

1.はじめに
今回ご紹介するのは、画像生成AIのプロンプトを短くし、かつ画像とプロンプトの類似度を高めるHard Prompts Made Easy という技術です。
2.Hard Prompts Made Easyとは?
従来の画像生成AIのプロンプトは、解釈可能なトークンのみで表されるため、トークン数は多くなり、画像とプロンプトの類似度を上げるためには試行錯誤や直感が必要でした。
一方、Hard Prompts Made Easy(PEZ)は、解釈可能なトークンの間に解釈出来ない連続値トークンを埋め込むことによって、少ないトークン数ですみ、画像とプロンプトの類似度を上げるために数理的手法を用いることが出来ます。
下記は、PEZで画像と類似度の高いプロンプトを求め、そのプロンプトで再度画像を生成した例です。nucやclなどの解釈出来ないトークンが使われトークン数は少ないですが、元画像と類似度の高い画像が生成出来ていることが分かります。


この技術を使うと、どんなことが出来るのか見て行きましょう。1つ目は、プロンプトの蒸留です。これはプロンプトのトークン数を減らすことです。
2つ目は、スタイル転送です。左側のTarget Style4枚の画像に類似度の高いプロンプト[A]を求めて、A Tiger in the style of [A] という様なプロンプトにするだけで、スタイル転送が出来ます。


3つ目は、イメージの合成です。左側の Separate Generation(2枚の画像)に類似度の高いプロンプトをそれぞれ求め、その2つのプロンプトを結合するとConcatenated Generation(合成したイメージ) を得ることが出来ます。


3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
#@title **Setup** # install library & copy github code ! pip install transformers==4.23.1 sentence-transformers==2.2.2 ftfy==6.1.1 mediapy==1.1.2 diffusers==0.11.1 ! git clone https://github.com/cedro3/hard-prompts-made-easy.git %cd hard-prompts-made-easy # import library import torch import open_clip import mediapy as media from optim_utils import * import argparse # load setting args = argparse.Namespace() args.__dict__.update(read_json("sample_config.json")) args # load CLIP model device = "cuda" if torch.cuda.is_available() else "cpu" model, _, clip_preprocess = open_clip.create_model_and_transforms(args.clip_model, pretrained=args.clip_pretrain, device=device) tokenizer = open_clip.tokenizer._tokenizer token_embedding = model.token_embedding preprocess = clip_preprocess # load Diffusion model from diffusers import DPMSolverMultistepScheduler, StableDiffusionPipeline model_id = "stabilityai/stable-diffusion-2-1-base" scheduler = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler") pipe = StableDiffusionPipeline.from_pretrained( model_id, scheduler=scheduler, torch_dtype=torch.float16, revision="fp16", ) pipe = pipe.to(device) image_length = 512 |
1番目は、画像と類似度の高いpromptを求めます。
最初に、picで01.jpgを指定して画像を読み込みます。自分の用意した画像を使いたい場合は、picフォルダにその画像をアップロードして下さい。なお、画像は内部で512×512で扱われますので正方形に近い画像が良いです。
|
1 2 3 4 5 |
#@title **Load image** pic = '01.jpg' #@param {type:"string"} pic_path = 'pic/'+pic orig_images= Image.open(pic_path).resize((512, 512)) media.show_images([orig_images]) |


これが読み込んだ画像です。
次に、この画像と類似度の高いpromptを求めます。
|
1 2 |
#@title **Optimize Prompt** learned_prompt = optimize_prompt(model, preprocess, args, device, target_images=[orig_images]) |
best cosine sim: 0.5095803141593933
best prompt: paoloweymouth bournemouth prismdaughters imports onceuponpgatbath pony artiste portray sargent impressionist gilleonceupon
ログの最後に、最も類似度の高いpromptが表示されます。このpromptから画像を生成してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#@title **Generate Image** prompt = learned_prompt num_images = 4 guidance_scale = 9 num_inference_steps = 25 images = pipe( prompt, num_images_per_prompt=num_images, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, height=image_length, width=image_length, ).images print(f"prompt: {prompt}") media.show_images(images) |


最初に読み込んだ画像に近いイメージで画像が生成できることが分かります。
2番目は、promptの蒸留です。
最初に、長いpromptを入力します。ここでは、”realistic car 3 d render sci – fi car and sci – fi robotic factory structure in the coronation of napoleon painting and digital billboard with point cloud in the middle, unreal engine 5, keyshot, octane, artstation trending, ultra high detail, ultra realistic, cinematic, 8 k, 1 6 k, in style of zaha hadid, in style of nanospace michael menzelincev, in style of lee souder, in plastic, dark atmosphere, tilt shift, depth of field” と入力します。
|
1 2 3 |
#@title **Load prompt** target_prompt = "realistic car 3 d render sci - fi car and sci - fi robotic factory structure in the coronation of napoleon painting and digital billboard with point cloud in the middle, unreal engine 5, keyshot, octane, artstation trending, ultra high detail, ultra realistic, cinematic, 8 k, 1 6 k, in style of zaha hadid, in style of nanospace michael menzelincev, in style of lee souder, in plastic, dark atmosphere, tilt shift, depth of field" #@param {type:"string"} print(target_prompt) |
次に、この長いpromptで画像を生成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#@title **Generate Image** prompt = target_prompt num_images = 4 guidance_scale = 9 num_inference_steps = 25 images = pipe( prompt, num_images_per_prompt=num_images, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, height=image_length, width=image_length, ).images print(f"prompt: {prompt}") media.show_images(images) |


こんな未来の自動車工場の風景が生成されます。
次に、このpromptを蒸留(短縮)してみましょう。
|
1 2 |
#@title **Optimize Prompt** learned_prompt = optimize_prompt(model, preprocess, args, device, target_prompts=[target_prompt]) |
best cosine sim: 0.8279194235801697
best prompt: realistic surrealism futuristic futuristic iot dereltechnological car factory individually visualization renderrender depicting destined production
ログの最後に、最も類似度の高いpromptが表示されます。最初と比べてかなり短縮化されていますね。それでは、このpromptから画像を生成してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#@title **Generate Image** prompt = learned_prompt num_images = 4 guidance_scale = 9 num_inference_steps = 25 images = pipe( prompt, num_images_per_prompt=num_images, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, height=image_length, width=image_length, ).images print(f"prompt: {prompt}") media.show_images(images) |

最初に読み込んだ長いpromptと似たイメージの画像を生成できるていることが分かります。
3番目に、negativepromptへの活用です。
最初に、picで02.jpgを指定して画像を読み込みます。自分の用意した画像を使いたい場合は、picフォルダにその画像をアップロードして下さい。なお、画像は内部で512×512で扱われますので正方形に近い画像が良いです。
|
1 2 3 4 5 |
#@title **Load image** pic = '02.jpg' #@param {type:"string"} pic_path = 'pic/'+pic orig_images= Image.open(pic_path).resize((512, 512)) media.show_images([orig_images]) |

これが読み込んだ画像です。
次に、この画像を生成するpromptを求めます。
|
1 2 |
#@title **Optimize Prompt** learned_prompt = optimize_prompt(model, preprocess, args, device, target_images=[orig_images]) |
best cosine sim: 0.41112083196640015
best prompt: upright valitonne sustainable lawn located resurg

ログの最後に、最も類似度の高いpromptが表示されます。それでは、これをnegative promptとして、”two dogs are running” という文から画像を生成してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
#@title **Generate Image** prompt = "two dogs are running" #@param {type:"string"} negative_prompt = learned_prompt num_images = 4 guidance_scale = 9 num_inference_steps = 25 seed = 0 print(f"prompt: {prompt}") print(f"negative prompt: {negative_prompt}") set_random_seed(seed) images = pipe( prompt, num_images_per_prompt=num_images, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, height=image_length, width=image_length, ).images print(f"without negative prompt:") media.show_images(images) set_random_seed(seed) images = pipe( prompt, num_images_per_prompt=num_images, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, height=image_length, width=image_length, negative_prompt=negative_prompt, ).images print(f"with negative prompt:") media.show_images(images) |

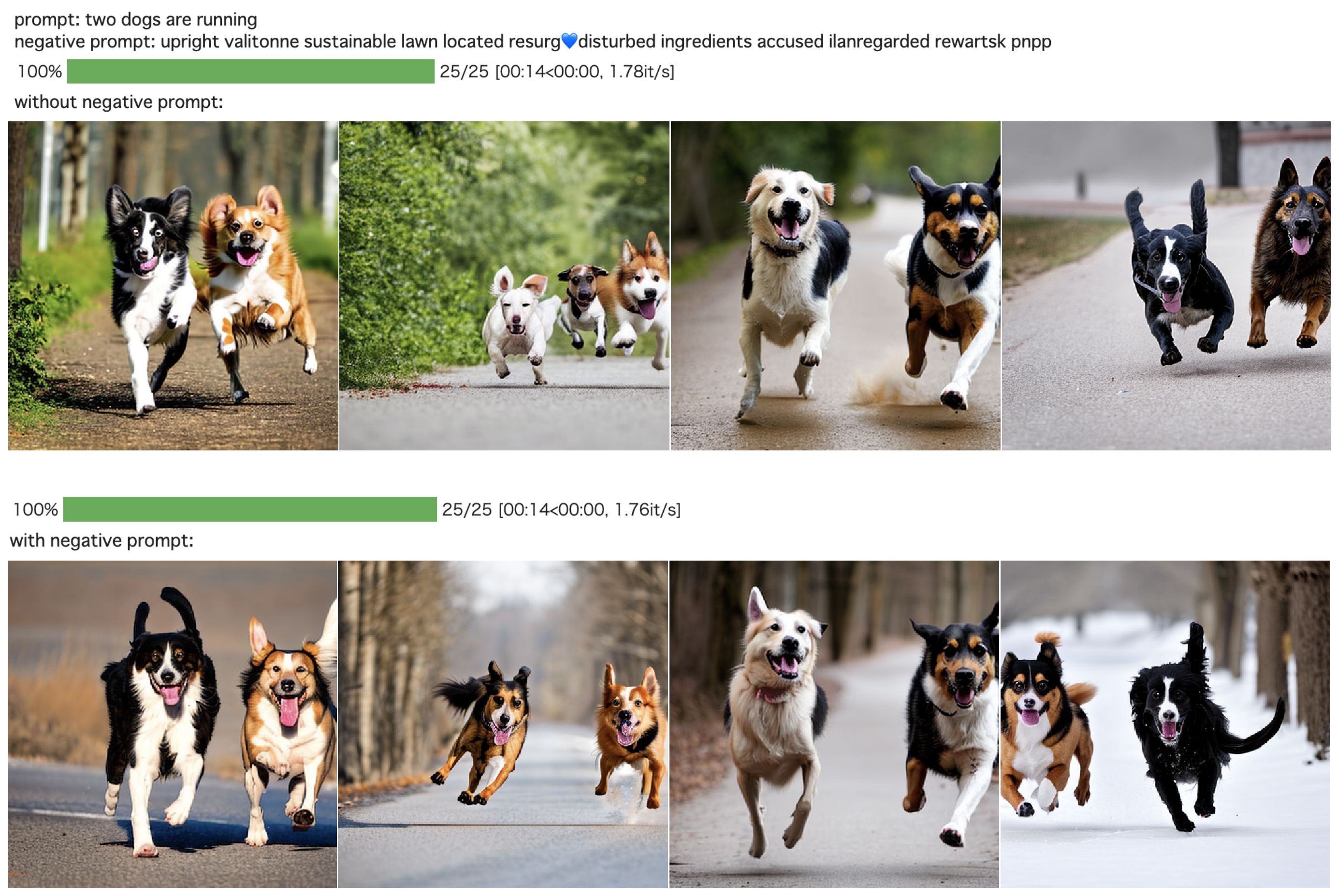
上段がnegative prompt無しの場合、下段がnegative prompt有り場合です。上手くnegative promptが機能していることが分かります。
4番目に、スタイル転送です。
最初に、pic_listで ’03.jpg’, ’04.jpg’, ’05.jpg’, ’06.jpg’というような形で画像を指定して読み込みます。自分の用意した画像を使いたい場合は、picフォルダにその画像をアップロードして下さい。なお、画像は内部で512×512で扱われますので正方形に近い画像が良いです。
|
1 2 3 4 5 6 7 8 |
#@title **Load image** pic_list = '03.jpg', '04.jpg', '05.jpg', '06.jpg' #@param {type:"string"} orig_images =[] for pic in pic_list: pic_path ='pic/'+pic orig_image = Image.open(pic_path).resize((512, 512)) orig_images.append(orig_image) media.show_images(orig_images) |


これが読み込んだ画像です。
次に、この4つの画像に類似度の高いpromptを求めます。
|
1 2 |
#@title **Optimize Prompt** learned_prompt = optimize_prompt(model, preprocess, args, device, target_images=orig_images) |
best cosine sim: 0.4465205669403076
best prompt: galaxies inspired virgo cruelty anime stil puja glos wallis inktober dday inspiration blogtutorbeautiful hwa
ログの最後に、最も類似度の高いpromptが表示されます。それでは、このpromptをスタイルとして画像を生成してみましょう。
main_prompt に ” the streets of Paris”(パリの通り)と入力すると、内部で” the streets of Paris in the style of + 先程のprompt” というpromptから画像を生成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#@title **Generate Image** main_prompt = 'the streets of Paris' #@param {type:"string"} prompt = main_prompt + ' in the style of ' + learned_prompt num_images = 4 guidance_scale = 9 num_inference_steps = 25 images = pipe( prompt, num_images_per_prompt=num_images, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, height=image_length, width=image_length, ).images print(f"prompt: {prompt}") media.show_images(images) |


スタイル転送が出来ていることが分かります。これを活用すると、今までDream Boothでやっていたことの一部が代替出来ます。
プロンプトエンジニアリングの世界は、まだまだ進化して行きそうです。では、また。