

今回は、Keras MLPの文章カテゴリー分類プログラムを使って、livedoor ニュースコーパスを分類してみます。
こんにちは cedro です。
先回、サンプルプログラムにある、ロイター・ニュースのカテゴリー分類を紐解いてみました。その結果、ポイントとなるデータセットの構造が分かったので、今度は別のデータセットでやってみたくなりました。
Webで色々探してみると、livedoor ニュースコーパスというのが手頃な大きさで扱い易そうなことが分かりました。やっぱりデータセットは英語ではなく、日本語じゃないとピンと来ませんからね。
というわけで、今回は、Keras MLPの文章カテゴリー分類プログラムを使って、livedoor ニュースコーパスを分類してみます。
livedoor ニュースコーパスとは
livedoor ニュースコーパスとは、livedoor が発信するニュース 7,367個を 9つのカテゴリーに分類したもので、約40MBと手頃なサイズです。まず、このリンクから、idcc-20140209.tar.gz をダウンロードします。解凍すると、text フォルダーが出来ますので、これから作るプログラムと同じフォルダーに保存します。

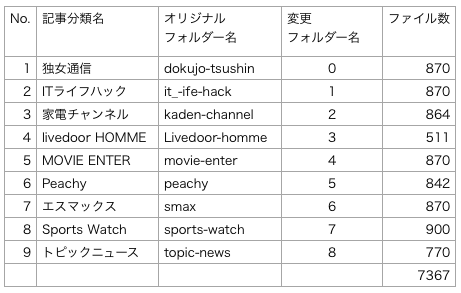
text フォルダーの下に、9つのフォルダーがありますので、そのフオルダー名を0〜8に変更します。これは、この後作るプログラムで、フォルダー名をそのまま分類ラベルに使うためです。


これは、独女通信のニュースの一部です。1行目がURL 、2行目が発信日時、3行目が題名、4行目以降が内容になっています。
プログラムを作成します
英文は単語と単語がスペースで区切られているので、スペース区切りで文字を読み込んで数字を割り振れば良いわけですが、日本語はそういうわけにはいきません。まず、適切な区切りで、分かち書きをする必要があります。例えば、
もうすぐジューン・ブライドと呼ばれる6月。→ もうすぐ_ジューン_・_ブライド_と_呼ば_れる_6月_。という感じ。そして、分かち書きした単語の1つ1つの品詞を調べて、適当なものだけを選ぶ必要があるのです。だって、「・」とか「と」とか「れる」とか「。」は、わざわざ数字にしてもノイズになるだけですよね。
こういう時に活躍するのが、形態素解析のライブラリーです。形態素解析のライブラリーで一番有名なのは、MeCabですが、今回は、 janome を使います。janome は、windows でも、mac でも一発でインストールできるので便利です。まだインストールしてなければ、「pip janome install」 でインストールして下さい。
|
1 2 3 4 5 6 7 |
from janome.tokenizer import Tokenizer word = Tokenizer().tokenize('もうすぐジューン・ブライドと呼ばれる6月。') for i in range(len(word)): print(i,word[i]) |


janome がどういう働きをしてくれるのか、このプログラムを実行して見てみます。 単語を名詞、動詞、副詞、助詞、記号など品詞別に分類してくれ、様々な情報を提供してくれます。後は、ここから必要な情報だけ取得すれば良いわけです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from janome.tokenizer import Tokenizer import os, glob # Janomeを使って形態素解析 ja_tokenizer=Tokenizer() # 分かち書きし、日本語から名詞のみ抽出する def ja_tokenize(text): res=[] lines=text.split("\n") lines=lines[3:] # 最初の3行はヘッダー+題名なので捨てる for line in lines: malist=ja_tokenizer.tokenize(line) for tok in malist: ps=tok.part_of_speech.split(",")[0] # 名詞でなければ以下の処理をスキップ if not ps in ['名詞']: continue w=tok.base_form if w=="*" or w=="": w=tok.surface if w=="" or w=="\n": continue res.append(w) res.append("\n") return res # テキストデータを読み込み dir ='./text' for path in glob.glob(dir + "/*/*.txt", recursive=True): # LICENSE.txtは以下の処理をスキップ if path.find("LICENSE")>0:continue print(path) path_wakati=path + ".wakati" # 既に "wakati"ファイルがあれば以下の処理をスキップ if os.path.exists(path_wakati):continue text=open(path,"r", encoding='utf-8').read() words=ja_tokenize(text) wt=" ".join(words) open(path_wakati, "w", encoding="utf-8").write(wt) |
テキストデータを読み込んで、janome を使って分かち書きし、狙いの品詞を抽出するプログラムです。wakati.py で保存します。抽出する品詞は名詞、動詞、形容詞など色々考えられますが、今回はシンプルに名詞のみにします。
28行目で、text フォルダー以下にある全ての txt ファイル名を読み込んでから、ファイルを1つづつ処理します。9行目に定義した関数を使って、ファイルの最初の3行は、URL+発信日時+タイトルなので捨てます。そして、分かち書きして名詞のみを残します。そして、結果を txt ファイル名の最後に wakati を加えた名前で、保存します。具体的には、下記の様な感じです。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
dic={} # 辞書初期化 count = 0 # 辞書登録用カウンタ folder = ["0","1","2","3","4","5","6","7","8"] x, y = [], [] for index, name in enumerate(folder): dir = "./text/" +name files = glob.glob(dir + "/*.wakati") for i, file in enumerate(files): with open(file, "r", encoding='utf-8') as f: text=f.read() text=text.strip() text=text.split(" ") result = [] # 単語の数字化結果を入れるリスト for word in text: word = word.strip() if word == "": continue if not word in dic: # 未登録の場合 dic[word] = count # count の数字で辞書に登録 num = count count +=1 print(num,word) # 数字と単語を表示 else: num=dic[word] # 数字を辞書で調べる result.append(num) # リストに数字を追加 x.append(result) # リストを配列 x に追加 y.append(index) # フォルダー名を配列 y に追加 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) |
分かち書きしたファイルを使って、データセットを作る部分です。9行目で text フォルダー以下にある、wakati ファイル名を全て読み込んでから、ファイルを1つづつ処理して行きます。
新たに出てくる単語には順番に数字を割り振ると共に辞書に登録します。既に辞書に登録されている単語が再び出て来たら、辞書に登録されている数字を割り振ります。配列 x には名詞を数字化したリストが順次アペンドされ、配列 y にはフォルダー名が順次アペンドされて行きます。
ちなみに、配列 x は、こんなイメージ x = [ [ 10, 11, 12, 3, 8, 13, … 38 ] , [ 39, 40, 12, 16, 19, … ,56 ] , …. , [ 1200, 1504, 3, 15, … 3300 ] ] 。配列 y は、こんなイメージ y = [ 0, 0, 0, 0, … ,8, 8, 8, 8 ] 。
全てのファイルを処理した後、30行目でデータセットを学習80%、評価20%に分割します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
from __future__ import print_function import numpy as np import keras import glob from keras.models import Sequential from keras.layers import Dense, Dropout, Activation from keras.preprocessing.text import Tokenizer from sklearn.model_selection import train_test_split ### 追加 max_words = 1000 batch_size = 32 epochs = 5 print('Loading data...') dic={} # 辞書初期化 count = 0 # 辞書登録用カウンタ folder = ["0","1","2","3","4","5","6","7","8"] x, y = [], [] for index, name in enumerate(folder): dir = "./text/" +name files = glob.glob(dir + "/*.wakati") for i, file in enumerate(files): with open(file, "r", encoding='utf-8') as f: text=f.read() text=text.strip() text=text.split(" ") result = [] # 単語の数字化結果を入れるリスト for word in text: word = word.strip() if word == "": continue if not word in dic: # 未登録の場合 dic[word] = count # count の数字で辞書に登録 num = count count +=1 print(num,word) # 数字と単語を表示 else: num=dic[word] # 数字を辞書で調べる result.append(num) # リストに数字を追加 x.append(result) # リストを配列 x に追加 y.append(index) # フォルダー名を配列 y に追加 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) print(len(x_train), 'train sequences') print(len(x_test), 'test sequences') num_classes = np.max(y_train) + 1 print(num_classes, 'classes') print('Vectorizing sequence data...') tokenizer = Tokenizer(num_words=max_words) x_train = tokenizer.sequences_to_matrix(x_train, mode='binary') x_test = tokenizer.sequences_to_matrix(x_test, mode='binary') print('x_train shape:', x_train.shape) print('x_test shape:', x_test.shape) print('Convert class vector to binary class matrix ' '(for use with categorical_crossentropy)') y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) print('y_train shape:', y_train.shape) print('y_test shape:', y_test.shape) print('Building model...') model = Sequential() model.add(Dense(512, input_shape=(max_words,))) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1) score = model.evaluate(x_test, y_test, batch_size=batch_size, verbose=1) print('Test score:', score[0]) print('Test accuracy:', score[1]) ### Plot accuracy import matplotlib.pyplot as plt acc = history.history["acc"] val_acc = history.history["val_acc"] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, "bo", label = "Training acc" ) plt.plot(epochs, val_acc, "b", label = "Validation acc") plt.title("Training and Validation accuracy") plt.legend() plt.savefig("acc.png") plt.close() ### plot Confusion Matrix import pandas as pd import seaborn as sn from sklearn.metrics import confusion_matrix def print_cmx(y_true, y_pred): labels = sorted(list(set(y_true))) cmx_data = confusion_matrix(y_true, y_pred, labels=labels) df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels) plt.figure(figsize = (10,7)) sn.heatmap(df_cmx, annot=True, fmt="d") ### ヒートマップの表示仕様 plt.title("Confusion Matrix") plt.xlabel("predict_classes") plt.ylabel("true_classes") plt.savefig("c_matrix.png") plt.close() predict_classes = model.predict_classes(x_test[1:10000,], batch_size=32) ### 予測したラベルを取得 true_classes = np.argmax(y_test[1:10000],1) ### 実際のラベルを取得 print(confusion_matrix(true_classes, predict_classes)) print_cmx(true_classes, predict_classes) |
reuters_mlp.py を改造したプログラム全体を載せておきます。90行目からは、おなじみの acc の推移グラフを保存する部分。103行目からは、これもおなじみの Confusion Matrix を保存する部分です。
プログラムを動かしてみます
|
1 2 3 |
python wakati.py |

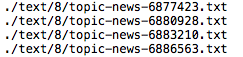
python wakati.py でプログラムを実行すると、該当するテキストファイルを次々にスクリーンに表示しながら、処理を進めます。終了すると、txt ファイルと同じ場所に、wakati ファイルが保存されます。
|
1 2 3 |
python reuters_mlp.py |


続いて、python reuters_mlp.py でプログラムを実行します。作成した wakati ファイルを読み込んで、データセットを作ります。辞書に登録された数字と単語が、スクリーンに次々に表示されます。今回、登録された単語は、全部で 61,600個でした。

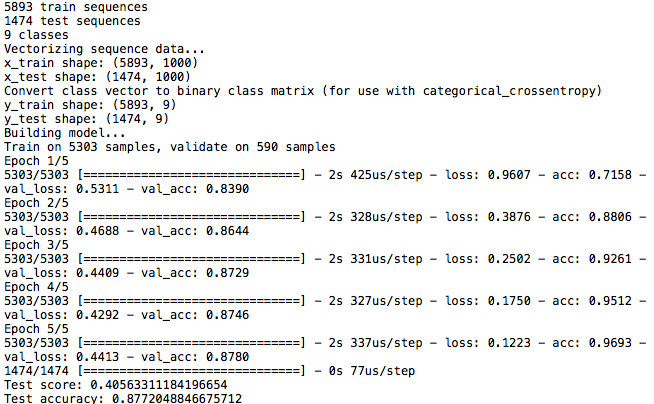
データセットが完成すると、データセットを学習用:評価用=8:2に分けて、学習を開始します。学習完了後、学習に使わなかった評価データ1474個を分類した時の精度(Test accuracy)は 87.72%で、いわゆる Bag of Words という簡単な手法でもまずまずの分類精度が得られました。

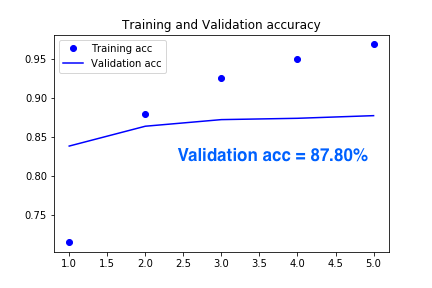
Validation acc の推移グラフです。3epoch 以降はあまり変化なく横ばいという感じです。

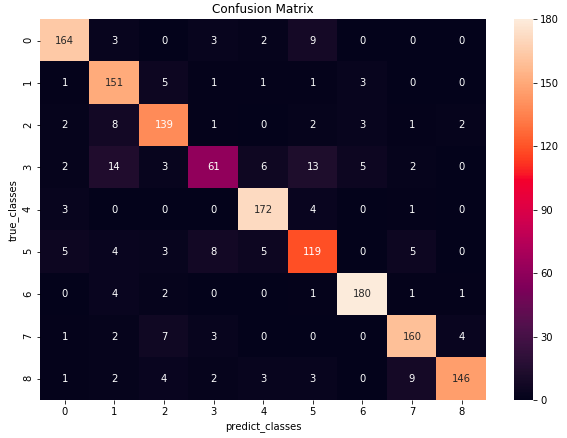
Confusion Matrix です。まずまずバランス良くカテゴリー分類が出来ている様です。

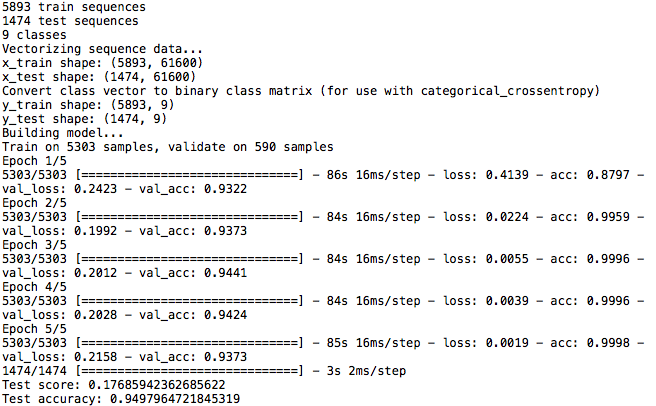
さらに分類精度を上げるために、max_word を1000から辞書登録単語数の61,600に変更してプログラムを実行した結果がこれです。学習時間は約40倍になりますが、分類精度(Test accuracy)は 94.98%と+7.26 ポイントと大幅に向上しました。ロイターニュースがほとんど変わらなかったことに対してこれだけ変化が大きいのは、単語に数字を割り振る時に、出現頻度を考慮していないことが要因だと思われます。
今回は、分類するテキストが手頃なサイズなので処理時間が40倍になっても実質問題になりませんが、テキストサイズが大規模になると、単語に数字を割り振る時に出現頻度を考慮することが、システムのパフォーマンス向上の有効な手法になると思われます。そう考えると、ロイターニュースのデータセットは良く考えられていますね。
では、また。