

1.はじめに
今回ご紹介するのは、最近画像生成でよく使われているDiffusion Model を使った、低画質の顔画像を高画質化する DifFace という技術です。
*この論文は、2022.12に提出されました。
2.DifFaceとは?
下記の様に、高画質と低画質の顔画像のペアをDiffusion Modelに学習させることによって、低画質の顔画像から高画質の顔画像を予測します。

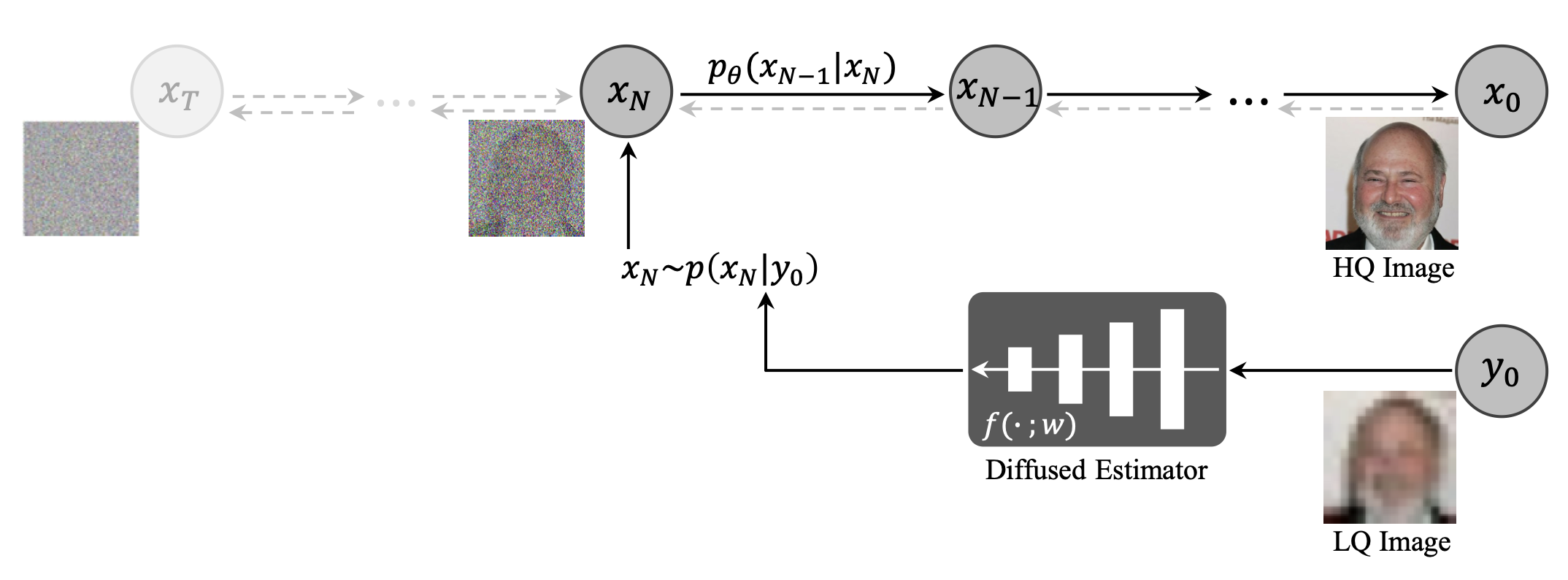
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
最初に、MinicondaというPython環境をインストールします。インストール後、自動的にリセットが掛かるため「セッションがクラッシュしました」と表示されますが問題ありません。
|
1 2 3 4 5 |
#@title **Install Miniconda3** # https://github.com/conda-incubator/condacolab !pip install -q condacolab import condacolab condacolab.install_miniconda() |
次に、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#@title **Set up** # Clone Repository ! git clone https://github.com/cedro3/DifFace.git %cd DifFace # Viewing the list of your environments !conda info --envs # Updating the environment !conda env update -n base -f /content/DifFace/environment.yaml print("Done...") # Viewing the list of your environments !conda info --envs #difine function import cv2 import matplotlib.pyplot as plt from IPython.display import clear_output import os import shutil from pathlib import Path def display(img1, img2): fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 2, 1) plt.title('Input', fontsize=16) ax1.axis('off') ax2 = fig.add_subplot(1, 2, 2) plt.title('DifFace', fontsize=16) ax2.axis('off') ax1.imshow(img1) ax2.imshow(img2) def imread(img_path): img = cv2.imread(img_path) if img.ndim > 3: img = img[:, :, :3] img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) return img def reset_folder(path): if os.path.isdir(path): shutil.rmtree(path) os.makedirs(path,exist_ok=True) |
最初に、inference_difface.py を使用し、引数に –aligned を加えてクロップした顔を高画質化してみます。入力画像は testdata/cropped_facesフォルダに入っているものを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#@title **Cropped Image Demo** """ !python inference_difface.py --aligned --in_path [image folder/image path] --out_path [result folder] --gpu_id [gpu index] """ !python /content/DifFace/inference_difface.py \ --aligned \ --in_path /content/DifFace/testdata/cropped_faces \ --out_path /content/result_aligned \ --gpu_id 0 im_path_list = sorted([x for x in Path("/content/DifFace/testdata/cropped_faces").glob("*.png")]) out_dir = Path("/content/result_aligned/restored_faces") for im_path_in in im_path_list: im1 = imread(str(im_path_in)) im_path_out = out_dir / im_path_in.name im2 = imread(str(im_path_out)) display(im1, im2) |




最後の3枚のみを表示しています。
次に、inference_difface.py を使用し、背景も含めて画像全体を高画質化してみます。入力画像は、testdata/whole_imgs フォルダに入っているものを使用します。また、-t や -s で、パラメータを指定できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
#@title **Whole Image Demo** """ !python inference_difface.py -t 200 # The whole length of the pretrained diffusion model, default 250 -s 80 # started timestpes for DifFace, default 100 --in_path [image folder/image path] --out_path [result folder] --gpu_id [gpu index] """ !python /content/DifFace/inference_difface.py \ -t 200 -s 80 \ --in_path /content/DifFace/testdata/whole_imgs/ \ --out_path /content/result_unaligned \ --gpu_id 0 in_dir = "/content/DifFace/testdata/whole_imgs" im_path_list = sorted([x for x in Path(in_dir).glob("*.png")]) im_path_list.extend([x for x in Path(in_dir).glob("*.jpg")]) out_dir = Path("/content/result_unaligned/restored_image") for im_path_in in im_path_list: im1 = imread(str(im_path_in)) im_path_out = out_dir / im_path_in.name im2 = imread(str(im_path_out)) display(im1, im2) |





最後の3枚のみ表示しています。
それでは、オリジナル画像でやってみましょう。pic フォルダに自分の用意した画像をアップロードして下さい。そして、pic にファイル名を1つ指定して実行します。とりあえず、picフォルダには、001.jpg〜005.jpgまでの5枚の画像がサンプルとして入っていますので、このサンプルで動かしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#@title **Whole Image Original** pic = '001.jpg' #@param {type:"string"} input_folder = 'testdata/whole_imgs_original' result_folder = 'results' reset_folder(input_folder) reset_folder(result_folder) img = cv2.imread('pic/'+pic) cv2.imwrite(input_folder+'/'+pic, img) !python /content/DifFace/inference_difface.py \ -t 200 -s 80 \ --in_path $input_folder \ --out_path $result_folder \ --gpu_id 0 clear_output() img1 = imread(input_folder+'/'+pic) img2 = imread(result_folder+'/restored_image/'+pic) display(img1,img2) |


以下を実行すると高画質化した画像をダウンロードできます。
|
1 2 3 |
#@title **download file** from google.colab import files files.download(result_folder+'/restored_image/'+pic) |
もう1つやってみましょうか。今度は、pic=004.jpgで指定して実行します。


こういったタスクを Blind face Restoration(ブラインドフェイス復元)というのですが、この分野でも Diffusion Model が使われ始めました。今後さらに、この手法が進化して行くと思います。
では、また。
(オリジナルgithub)https://github.com/zsyOAOA/DifFace