

今回は、Keras のサンプルプログラム cifar10_cnn.pyを改造して、ImageDataGenerator(画像水増し機能)の使い方を理解します。
こんにちは cedro です。
Webで Keras について検索すると、サンプルプログラムは公式版の他にも、色々な方々が作ったものが沢山見つかりますし、個別の機能を紹介するブログは山ほどあります。
そういう環境の中であれば、Keras の習得はWebの情報を元にサンプルプログラムを改造して動かしてみることが一番効果的ではないかと考え、最近サンプルプログラムを色々改造しています。
今回改造するのは、cifar10_cnn.py という、10クラス(飛行機〜トラックまで)の画像データセット Cifar10 をCNN(畳み込みニューラルネットワーク)で分類するサンプルプログラムです。
実は、このプログラムの中には、ImageDataGenerator(画像水増し機能)が組み込まれていて、画像データが少ない場合のディープラーニングにどれだけ使えるのか試してみたいと思っています。
ということで、今回は、Keras のサンプルプログラム cifar10_cnn.py を改造して、ImageDataGenerator(画像水増し機能)の使い方を理解します。
オリジナルデータセットを用意する
データセットが cifar10 のままでは面白くないので、有名人の顔画像を集めた CelebA データセットと属性ファイルを利用して、オリジナルのデータセットを作成します。(詳細は、8/18のブログ「CelebAデータセットから好みのデータセットを抽出する」を参照下さい。)

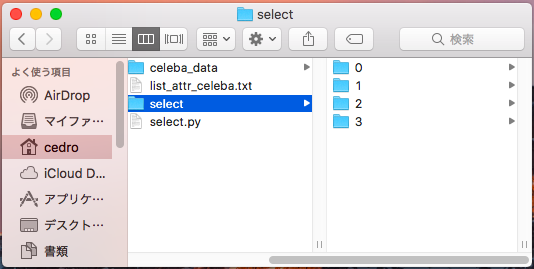
celeba_data に CelebAの画像データを格納します。抽出したデータセットを格納するために select フォルダーを作り、その下に「0」〜「3」のフォルダーを作ります。list_attr_celeba.txt は属性ファイル。select.py がプログラムです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from PIL import Image ### 画像処理ライブラリPillow をインポート count = 0 with open("list_attr_celeba.txt","r") as f: ### 属性ファイルを開く for i in range(50000): ### 先頭から50000枚分処理する line = f.readline() ### 1行データ読み込み line = line.split() ### データを分割 count = count+1 print(count) ### 何枚目を処理しているかスクリーン表示 if line[21]=="1" and line[32]=="1": ### 笑う男 image = Image.open("./celeba_data/"+line[0]) ### 該当画像読み込み image.save("./select/0/"+line[0]) ### 「0」フォルダーに保存 elif line[21]=="1" and line[32]=="-1": ### 笑わない男 image = Image.open("./celeba_data/"+line[0]) image.save("./select/1/"+line[0]) elif line[21]=="-1" and line[32]=="1": ### 笑う女 image = Image.open("./celeba_data/"+line[0]) image.save("./select/2/"+line[0]) elif line[21]=="-1" and line[32]=="-1": ### 笑わない女 image = Image.open("./celeba_data/"+line[0]) image.save("./select/3/"+line[0]) |
select.py の中身です。「笑う男」、「笑わない男」、「笑う女」、「笑わない女」の4種類からなる「性別×笑い」データセットを作成します。


作成したデータセットです。各フォルダーの枚数は、7,500枚に揃えました。従って、全体で 7,500枚×4種類=30,000枚です。
プログラムを改造します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from __future__ import print_function import keras from keras.datasets import cifar10 from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.preprocessing.image import array_to_img, img_to_array, list_pictures, load_img ### 追加 from sklearn.model_selection import train_test_split ### 追加 from PIL import Image ### import os import numpy as np ### import glob ### |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# The data, split between train and test sets: #(x_train, y_train), (x_test, y_test) = cifar10.load_data() ### folder = ["0","1","2","3"] image_size = 32 x = [] y = [] for index, name in enumerate(folder): dir = "./data/" + name files = glob.glob(dir + "/*.png") ### フォルダー内の画像名を全て取得 **** for i, file in enumerate(files): ### 1つづつ画像を処理する image = Image.open(file) ### 画像を開く image = image.convert("RGB") ### カラーで読み込む image = image.crop((25,45,153,173)) ### 128×128にクロップ image = image.resize((image_size, image_size)) ### 32×32にリサイズ data = np.asarray(image) ### 配列に格納 x.append(data) ### 画像配列を格納 y.append(index) ### フォルダー名を格納 x = np.array(x) ### numpy配列の形式に変更 y = np.array(y) ### numpy配列の形式に変更 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) ### 学習:評価=8:2 #x_train = np.reshape(x_train,[-1, image_size, image_size, 3]) #x_test = np.reshape(x_test,[-1, image_size, image_size, 3]) |
毎度おなじみの、オリジナルデータセットの読み込み部分です。画像データは、オリジナル178×218を読み込み、センターから128×128でクロップして、32×32にリサイズしています。30,000枚のデータを学習用24,000枚、評価用6,000枚に使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
### Plot accuracy & loss import matplotlib.pyplot as plt acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(acc) + 1) #plot accuracy plt.plot(epochs, acc, "bo", label = "Training acc" ) plt.plot(epochs, val_acc, "b", label = "Validation acc") plt.title("Training and Validation accuracy") plt.legend() plt.savefig("acc.png") plt.close() #plot loss plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.plot(epochs, val_loss, "b", label = "Validation loss") plt.title("Training and Validation loss") plt.legend() plt.savefig("loss.png") plt.close() ### plot Confusion Matrix import pandas as pd import seaborn as sn from sklearn.metrics import confusion_matrix def print_cmx(y_true, y_pred): labels = sorted(list(set(y_true))) cmx_data = confusion_matrix(y_true, y_pred, labels=labels) df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels) plt.figure(figsize = (10,7)) sn.heatmap(df_cmx, annot=True, fmt="d") ### ヒートマップの表示仕様 plt.title("Confusion Matrix") plt.xlabel("predict_classes") plt.ylabel("true_classes") plt.savefig("c_matrix.png") plt.close() predict_classes = model.predict_classes(x_test[1:10000,], batch_size=32) ### 予測したラベルを取得 true_classes = np.argmax(y_test[1:10000],1) ### 実際のラベルを取得 print(confusion_matrix(true_classes, predict_classes)) print_cmx(true_classes, predict_classes) |
プログラムの最後に、ロス・精度の時系列グラフ、Confusion Matrix を表示する部分を追加します(詳細は、8/30ブログ「Keras MLPを改造して定番パターンを勉強する」を参照)。
これに伴い、改造前プログラムの72行目の model.fit を history = model.fit に、114行目の model.fit_generator を history = model.fit_generator に変更します。こうすることで、history ディレクトリにロス・精度等のデータが記録され、後でこれを利用してグラフを作ることが出来ます。


改造したプログラムを、celeba_cnn.py で保存し、同じフォルダーに先ほど作ったデータセットのselect フォルダーを格納します。では、動かしてみます。

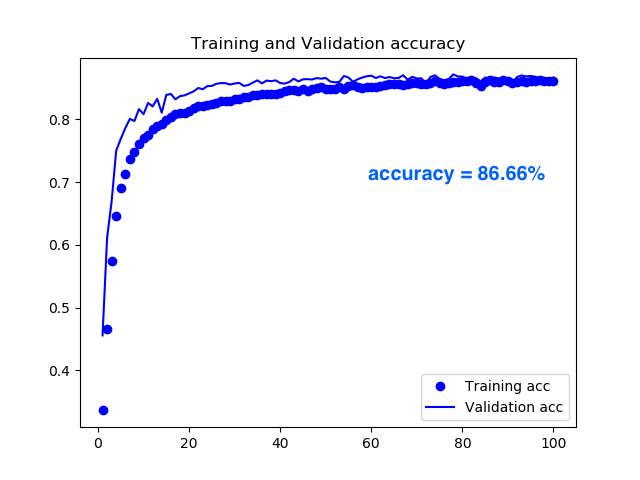
精度の推移グラフです。精度は 86.66%(100 epoch)でした。

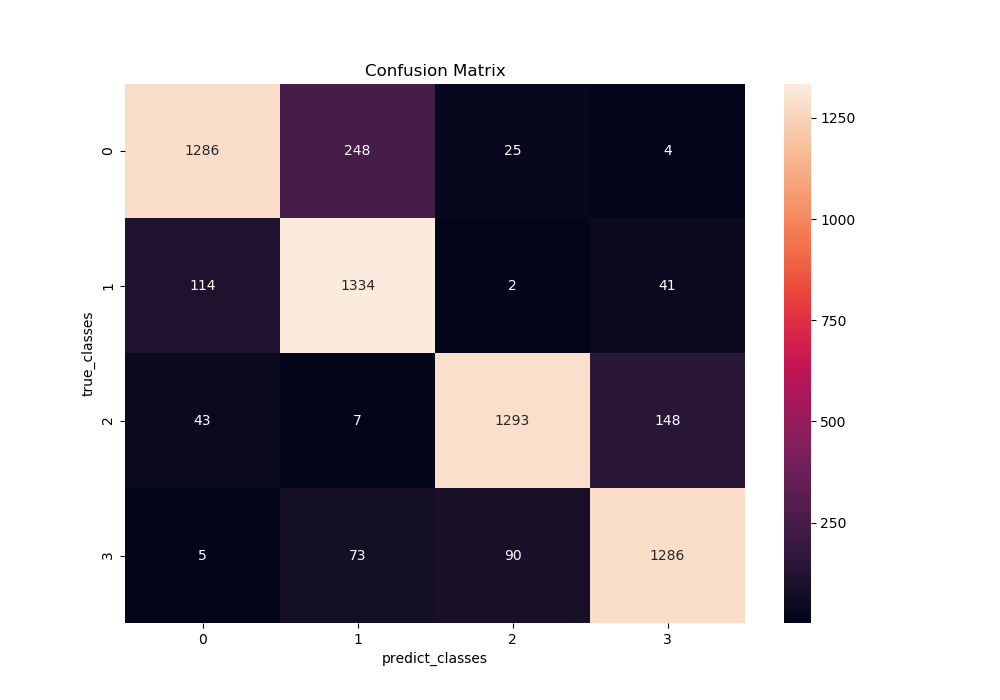
Confusion Matrix です。32×32ピクセルと小さいためか、男性・女性の識別に間違いは少ないですが、笑っているかどうかの識別は間違いが結構多く、むずかしいようですね。
ImageDataGenerator(画像水増し機能)の効果を確認する
改造前プログラム19行目の data_augmentation = True を False に変更すると、ImageDataGenerator を使わない設定になるので、ここを切り替えれば効果が確認できます。
ImageDataGenerator が真価を発揮するのはデータ量が少ない時ですので、データを学習と評価に分割する、x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) の中を test_size =0.97 に変更し、学習用データを24,000個から900個に減らします。
そして、データ数が極端に減るので、改造前プログラム18行目のepochs を100→400に変更して学習回数を調整します。また、ImageDataGenerator には、色々な設定項目がありますが、ひとまずはサンプルプログラムの設定をそのまま使います。

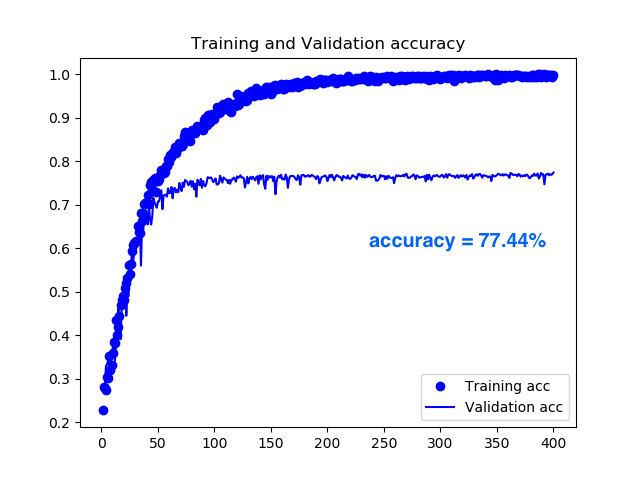
data_augmentation = False で動かした結果です。100epoch で76.30%と急速に精度が改善しますが、それ以降はほとんど精度向上は見られず、400epoch で77.44%でした。まあ、同じ画像を繰り返して学習するだけなので、直ぐ頭打ちになるということでしょうか。

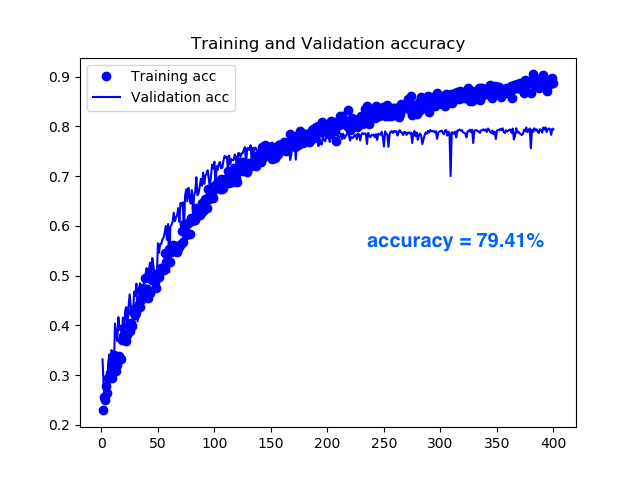
data_augmentation = True で動かした結果です。 False と比べて精度改善スピードはゆっくり目で 100 eopch でまだ70.53%でしたが、その後も着実に精度が改善し 400 epoch で79.41%となり、2ポイント改善されました。人工的とはいえ、常に変化する画像を学習するので、学習効果が長く続くということでしょうか。
ImageDataGenerator の働きを画像で見てみる
ImageDataGenerator が画像にどんな加工を加えているのか、サンプル画像で見てみます。

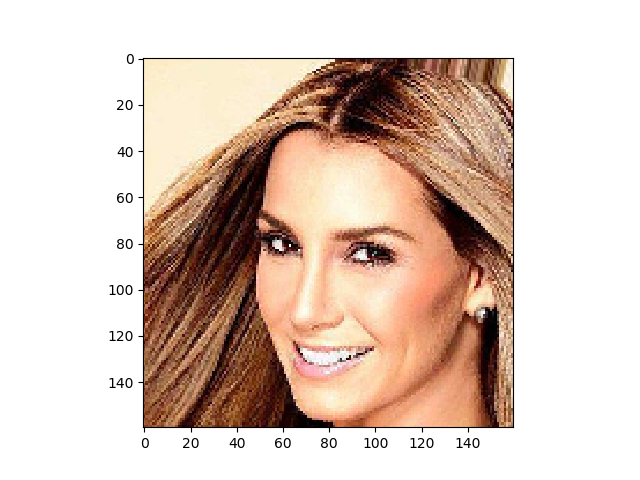
サンプル画像は、CelebAデータセットの先頭にある、この 000001.png を使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import numpy as np import matplotlib.pyplot as plt from keras.preprocessing import image # 画像を読み込む。 img = image.load_img('000001.png') img = np.array(img) plt.imshow(img) plt.show() # 画像データ生成器を作成する。 # -15° ~ 15° の範囲でランダムに回転を行う。 datagen = image.ImageDataGenerator(rotation_range=15) # ミニバッチを生成する Python ジェネレーターを作成する。 x = img[np.newaxis] # (Height, Width, Channels) -> (1, Height, Width, Channels) gen = datagen.flow(x, batch_size=1) # 1枚しかないので、ミニバッチ数は1 # Python ジェネレーターで6枚生成して、表示する。 plt.figure(figsize=(8,1.25)) for i in range(6): batches = next(gen) # (NumBatches, Height, Width, Channels) の4次元データを返す。 # 画像として表示するため、3次元データにし、float から uint8 にキャストする。 gen_img = batches[0].astype(np.uint8) plt.subplot(1, 6, i + 1) plt.imshow(gen_img) plt.axis('off') plt.savefig('./gentest.png') plt.show() |
ImageDataGenerator の働きをチェックするためのプログラムです。000001.png を読み込んで、ImageDataGenerator で設定した内容で加工をしたものを6枚並べて表示し、gentest.png で保存します。(ブログ「Keras の ImageDataGenerator を使って学習画像を増やす」を参考にさせて頂きました。感謝です。)


rotation_range(回転)です。この設定は15で、±15度の範囲でランダムに画像を回転させます。CelebAの顔画像は、傾いた顔はほとんどないので、効果はなさそうです。サンプルプログラムは使っていません。

width_shift(横方向のシフト)です。この設定は0.1で、±10%の範囲でランダムに画像を横方向にシフトします。これはアリですね。サンプルプログラムは、これと同じ0.1で設定しています。

height_shift(縦方向のシフト)です。この設定は0.1で、±10%の範囲でランダムに画像を縦方向にシフトします。これもアリですね。サンプルプログラムは、これと同じ0.1で設定しています。

horizontal_flip(左右反転)です。この設定は True で、ランダムに左右を反転します。これは常套手段ですね。サンプルプログラムでも使っています。

vertical_flip(上下反転)です。この設定は True で、ランダムに上下を反転します。さすがに、顔画像にこれはないでしょう。サンプルプログラムでも使っていません。

zoom_range(ズーム)です。この設定は、0.1で、±10%の範囲で、ランダムに画像をズームします。0.05くらいならありかも。サンプルプログラムは使っていません。

shear_range(シアー変換)です。この設定は、10です。斜め方向に引き延ばすような変換をかけます。顔が歪んじゃうのはあまり良くない気がします。サンプルプログラムでは使っていません。
zoom_range を追加したり、width_shift や height_shift を調整したりして、学習・評価プログラムを再度動かしてみましたが、精度向上は見られず、逆に悪化する場合もありました。CelebAの顔画像は、サンプルプログラムの設定が適切な様です。
では、また。