

1.はじめに
今まで、少数の学習データで顔画像のスタイル変換を行う場合、モデルに目の形や線の太さなどの詳細を学習させることは困難でした。JoJoGANは、この問題点を改善したモデルです。
*この論文は、2021.12に提出されました。
2.JoJoGANとは?
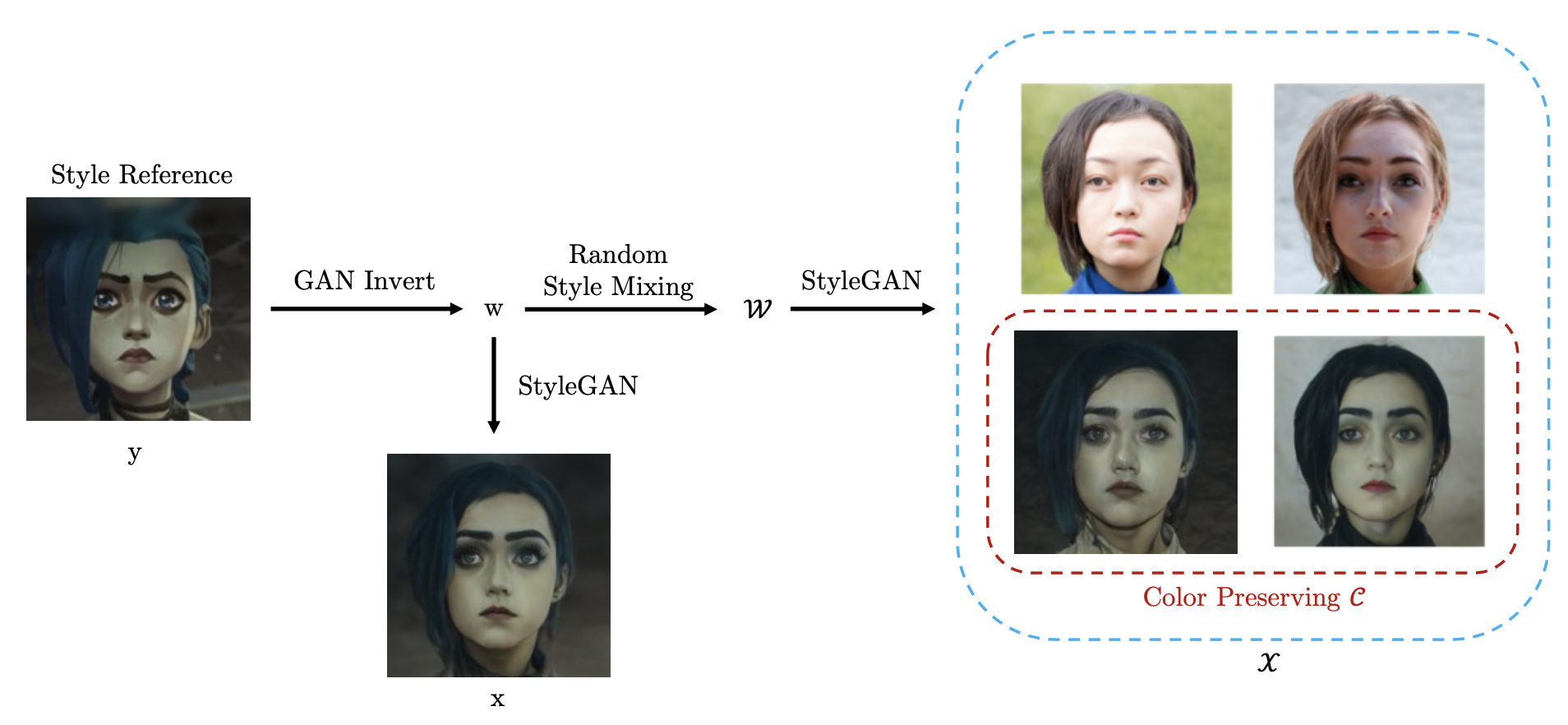
スタイル変換モデルの学習には、大量のペアトレーニングデータセットを使うことが最適ですが、それには多大なコストが必要です。JoJoGANのポイントは、下記の様に1枚のスタイル参照画像から近似ペアトレーニングデータセットを生成して学習に利用することです。
まず、スタイル参照画像yをGAN反転し潜在変数wを取得します。但し、ここで使用するGAN反転器(e4eを使用)は実写でトレーニングされているため、潜在変数wで生成される画像はxは、yを近似したものであることに注意して下さい。
次に、この潜在変数wにランダム・スタイル・ミキシング(特定レイヤの潜在変数に乱数をミックスする)を行うことで、様々なペアトレーニングセットXを生成することが出来ます。そして、Xには同じカラープロファイルcが含まれています。

それでは、早速コードを動かしてみましょう。
3.コード(学習済みモデル)
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。なお、今回コードは非表示にしてありますので、見たい場合は「コードの表示」をクリックして下さい。
まず、セットアップを行います。


次に、スタイル変換をかけるためのサンプル画像を表示します。自分で用意した画像を使う場合は、その画像を事前にpicフォルダにアップロードしておいて下さい。




次に、サンプル画像をalign(所定の位置で顔画像を切り出す)し、潜在変数を取得します。




それでは、学習済みモデルでスタイル変換を行ってみましょう。pretrained で学習済みモデルの選択(8種類)、preserve_color で変換前後の色を保持するかの選択を行います。ここでは、pretrained は jojo、preserve_color はチェックで実行します。変換結果は results フォルダに保存されます。




せっかくですので、出力画像を見やす形に編集して、動画にしてみましょう。作成した動画は output.mp4 で保存されます。




サンプル画像のベースは残しつつ、承太郎の特徴が上手く適用されています。
4.コード(ワンショット学習)
今度は、ワンショット学習をやってみましょう。まず、スタイル画像のサンプルを表示します。自分の用した画像を使いたい場合は、その画像を事前にstyle_imagesフォルダにアップロードしておいて下さい。




次に、スタイル画像をalign(所定の位置で顔画像を切り出す)し、潜在変数を取得します。names にリスト形式で画像を選択します。1枚だけ選択しても良いですし、同様なスタイルを複数枚選択してもOKです。ここでは、001.jpgを1枚だけ選択し、ポルナレフGANを作ってみましょう!




次に、このデータを元にStyleGANをファインチューニングします。alpha で変換度合、preserve_color で変換前後の色保持の有無、num_iter で学習回数を設定します。ここでは、alphaは1.0、preserve_colorはチェック、num_iterは200で実行します。学習したパラメータは、model.pthで保存されます。


それでは、学習したパラメータ model.pthを読み込んで、サンプル画像をスタイル変換してみましょう。変換結果は results フォルダに保存されます。




せっかくですので、出力画像を見やす形に編集して、動画にしてみましょう。作成した動画は output.mp4 で保存されます。



たった1枚の画像からポルナレフGANが出来ました!
では、また。
(オリジナルgithub)https://github.com/mchong6/JoJoGAN
(twitter投稿)