

今回のテーマは日経平均株価
こんにちは、cedroです。
前々回は、オリジナルの画像データセット(指原莉乃さん)を作ってディープラーニングをしました。
今回はオリジナルの数値データセットを作ってディープラーニングしたいと思います。
ずばりテーマは日経平均株価です。
将来の株価を予測をするためには、テクニカルとファンダメンタルの両側からの分析が必要ですが、ファンダメンタルを入れると変数が膨大になるため、今回はテクニカルだけに絞ります。
しかし、株投資歴4年の私から言わせて貰えば、テクニカル分析だけでも、結構予測できますよ。
自分の好きな時だけエントリーすれば良いという条件であれば、テクニカルだけでも7割くらいの精度で予測は出来るのではないかと思っています。
今回のディープラーニングは、1週間の株価チャートを見て翌週が、「下がる」、「小動き」、「上がる」の3つに分類させることにします。
「小動き」を入れたのは、相場が小動きの時に無理にエントリーしても、結局はチャラということが多いです。
なので、「小動き」の時は無理にエントリーせず、ここぞという時だけエントリーすべきだという考え方からです。
データを収集・加工する。
まず、Yahooファイナンスから、過去5年間の日経平均株価を取得します。
データは、始値、高値、安値、終値と4つありますが、使うのはシンプルに終値だけにします。
これにテクニカル要素として、5日移動平均(当日を含む過去5日間の終値の平均)、25日移動平均(当日を含む過去25日間の終値の平均)、75日の移動平均(当日を含む過去75日間の終値の平均)の3つを計算して加えます。
*この株価に、短・中・長期の移動平均線を加えたチャートというのが、テクニカル分析の基本中の基本で、私も良く使います。その内容は、ここでは説明しませんので、興味のある方は、ググってみてください。
この4つのデータを5日毎に区切って1週間分とします。

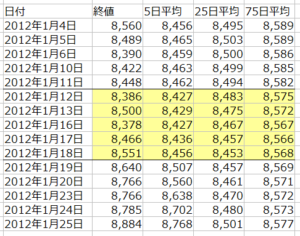
結果、1週間のデータは5行×4列となります。

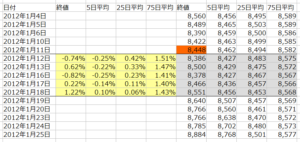
これだけでは、各データの相互関係が分かり難いので、各データが前週の最終日の終値に対して何%乖離しているかを計算します。
上の表では、1月12日~1月18日までの20個のデータそれぞれを、1月11日の終値(8,448)に対して何%乖離しているか計算しています。
例えば、1月18日の終値の乖離率は、(8,551/8,448)-1=+1.22%となるわけです。

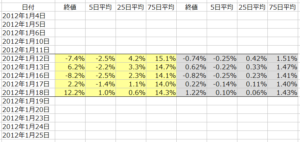
さらに、5年間の全データを確認すると、大体-10%~+10%(ー0.1~+0.1)の範囲に収まっていましたので、各データを10倍して、マニュアルの指示にあるように、おおむねー1.0~+1.0の中に納まるように調整しました。
数値データファイルの作り方
画像データの場合は、適当に切り取った後に、一括して同じピクセルサイズに縮小すれば良かった(指原莉乃をディープラーニングを参照)のですが、数値データはどうやって作るのでしょうか?
ネットで色々調べてみると、EXCELでは作れません(マクロを使うとできるみたいですが、私には無理です)。
これを解決する方法について、さらにネットで色々調べてみた結果、OpenOfficeのCalcを使うのが一番という結論に達しました。

OpenOfficeは、MicroSoft Officと同様なアプリケーションのセットで、Excelに該当するのがCalcという表計算ソフトです。
このCalcを使うと、SONY Neural Network Consoleで読める数値データファイルが作成できます。
しかも、なんと無料なんです。
このリンクからダウンロードして、インストールして下さい。
http://forest.watch.impress.co.jp/library/software/openoffice/
Calcは、ほとんどExcel互換ですので、データ収集の段階からCalcを使うのがおすすめです。
さて、Calcで加工したデータをどうやってSONY Neural Network Consoleが読める数値データにするかですが、
まず、ファイルー新規作成ー表計算ドキュメントをクリックし、新規ファイルを作成します。

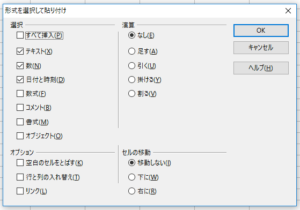
1週間分のデータ(5行×4列)をコピーして、新規ファイルの1行A列のところを右クリックし、「形式を選択して貼り付け」を選びます。
すると、上記のポップアップメニューが出ますので、そのままOKを押します。

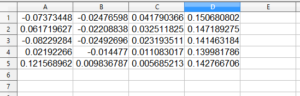
はい、5行×4列のデータが数値でコピーされました。
次に、ファイルー保存をクリックします。

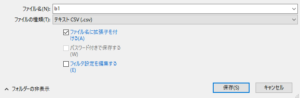
すると、こんなポップアップメニューが出ます。
ファイル名は自分の好きなファイル名を入力(私は、b1と入力しました)。
ファイルの種類は、最初「ODF表計算ドキュメント(.ods)」が表示されていますが、ここを「テキストCSV(.csv)」に変更して、「保存」を押します。

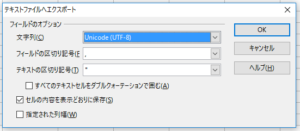
そうすると、文字列選択画面になります。
最初「日本語(Windows-932)」が表示されていますが、ここを「Unicode(UTF-8)」に変更して、「保存」を押します。
これで、SONY Neural Network Consoleが読めるb1.scvという数値データファイルが出来ました。
データセットの作り方
過去5年間の週間データ(244個)を見て翌週が、下がる(ー2%以上)、小動き(±2%以内)、上がる(+2%以上)の3種類に分類します。
分類してみると、半分くらいは「小動き」で、「上がる」と「下がる」は少ないです。
3つのデータが均等に収集できるように、それぞれ60個×3=計180個のデータを選ぶことにし、数値データファイルを作成して、フォルダーに分けます。
stock0というフォルダーに、s1.csv~s60.csv という翌週下がる数値データファイルを格納します(sはsellの略のつもり)。
stock1というフォルダーに、k1.csv~k60.csv という翌週小動きの数値データファイルを格納します(kはkeepの略のつもり)。
stock2というフォルダーに、b1.csv~b60.csv という翌週上がる数値データファイルを格納します(bはbuyの略のつもり)。
画像データの場合は、これだけ用意すれば良かったのですが、数値データの場合は、学習用ファイルと評価用ファイルも自分で作る必要があります。
といっても、特に難しいわけではないです。
学習用ファイルや評価ファイルには、使用する数値データファイルの名前とラベルが書いてあるだけです。
ラベルというのは数値データファイルの種類を表すもので、今回は翌週が下がるは「0」、小動きは「1」、上がるは「2」というラベルを付けることにします。

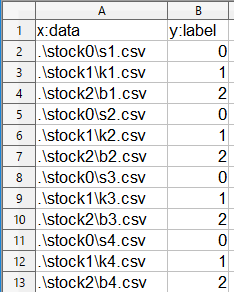
これが、私が作った学習ファイルの一部です(評価ファイルも同様です)。
1行目は項目名。2行目は、フォルダーstock0にあるs1.csvファイルのラベルは「0」ですと書いてあります。
こんな感じで、ラベルが「0」、「1」、「2」のファイルを同数書いておけばOKです。これもCalcで書いて下さいね。
今回データは全部で180個ですので、学習ファイルには144個(80%)、評価ファイルには36個(20%)振り分けて記載しました。
学習用ファイルは nikkei_train.csv、評価用ファイルは nikkei_test.csvというファイル名にしておきます。
そして、C:直下にSNNC30というフォルダーを作り、stock0フォルダー、stock1フォルダー、stock2フォルダーと、nikkei_train.csv、nikkei_test.csv を格納しておきます。
ここまでできたら、いよいよSONY Neural Network Consoleの登場です。
データセットを読み込ませる

SONY Neural Network Consoleを起動したら、左側のDATASETタブをクリックします。そして、中央上の「Open Dataset」をクリックします。

先ほど、作ったSNNC30フォルダーを表示させ、nikkei_train.csvファイルを選択し、「開く」を押します。

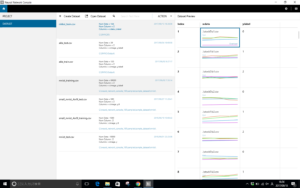
はい、学習用データセットが読み込まれました。
右側の画像をみると、それぞれに、終値、5日、25日、75日の4つの線が並んでいるのが分かります。
評価用ファイル nikkei_test.csv も同様に、読み込ませます。
ニューラルネットワークの設計をする

PROJECT画面で、binary_connect_mnist_MLR.sdcprojを開きます。
今回は3分類ですので、ブロックの最後にS(Softmax)とC(CategoricalCrossEntropy)が付いているこのプロジェクトを流用します。
赤丸のボタンを押し、とりあえず nikkei_binary_connect_mnist_MLR.sdcproj というファイル名で、先ほどのSNNC30フォルダーにセーブします。

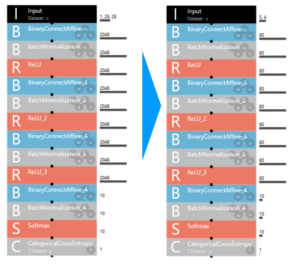
パラメーターについては、Inputを 1,28,28 → 5,4 に変更。
これは、モノクロ28×28ピクセルの画像から、5行×4列の数値データに変更したという意味です。
その他、2048と書いてあるところは全部とりあえず80に変更。後で、SONY Neural Network Consoleが自動最適化を行ってくれるので、適当です。
そして、DATASET画面にし、プロジェクトのTrainigデータセットを nikkei_train.csv に、Validationデータセットを nikkei_test.csv に入れ替えます。
一旦、セーブしておきます。
そして評価はどうなったか?

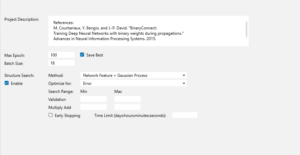
CONFIG画面にします。
MAX epochを100、Batch Sizeを18に変更し、Structure Searchのところの「Enable」をチェックして、学習ボタンを押し、自動最適化を開始します。

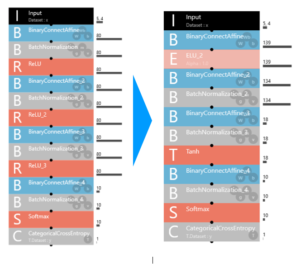
60回くらいトライさせ、評価をチェックした結果、最も良いニューラルネットワークの構成は、こんな形になりました。
そして、お待ちかねの評価結果は、

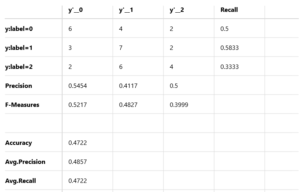
精度は47.22%です。
えー、何それ、全然ダメじゃんという感じですが、実践を考えるとそうでもないんです。
y:label=0のところを見ると、y’_0=6、y’_1=4、y’_2=2となっています。
これは、どういう意味になるかと言うと、翌週下がる場面が12回あったら、6回は下がると正解し、4回は小動きと間違え、2回は上がると間違える、ということです。
しかし、4回の小動きはエントリーしませんので、この分を除くと。8戦して6勝2敗で、勝率75%ということになります。まずまずではないでしょうか。
同様に、翌週上がる場面が12回あったら、6戦して4勝2敗で、勝率は67%です。これも、まあまあ。
小動きの場面が12回あると、3回下がると間違えて、2回上がると間違えています。しかし、小動きなので損益はほぼチャラか、損失があっても限定的でしょう。
当初思っていた、小動きの時はエントリーしないなら、テクニカルだけでも7割くらいの精度では予測できそうという直感に近い結果となりました。
まあ、データが180個とすごく少ないので、たまたまである可能性もありますが。
自らルールを見つけ出すのは本当に革新的な技術だ
今回、株価と移動平均線のチャートを読み込ませてディープラーニングさせた訳ですが、テクニカル分析のルールは何1つ教えていません。
しかし、あたかもテクニカル分析のルールを覚えたような結果を出して来る。
翌週の株価が「下がる」、「小動き」、「上がる」それぞれのチャートの中にルール(特徴量)を自ら見つけ出しているんでしょうね。
今さらながらですが、形だけを見てそこからルール(特徴量)を見つけ出すというのは、本当に革新的な技術だと思います。
チャート分析には様々なものがありますが、この分野はディープラーンングと相性が良さそです。
では、また。
投稿後記 2018.3.10
コメントに、BOMによるエラーのご連絡がありましたので、補足説明します。
【 BOMとは?】
BOMとは、バイトオーダーマーク(byte order mark) の略で、ファイルの先頭にある使用言語を示すマークです。EXCELやメモ帳等で使われており、やっかいなことに画面には表示されません。
ところがNeural Network Console は、データセットにBOMがあるとエラーになってしまいます。BOMもデータの一部として読んでしまうためです。
【 どんなエラーが出るの?】
例えば、どの様なエラーが出るかと言うと
1)学習ファイルと評価ファイルの両方がBOM付になっている場合
Variable “x” is not found in dataset.
2)学習ファイルと評価ファイルのどちらか片方がBOM付になっている場合
ValueError: ‘x’ is not in list
3)5行×4列のデータがBOM付になっている場合
ValueError: could not convert string to float


*1)、2)の場合、DATASET画面でみると、xの前にこんな表示が付きます。
【 原因は?】
BOMが付く原因としては、データセット作成中に、一時的にでもCalc以外のものを使った(Excelとかメモ帳とか)ことが考えられます。
一度Excelやメモ帳等でファイルを保存してしまうと、自動的にBOMが付いてしまい、その後Calcに切り替えても、BOMが付いたままになります。
【 対処方法は?】
BOMが付いているかどうかの確認やBOMを外すには、サクラエディタを使います。
http://sakura-editor.sourceforge.net/ からダウンロードしインストールして下さい。
サクラエディタで問題と思われるファイルを開き、「名前を付けて保存」をクリックします。

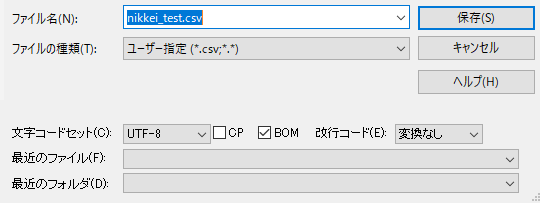
そうするとBOMが付いている場合は、BOMにチェックが入っています。外すには、BOMのチェックを外して、保存(上書き)すればOKです。