして見る
DCGANは、学習を進めるのが難しいモデルらしく、Webで調べると学習を上手く進めるための様々な情報があります。当然、気になります。
例えば、最適化法は論文ではAdamでAlpha(学習率)=0.0002、β1=0.5になっているがAlpha=0.0001の方が良いとか、逆畳み込みの最後はReULではなくTanhが良いとか、どうしてもgeneratorよりdiscriminator の方が学習が早く進み過ぎるのでdiscriminator にはBatch Normazilationは入れない方が良いとか。。。。
今までは、 5 Epochくらい廻してみると大体その後の結果が予想できた経験があったので、Webの情報をつまみ食いしては 5 Epoch 廻して様子を見ることを繰り返してみたのですが、中々上手く進展しません。
もう訳が分からなくなって、ハイパーパラメーターやレイヤーの基本構成はサンプルプロジェクトのままで、40 Epoch くらい廻してみると突然顔画像が現れたり、同じ条件でもう一度やると再現しなかったりと、試行錯誤を結構しました。
その結果の代表例だけ記録しておきます。
<学習環境と主な設定条件>
マシン:MacBook Air 1.8GHz Corei5 メモリ8GB
データ:カラー64×64ピクセル
データ数:学習10,368個、評価1152個、合計11,520個(女性タレント217人の顔画像)
Optimizer:Adam、Alpha=0.0005、Beta1=0.5、Epsilon=1E-8
Batch Size:64 (1 Epoch = 162 step)
Max Epoch:100 (16,200 step)
*Webの情報によると、Alpha=0.0001が良いと書いてありましたが、その設定だと最初はValidation Errorは低めに出るのですが、その後ダラダラと悪化の一途をたどり顔画像は生成されなかったので、あえてサンプルプロジェクトと同じ Alpha=0.0005にしています。
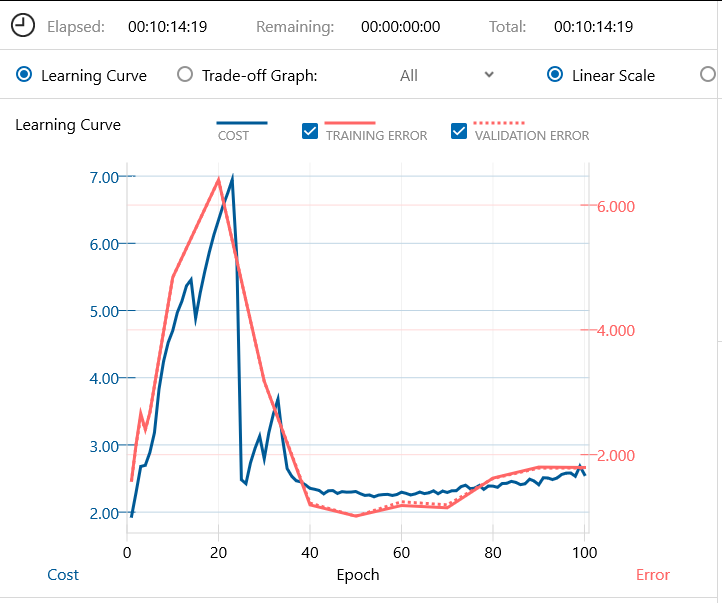
これが代表的な例で、グラフが相当暴れます。この場合でも、20 Epoch あたりでは、もうこのまま発散してしまうのかと思いきや、そこから急速に立て直したという感じです。
何度かやってみると、40 Epoch(6,480 step) でたまに顔画像が現れる場合がありますが再現性は低いです。100 Epoch(16,200 step) では必ず顔画像を生成します。しかしながら、200 Epoch(32,400 step) まで廻すと、ただの砂嵐画像に戻ってしまいました。

100 Epoch廻して生成した画像がこちらです。このあたりが今回作成したニューラルネットワークの到達点という感じでしょうか。
さすがに、昨年9月の心霊写真からは改善はされましたが、顔画像としてはまだまだ不十分ですね。
次のステップは、各4層ある逆畳み込み層(Deconvolution)と畳み込み層(Convolution)の画像枚数を倍増させて、画像の質を上げることですが。。。。
長くなりましたので、とりあえず、それはまた別の機会とします。
では、また。













親切な解説、ありがとうございました。
少し理解した気がします。ここで一旦論文に戻ります。
そして、申し訳ございませんが、また一つお願いがあります。
Cedroさんの例題ファイルもどこかに公開して頂けますか?
例えば、Githubを利用すると、このブログの人気も更にアップすると思います。
よろしくお願いします。
Choeさんへ
良いご意見ありがとうございます。
データセットは、著作権法の縛りがあるので難しいですが、プロジェクトファイルはGithubに上げることは問題ないですね。
次回投稿から考えてみます。
ご返事ありがとうございました。
すみません。一つ教えてください。
Generator, DiscriminatorFake, DiscriminatorRealのネットワークの最後にBinary Cross Entropyの設定で質問があります。
恐らく、各ネットワークが作り出したイメージを、それぞれのデータに合わせてBinary Cross Entropyを求めることだと理解しています。
そのブロックを中を見ると (Generatorの場合)
Name : GReal
Input : 1
T.Dataset : dg
T.Generator : Constant
..
になっていますが、ここでT.Dataset : dgとは何を意味していますか?
お手数をかけますが、よろしくお願いします。