
今回のテーマは日経平均株価
こんにちは、cedroです。
前々回は、オリジナルの画像データセット(指原莉乃さん)を作ってディープラーニングをしました。
今回はオリジナルの数値データセットを作ってディープラーニングしたいと思います。
ずばりテーマは日経平均株価です。
将来の株価を予測をするためには、テクニカルとファンダメンタルの両側からの分析が必要ですが、ファンダメンタルを入れると変数が膨大になるため、今回はテクニカルだけに絞ります。
しかし、株投資歴4年の私から言わせて貰えば、テクニカル分析だけでも、結構予測できますよ。
自分の好きな時だけエントリーすれば良いという条件であれば、テクニカルだけでも7割くらいの精度で予測は出来るのではないかと思っています。
今回のディープラーニングは、1週間の株価チャートを見て翌週が、「下がる」、「小動き」、「上がる」の3つに分類させることにします。
「小動き」を入れたのは、相場が小動きの時に無理にエントリーしても、結局はチャラということが多いです。
なので、「小動き」の時は無理にエントリーせず、ここぞという時だけエントリーすべきだという考え方からです。
データを収集・加工する。
まず、Yahooファイナンスから、過去5年間の日経平均株価を取得します。
データは、始値、高値、安値、終値と4つありますが、使うのはシンプルに終値だけにします。
これにテクニカル要素として、5日移動平均(当日を含む過去5日間の終値の平均)、25日移動平均(当日を含む過去25日間の終値の平均)、75日の移動平均(当日を含む過去75日間の終値の平均)の3つを計算して加えます。
*この株価に、短・中・長期の移動平均線を加えたチャートというのが、テクニカル分析の基本中の基本で、私も良く使います。その内容は、ここでは説明しませんので、興味のある方は、ググってみてください。
この4つのデータを5日毎に区切って1週間分とします。
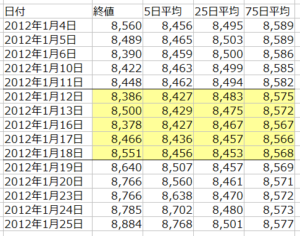
結果、1週間のデータは5行×4列となります。
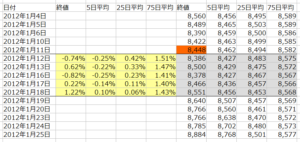
これだけでは、各データの相互関係が分かり難いので、各データが前週の最終日の終値に対して何%乖離しているかを計算します。
上の表では、1月12日~1月18日までの20個のデータそれぞれを、1月11日の終値(8,448)に対して何%乖離しているか計算しています。
例えば、1月18日の終値の乖離率は、(8,551/8,448)-1=+1.22%となるわけです。
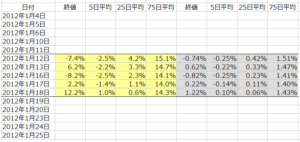
さらに、5年間の全データを確認すると、大体-10%~+10%(ー0.1~+0.1)の範囲に収まっていましたので、各データを10倍して、マニュアルの指示にあるように、おおむねー1.0~+1.0の中に納まるように調整しました。
数値データファイルの作り方
画像データの場合は、適当に切り取った後に、一括して同じピクセルサイズに縮小すれば良かった(指原莉乃をディープラーニングを参照)のですが、数値データはどうやって作るのでしょうか?
ネットで色々調べてみると、EXCELでは作れません(マクロを使うとできるみたいですが、私には無理です)。
これを解決する方法について、さらにネットで色々調べてみた結果、OpenOfficeのCalcを使うのが一番という結論に達しました。
OpenOfficeは、MicroSoft Officと同様なアプリケーションのセットで、Excelに該当するのがCalcという表計算ソフトです。
このCalcを使うと、SONY Neural Network Consoleで読める数値データファイルが作成できます。
しかも、なんと無料なんです。
このリンクからダウンロードして、インストールして下さい。
http://forest.watch.impress.co.jp/library/software/openoffice/
Calcは、ほとんどExcel互換ですので、データ収集の段階からCalcを使うのがおすすめです。
さて、Calcで加工したデータをどうやってSONY Neural Network Consoleが読める数値データにするかですが、
まず、ファイルー新規作成ー表計算ドキュメントをクリックし、新規ファイルを作成します。
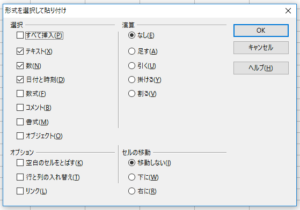
1週間分のデータ(5行×4列)をコピーして、新規ファイルの1行A列のところを右クリックし、「形式を選択して貼り付け」を選びます。
すると、上記のポップアップメニューが出ますので、そのままOKを押します。
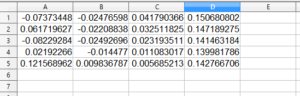
はい、5行×4列のデータが数値でコピーされました。
次に、ファイルー保存をクリックします。
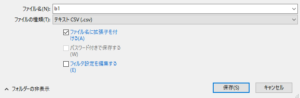
すると、こんなポップアップメニューが出ます。
ファイル名は自分の好きなファイル名を入力(私は、b1と入力しました)。
ファイルの種類は、最初「ODF表計算ドキュメント(.ods)」が表示されていますが、ここを「テキストCSV(.csv)」に変更して、「保存」を押します。
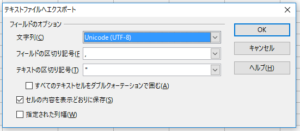
そうすると、文字列選択画面になります。
最初「日本語(Windows-932)」が表示されていますが、ここを「Unicode(UTF-8)」に変更して、「保存」を押します。
これで、SONY Neural Network Consoleが読めるb1.scvという数値データファイルが出来ました。
データセットの作り方
過去5年間の週間データ(244個)を見て翌週が、下がる(ー2%以上)、小動き(±2%以内)、上がる(+2%以上)の3種類に分類します。
分類してみると、半分くらいは「小動き」で、「上がる」と「下がる」は少ないです。
3つのデータが均等に収集できるように、それぞれ60個×3=計180個のデータを選ぶことにし、数値データファイルを作成して、フォルダーに分けます。
stock0というフォルダーに、s1.csv~s60.csv という翌週下がる数値データファイルを格納します(sはsellの略のつもり)。
stock1というフォルダーに、k1.csv~k60.csv という翌週小動きの数値データファイルを格納します(kはkeepの略のつもり)。
stock2というフォルダーに、b1.csv~b60.csv という翌週上がる数値データファイルを格納します(bはbuyの略のつもり)。
画像データの場合は、これだけ用意すれば良かったのですが、数値データの場合は、学習用ファイルと評価用ファイルも自分で作る必要があります。
といっても、特に難しいわけではないです。
学習用ファイルや評価ファイルには、使用する数値データファイルの名前とラベルが書いてあるだけです。
ラベルというのは数値データファイルの種類を表すもので、今回は翌週が下がるは「0」、小動きは「1」、上がるは「2」というラベルを付けることにします。
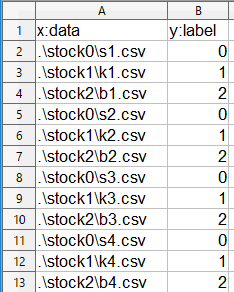
これが、私が作った学習ファイルの一部です(評価ファイルも同様です)。
1行目は項目名。2行目は、フォルダーstock0にあるs1.csvファイルのラベルは「0」ですと書いてあります。
こんな感じで、ラベルが「0」、「1」、「2」のファイルを同数書いておけばOKです。これもCalcで書いて下さいね。
今回データは全部で180個ですので、学習ファイルには144個(80%)、評価ファイルには36個(20%)振り分けて記載しました。
学習用ファイルは nikkei_train.csv、評価用ファイルは nikkei_test.csvというファイル名にしておきます。
そして、C:直下にSNNC30というフォルダーを作り、stock0フォルダー、stock1フォルダー、stock2フォルダーと、nikkei_train.csv、nikkei_test.csv を格納しておきます。
ここまでできたら、いよいよSONY Neural Network Consoleの登場です。
データセットを読み込ませる
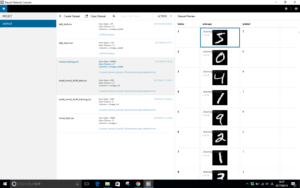
SONY Neural Network Consoleを起動したら、左側のDATASETタブをクリックします。そして、中央上の「Open Dataset」をクリックします。
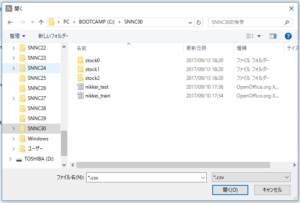
先ほど、作ったSNNC30フォルダーを表示させ、nikkei_train.csvファイルを選択し、「開く」を押します。
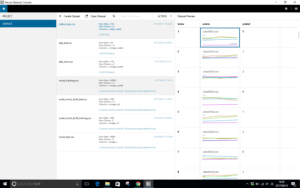
はい、学習用データセットが読み込まれました。
右側の画像をみると、それぞれに、終値、5日、25日、75日の4つの線が並んでいるのが分かります。
評価用ファイル nikkei_test.csv も同様に、読み込ませます。
ニューラルネットワークの設計をする
PROJECT画面で、binary_connect_mnist_MLR.sdcprojを開きます。
今回は3分類ですので、ブロックの最後にS(Softmax)とC(CategoricalCrossEntropy)が付いているこのプロジェクトを流用します。
赤丸のボタンを押し、とりあえず nikkei_binary_connect_mnist_MLR.sdcproj というファイル名で、先ほどのSNNC30フォルダーにセーブします。
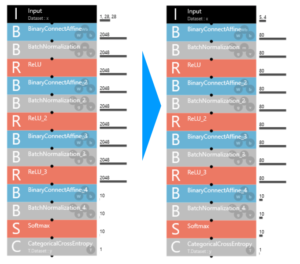
パラメーターについては、Inputを 1,28,28 → 5,4 に変更。
これは、モノクロ28×28ピクセルの画像から、5行×4列の数値データに変更したという意味です。
その他、2048と書いてあるところは全部とりあえず80に変更。後で、SONY Neural Network Consoleが自動最適化を行ってくれるので、適当です。
そして、DATASET画面にし、プロジェクトのTrainigデータセットを nikkei_train.csv に、Validationデータセットを nikkei_test.csv に入れ替えます。
一旦、セーブしておきます。
そして評価はどうなったか?
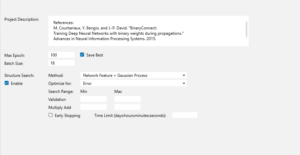
CONFIG画面にします。
MAX epochを100、Batch Sizeを18に変更し、Structure Searchのところの「Enable」をチェックして、学習ボタンを押し、自動最適化を開始します。

60回くらいトライさせ、評価をチェックした結果、最も良いニューラルネットワークの構成は、こんな形になりました。
そして、お待ちかねの評価結果は、
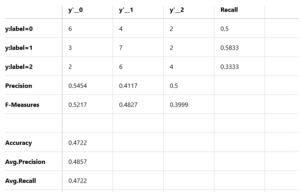
精度は47.22%です。
えー、何それ、全然ダメじゃんという感じですが、実践を考えるとそうでもないんです。
y:label=0のところを見ると、y’_0=6、y’_1=4、y’_2=2となっています。
これは、どういう意味になるかと言うと、翌週下がる場面が12回あったら、6回は下がると正解し、4回は小動きと間違え、2回は上がると間違える、ということです。
しかし、4回の小動きはエントリーしませんので、この分を除くと。8戦して6勝2敗で、勝率75%ということになります。まずまずではないでしょうか。
同様に、翌週上がる場面が12回あったら、6戦して4勝2敗で、勝率は67%です。これも、まあまあ。
小動きの場面が12回あると、3回下がると間違えて、2回上がると間違えています。しかし、小動きなので損益はほぼチャラか、損失があっても限定的でしょう。
当初思っていた、小動きの時はエントリーしないなら、テクニカルだけでも7割くらいの精度では予測できそうという直感に近い結果となりました。
まあ、データが180個とすごく少ないので、たまたまである可能性もありますが。
自らルールを見つけ出すのは本当に革新的な技術だ
今回、株価と移動平均線のチャートを読み込ませてディープラーニングさせた訳ですが、テクニカル分析のルールは何1つ教えていません。
しかし、あたかもテクニカル分析のルールを覚えたような結果を出して来る。
翌週の株価が「下がる」、「小動き」、「上がる」それぞれのチャートの中にルール(特徴量)を自ら見つけ出しているんでしょうね。
今さらながらですが、形だけを見てそこからルール(特徴量)を見つけ出すというのは、本当に革新的な技術だと思います。
チャート分析には様々なものがありますが、この分野はディープラーンングと相性が良さそです。
では、また。
投稿後記 2018.3.10
コメントに、BOMによるエラーのご連絡がありましたので、補足説明します。
【 BOMとは?】
BOMとは、バイトオーダーマーク(byte order mark) の略で、ファイルの先頭にある使用言語を示すマークです。EXCELやメモ帳等で使われており、やっかいなことに画面には表示されません。
ところがNeural Network Console は、データセットにBOMがあるとエラーになってしまいます。BOMもデータの一部として読んでしまうためです。
【 どんなエラーが出るの?】
例えば、どの様なエラーが出るかと言うと
1)学習ファイルと評価ファイルの両方がBOM付になっている場合
Variable “x” is not found in dataset.
2)学習ファイルと評価ファイルのどちらか片方がBOM付になっている場合
ValueError: ‘x’ is not in list
3)5行×4列のデータがBOM付になっている場合
ValueError: could not convert string to float

*1)、2)の場合、DATASET画面でみると、xの前にこんな表示が付きます。
【 原因は?】
BOMが付く原因としては、データセット作成中に、一時的にでもCalc以外のものを使った(Excelとかメモ帳とか)ことが考えられます。
一度Excelやメモ帳等でファイルを保存してしまうと、自動的にBOMが付いてしまい、その後Calcに切り替えても、BOMが付いたままになります。
【 対処方法は?】
BOMが付いているかどうかの確認やBOMを外すには、サクラエディタを使います。
http://sakura-editor.sourceforge.net/ からダウンロードしインストールして下さい。
サクラエディタで問題と思われるファイルを開き、「名前を付けて保存」をクリックします。
そうするとBOMが付いている場合は、BOMにチェックが入っています。外すには、BOMのチェックを外して、保存(上書き)すればOKです。














こんちには。
大変興味深く拝見させていただきました。
お忙しいところ申し訳ありませんが、一つ質問させてください。
今回の投稿は、日経平均の過去データを使いNNCに学習、ディープラーニングをさせると理解しています。
そして、評価用データで検証したところ上記47%の正解率を得たと理解しています。
そこで、今週のデータが出揃ったところで、実際に翌週エントリーするかどうかはどうやって判断するのでしょうか?
例えばYラベルの無い今週のデータを、NNCに読み込ませてプログラムを走らせるような作業を行うのでしょうか?
(データを読み込ませ走らせると、来週は「0」の下がるを表示してくるとか?)
興味はあるのですが、まだNNCを触っていないので突拍子もないような質問で申し訳ございません。
よろしくお願いいたします。
はしもとさんへ
コメント大変ありがとうございます。
はい、その通りです。
今週のデータが出揃ったところで、実際に来週エントリーするかは、今週分だけのデータと評価ファイルを作成して、SONY Neural Network Consoleに登録します。
このとき、yラベルは「2」にしておいて下さい(2にしておかないと表示範囲が0,1だけになってしまいます)。
そして、学習済みのプロジェクトのValidationをこれと入れ替えて評価ボタンを押せば結果が出ます。
ちなみに、今実際に今週分でやってみましたら、来週は「1」と出ました。つまり来週は「小動き」という予想です。
今後とも、よろしくお願いします。
cedroさん、おはようございます。
そして、早速のご回答ありがとうござます。
私も、別データを用意し挑戦してみようと思います。
8月にソニーがNNCを公開した際急に興味が湧き、コード作成が不要とは言いつつNNの基礎は学ぼうと初心者用の本を読んでいたところなのです。
また、ネットで探しても画像を使ったレビューは沢山あったのですが、テキストデータを使ったものは殆どなく大変参考になりました。
はしもとさん、おはようございます。
私もソニーのNNC紹介の動画を見た瞬間恋に落ちてしまいました(笑)。
それ以降、週末はマニュアルとWebでの情報を元にNNCと戯れています。
このブログは、私の試行錯誤の結果です。参考にして頂ければ、大変うれしいです。
ソニーのNNCは、普通の人が使えるディープラーニングだと思っています。もっとWebで色々な情報があふれてくると良いですね。
はしもとさんのオリジナルデータの結果が分かりましたら、ぜひ教えて下さい。
今後とも、よろしくお願いします。
はじめまして。
株価ではないのですが同じ数値です。
もしよかったら教えて頂けませんか?
> 各データを10倍して、マニュアルの指示にあるように、おおむねー1.0~+1.0の中に納まるように調整しました。
上の表を見てもMAXが15.1%で MINが-8.2%にもなっていますがこれはどのような意味なんですか?
データセットの作り方ですが、最終的には5行×4列のタイトルも日付も入っていない数値のみのデータファイル(csv)を作れば良いのですね?
翌週下がる・小動き・上がるの数値データファイルを、stock0、stock1、stock2という各フォルダーに格納とありますが、この数値データファイル(csv)は絶対に必ず同じ数だけ要りますか?
学習用ファイル(nikkei_train.csv)と評価用ファイル(nikkei_test.csv)ですが、
上で作った数値データファイル(csv)のデータを、8対2の割合で各々のファイル(csv)に貼り付けて作れば良いのですね?
評価までは事前に済ませておいてのリアルタイムでの予想も出来ますか?
mokoさんへ
コメントありがとうございます!
>上の表を見てもMAXが15.1%で MINが-8.2%にもなっていますがこれはどのような意味なんですか?
■表でお見せしている部分は10倍しても、 -0.082(-8.2%)~ +0.151(+15.1%)の狭い範囲に留まっていますが、5年間でみるともっと変化が激しい時があるので、全体として-1.0(-100%)~+1.0(+100%)の中に納まっているという意味です。
>データセットの作り方ですが、最終的には5行×4列のタイトルも日付も入っていない数値のみのデータファイル(csv)を作れば良いのですね?
■その通りです。
>翌週下がる・小動き・上がるの数値データファイルを、stock0、stock1、stock2という各フォルダーに格納とありますが、この数値データファイル(csv)は絶対に必ず同じ数だけ要りますか?
■いいえ。但し、偏りがあるより同数の方が上手く学習でき、識別精度が上がると思うので、同数にしているだけです。
>学習用ファイル(nikkei_train.csv)と評価用ファイル(nikkei_test.csv)ですが、上で作った数値データファイル(csv)のデータを、8対2の割合で各々のファイル(csv)に貼り付けて作れば良いのですね?
■はい。学習用ファイル、評価用ファイルには、「数値データファイル名」と「ラベル名」を記入します。
>評価までは事前に済ませておいてのリアルタイムでの予想も出来ますか?
■出来ます。評価用ファイルを最新の1つのデータ分に入れ替えて、評価を実行すれば、リアルタイムでの予測ができます。
回答くださってありがとうございます。
> 全体として-1.0(-100%)~+1.0(+100%)の中に納まっているという意味です。
てっきりー0.1(-10%)~+0.1(+10%)かと思っていました。
> 同数の方が上手く学習でき、識別精度が上がると思うので、同数にしているだけです。
使ってるうちに追加のデータも増えて来るので偏っても来るようにも思ったのです。
> はい。学習用ファイル、評価用ファイルには、「数値データファイル名」と「ラベル名」を記入します。
Microsoft Azure Machine Learningのように、自動でそれぞれに分割はしてくれないのですね?
> 出来ます。評価用ファイルを最新の1つのデータ分に入れ替えて、評価を実行すれば、リアルタイムでの予測ができます。
出来るのですね。
でも、他のプログラムから呼び出して、自動で予測もし結果も得られる、などと言ったことまでは流石に無理ですよね?
すみません、追加での質問です。
> 過去5年間の週間データ(244個)を見て翌週が、下がる(ー2%以上)、小動き(±2%以内)、上がる(+2%以上)の3種類に分類します。
とありますが、この対比は2012年1月11日の8,448円と2012年1月18日の8,551円とでされたものですよね?
また全然分かってないですが無償なのはとてもうれしいです。
でもやはり英語は苦手、だれか日本語の作ってくれないかなぁ(笑)
mokoさんへ
コメントありがとうございます!
質問への回答をさせて頂きます。
>はい。学習用ファイル、評価用ファイルには、「数値データファイル名」と「ラベル名」を記入します。
>>Microsoft Azure Machine Learningのように、自動でそれぞれに分割はしてくれないのですね?
■数値データファイルの場合は、自分で学習・評価ファイルを作る必要があります。しかし、画像データの場合は、NNCのCreate dataset機能を使えば、自動的に 学習・評価ファイルを自動的に作成してくれます。
>出来ます。評価用ファイルを最新の1つのデータ分に入れ替えて、評価を実行すれば、リアルタイムでの予測ができます。
>>出来るのですね。
でも、他のプログラムから呼び出して、自動で予測もし結果も得られる、などと言ったことまでは流石に無理ですよね?
■可能です。学習・評価済みのネットワークをPythonコードで書き出し、少々コードを追加し、学習した重みを読み込ませれば、Pythonの推論実行プログラムが出来ます。これを他のプログラムから呼び出せばOKです。
>過去5年間の週間データ(244個)を見て翌週が、下がる(ー2%以上)、小動き(±2%以内)、上がる(+2%以上)の3種類に分類します。
>>とありますが、この対比は2012年1月11日の8,448円と2012年1月18日の8,551円とでされたものですよね?
■1/11の8,448円に対して、1/12〜1/18の騰落率の絶対値が一番大きい日を見て分類しています。
それにしても、一昔前なら、数十万円はしたかもしれないソフトウエアが無償で手に入る時代になりました。仰る通り、ありがたいことですね(笑)。
今後とも、よろしくお願い致します。
ありがとうございます。
> ■可能です。学習・評価済みのネットワークをPythonコードで書き出し、少々コードを追加し、学習した重みを読み込ませれば、Pythonの推論実行プログラムが出来ます。これを他のプログラムから呼び出せばOKです。
そんなことまで出来ちゃうんですね。
何か夢のよう。
こうして教えてくださることとてもうれしいです。
また教えてくださいね。
今後どのようなこと載せてくださるかも楽しみにしています。
先日はありがとうございました。
質問ばかりですみません、もう少し教えて頂けませんか?
学習ボタンを押し、自動最適化を開始しようとしたのですが、
> [Error 1] Input->Dataset : Variable “x” is not found in dataset.
> 1 errors.
のエラーが出てしまいました。
よく見てみますとDATASETをクリックしての表示がされる表タイトルの表示も少しおかしく、本来は「x:data」となる筈なのですがなぜか「〇x:data」のように〇の部分に何か2文字入った表示となっています。
nikkei_train.csv・nikkei_test.csv共に中身は正常で保存もUTF-8でしていますし、「Index」と「y:dabel」はエラーも出ず正常です。
それと・・
> MAX epochを100、Batch Sizeを18に変更し、
の数値は何を示してるのですか?
取り敢えずはBatch Sizeの数値を減らすことでエラーは消えました。
> 60回くらいトライさせ、評価をチェックした結果、
とありますが、どのようにしてトライさせるのですか?
その保存と呼び出し方もあれば教えてください。
よろしくお願いします。
mokoさんへ
コメントありがとうございます。
ご回答させて頂きます。
学習ボタンを押し、自動最適化を開始しようとしたのですが、
> [Error 1] Input->Dataset : Variable “x” is not found in dataset.
> 1 errors.
のエラーが出てしまいました。
■エラーの原因は、 nikkei_train.csv と nikkei_test.csv が、何らかの原因でBOM付きで保存されているためと思われます。
BOMとは、バイトオーダーマーク(byte order mark) の略で、ファイルの先頭にある使用言語を示すマークです。EXCEL等で使われており、やっかいなことに画面には表示されません。NNCは、このBOMがあるとエラーになってしまうのです。
BOMが付いた原因は、データセット作成中に、一時的にでもCalc以外のものを使った(Excelとかメモ帳とか)ことが考えられます。
BOMを外す方法は、http://sakura-editor.sourceforge.net/ からサクラエディタをダウンロードしインストールします。サクラエディタで問題のファイルを開き、名前を付けて保存を選び、BOMのチェックを外して、保存(上書き)すればOKです。
なお、5行×4列のデータもBOM付になっていないか、一応チェックしておいて下さい。
> MAX epochを100、Batch Sizeを18に変更し、
の数値は何を示してるのですか?
取り敢えずはBatch Sizeの数値を減らすことでエラーは消えました。
■Max epoch は学習ファイルを何回繰り返して学習させるかを表します。今回は100なので、学習ファイルを100回繰り返して学習させるという意味です。
Batch Size は1回の学習に使うデータ数です。今回は18なので、1回の学習に18個のデータを使うという意味です。Batch Size 学習・評価データ数より大きいとエラーになりますので、デフォルトの64を18に変更しています。
> 60回くらいトライさせ、評価をチェックした結果、
とありますが、どのようにしてトライさせるのですか?
その保存と呼び出し方もあれば教えてください。
■CONFIG画面で、Structure Searchのところの「Enable」 して学習を開始すれば、後はNNCが 学習→データ保存→自動最適化→学習→データ保存→自動最適化→ ・・・・ と学習終了ボタンを押すまで、いつまででも試行錯誤を続けます。あなたは、この間マシンを放置しておくだけです。
適当なところで学習終了ボタンを押せば、それまでの試行錯誤の結果は、全て自動的に記録されています。
ありがとうございます。
BOMは外せました。
> Batch Size は1回の学習に使うデータ数です。今回は18なので、1回の学習に18個のデータを使うという意味です。
この18個という数はどこから来てるのですか?
探し方が悪いのかもしれませんが見つかりませんでした。
BOMが外せたとのこと。良かったです。
> Batch Size は1回の学習に使うデータ数です。今回は18なので、1回の学習に18個のデータを使うという意味です。
この18個という数はどこから来てるのですか?
探し方が悪いのかもしれませんが見つかりませんでした
■今回は、評価データが36個しかないので、Batch Sizeは36以下にしなければなりません。
この当時は、まだディープラーニングを始めたばかりで、評価データを1回で評価するより複数に分けた方が良いのかなと思って、学習データ144個・評価データ36個の両方が丁度割り切れる18という数字を選びました。
その後、色々勉強してみるとBatch Sizeはある程度大きい方が良い(どんどん大きくすればするだけ良くなるわけではありません、計算にも時間が掛かるようになりますし)結果が出ること、また割り切れる数字にする必要もないことが分かってきましたので、今ならBatch Size は迷わず36にするでしょうね。
というわけで、18という数字に特別な意味はありません。
今回のmokoさんのエラーに関するご質問に関しては、他の方の参考にもなると思いますので、分かり易く投稿後記に追加したいと思います。ありがとうございました。
こんばんは。
> BOMが外せたとのこと。良かったです。
ありがとうございます。
VBがちょっとだけ分かるのでデータはそれで作ってみました。
でもUTF8は初めてなのでBOMがあるのも知りませんでした。
> 今ならBatch Size は迷わず36にするでしょうね。
>
> というわけで、18という数字に特別な意味はありません。
評価データは11しかありませんので取り敢えず11にしました。
すみません。
データを変えるなどして何度も試してるのですが、どうしてもTtaining 実行しますとこのようなのエラーが出てしまいます。これは何だか分かりますか?
2018-03-11 18:18:50,743 [nnabla]: epoch 1 of 2 cost=2.585134 {train_error=87.336548, valid_error=87.336548}
2018-03-11 18:18:50,868 [nnabla]: epoch 2 of 2 cost=2.622086 {train_error=34.816638, valid_error=37.282761}
2018-03-11 18:31:16,176 [nnabla]: epoch 1 of 2 cost=2.587626 {train_error=85.222282, valid_error=85.261612}
2018-03-11 18:31:16,364 [nnabla]: epoch 2 of 2 cost=2.634255 {train_error=17.037052, valid_error=18.767515}
mokoさんへ
これは、いわゆるエラーではありません。
1epoch学習した時の学習データとの誤差(train_error)、評価データとの誤差(valid_error)を表していて、正常な動作です。
少し気になるのは、1 ・2epoch 目の学習データとの誤差、評価データとの誤差が異常に大きいようです(これはデータ自体の問題と思われます)。
また、Max Epochの設定が2なのは、小さ過ぎるように思います。評価データが11個だとすると、学習データは100個以下ですよね。それだと、感覚的に言ってMax Epochは100以上が良いのではないでしょうか。
ご参考までに。
こんばんは。
ありがとうございます。
> これは、いわゆるエラーではありません。
エラーではなんですね、安心しました。
> 少し気になるのは、1 ・2epoch 目の学習データとの誤差、評価データとの誤差が異常に大きいようです(これはデータ自体の問題と思われます)。
エラーが出るのはデータがおかしいのではないかと思って色々なぶってしまいました。すみません。
> また、Max Epochの設定が2なのは、小さ過ぎるように思います。
はい、増やしてみます。もしかして過学習との関係があるかとも思ってました。
> CONFIG画面で、Structure Searchのところの「Enable」 して学習を開始すれば、後はNNCが 学習→データ保存→自動最適化→学習→データ保存→自動最適化→ ・・・・ と学習終了ボタンを押すまで、いつまででも試行錯誤を続けます。あなたは、この間マシンを放置しておくだけです。
> 適当なところで学習終了ボタンを押せば、それまでの試行錯誤の結果は、全て自動的に記録されています。
データを20行×4列ともしてしまったせいでしょうか、2時間余りも掛かっても終わりませんでしたので学習を途中で中断してしました。
そこでちょっと気になったのが進捗状況です。後どれ位掛かるとかを示す機能ってないんですね?
記録された試行錯誤の結果も見てみました。
どれが良いかは分かりますがその先が分かりません。
どのようにすれば良いなど活用方法も教えていただけないでしょうか?
どこかに書かれてるのでしたらそれを見ます。
mokoさんへ
返信します。
>データを20行×4列ともしてしまったせいでしょうか、2時間余りも掛かっても終わりませんでしたので学習を途中で中断してしました。
そこでちょっと気になったのが進捗状況です。後どれ位掛かるとかを示す機能ってないんですね?
■何処まで試行錯誤したら最適化が終わりなのかを機械に判断させるのは難しいので、人間が判断することになります。私の経験で言うと、最初の内は改善頻度が高く、その内改善頻度が低下し、さらに進むと改善頻度がほとんどなくなるので、そのあたりで学習を停止させています。
>記録された試行錯誤の結果も見てみました。
どれが良いかは分かりますがその先が分かりません。
どのようにすれば良いなど活用方法も教えていただけないでしょうか?
どこかに書かれてるのでしたらそれを見ます。
■学習を終了したら、1つ1つプロジェクトの評価を実行して、Confusion Matrixで識別精度をチェックします。明らかに評価誤差(Validation error)が高いプロジェクトはスキップすればよいです。そして、一番良い識別精度のプロジェクトを学習・評価済みのニューラルネットワークとします。
後は、最新のデータが出て来たら、その学習・評価済みのニューラルネットワークの評価ファイルを最新のデータの評価ファイルに置き換えて評価を実行すれば、最新のデータでの推論ができます。
こんばんは。
> ■学習を終了したら、1つ1つプロジェクトの評価を実行して、Confusion Matrixで識別精度をチェックします。明らかに評価誤差(Validation error)が高いプロジェクトはスキップすればよいです。そして、一番良い識別精度のプロジェクトを学習・評価済みのニューラルネットワークとします。
> 後は、最新のデータが出て来たら、その学習・評価済みのニューラルネットワークの評価ファイルを最新のデータの評価ファイルに置き換えて評価を実行すれば、最新のデータでの推論ができます。
理解は出来てませんが調べながらやってみます。
何度もありがとうございました。
調べながらと言っておきながらですが。
Run evaluation(F6)で Results History にある各項目をひとつづつ確認もしました。
そこで例えば 20180317_010602 が精度的にも優れていたとします。
恐らくこれを学習・評価済みのニューラルネットワークとするのでしょうが、どのようにすればそのようになるのでしょうか? 名前を付けての保存でもないようです。
また、明らかに評価誤差(Validation error)が高いプロジェクトはスキップすればよい、とのことですがそれは Results History の各項目にある Validation 数値のことですか?
mokoさんへ
コメントありがとうございます!
>そこで例えば 20180317_010602 が精度的にも優れていたとします。
恐らくこれを学習・評価済みのニューラルネットワークとするのでしょうが、どのようにすればそのようになるのでしょうか? 名前を付けての保存でもないようです。
■Risult Historyにあるものは、既に保存されています。20180317_010602 が一番精度が良いのであれば、それを学習・評価済みネットワークとして扱えばOKです。
>また、明らかに評価誤差(Validation error)が高いプロジェクトはスキップすればよい、とのことですがそれは Results History の各項目にある Validation 数値のことですか?
■はい、その通りです。グラフの赤い点線を見ても良いです。
ありがとうございます。
> ■Risult Historyにあるものは、既に保存されています。20180317_010602 が一番精度が良いのであれば、それを学習・評価済みネットワークとして扱えばOKです。
その扱い方が分かっていません。
POpen Dataset からでもないようですし。
> ■はい、その通りです。グラフの赤い点線を見ても良いです。
赤い点線がどのようになれば良いのでしょう?
mokoさんへ
コメントありがとうございます!
>その扱い方が分かっていません。
POpen Dataset からでもないようですし。
■学習・評価済みネットワークを使って、新たなデータで推論をする場合の手順です、
1)新たなデータで評価データセットを作成し、NNCに登録します。
2)学習・評価済みネットワークがあるプロジェクトを開いて、評価データセットを登録したものに入れ替えます。
3)TRAININGあるいはEVALUATION画面にして、Result Historyから学習・評価済みネットワークをワンクリックして選択します(例えば、20180317_010602 の精度が一番良いなら、これをワンクリックします)。
4)画面左上にあるEvaluationボタン「▷」を押します。
>赤い点線がどのようになれば良いのでしょう?
■Result Historyに沢山の学習結果がある場合の選別の仕方です。
Learning Curve のCOST、TRAINING ERRORの線が滑らかに0に近づき、それに連動する形で、VALIDATION ERROR(赤い点線)が滑らかに0に近づくのが理想です。
沢山ある学習結果をざっと見て、VALIDATION ERROR(赤い点線)の絶対値が明らかに下がっていないものは、わざわざ評価を実行するまでもなく、スキップすればOKです。
すみません、迷っています。
> 1)新たなデータで評価データセットを作成し、NNCに登録します。
この評価データは例えば nikkei_test.csv の中身が 1個だけのデータがあるのと同じものになるのですよね?
としますと CONFIG での Batch Size も 1 にしないとエラーが出てしまいます。
> 3)TRAININGあるいはEVALUATION画面にして・・
沢山ある Result History 項目の中から例えば目的の 20180317_010602 を探し出すのはかなり大変なのですがこれはどうにもならないのでしょうか?
mokoさんへ
コメントありがとうございます!
>としますと CONFIG での Batch Size も 1 にしないとエラーが出てしまいます。
■Batch Size は評価データ数以下にしなければならないので、評価データ数が1ならBatch Size は1にしなければなりません。それでOKです。
Batch Size が小さ過ぎることを心配する必要はありません。学習時はBatch Sizeがある程度の数字でないと学習が上手く進み難い場合がありますが、学習はもう完了していますので。
>沢山ある Result History 項目の中から例えば目的の 20180317_010602 を探し出すのはかなり大変なのですがこれはどうにもならないのでしょうか?
■これはしょうがないですね。精度の良かったものをメモっておけば、時間順に並んでいるので、見つけ出すのはそれほど大変ではないと思います。
また、Result Historyの中で、もう使わないものは、右クリックしてDelete from Disk で削除すると、次からはパッと見付けられます。
すみません。
もう完全にギブアップです。
ここまでは良かったんですけどね。
暫く休養します。
ありがとうございました。
あっ、不適切な投稿でしたら削除くださいね。
mokoさんへ
>暫く休養します。 ありがとうございました。
■また、何か分からないことがありましたら、ご質問下さい。私の分かる範囲でお答えします。
今後とも、よろしくお願いします。
こんばんは。
ありがとうございます。
暫く休養?も出来たので再開してみました。
データは20行(20日間)× 4列(終値・5日平均・25日平均・75日平均)と同じなのですが、今回のは前週最終日の終値に対しての何%乖離とはせずに株価そのままを使ってです。
「上昇・下降・変わらず」となった過去のパターンと同じなのを見つけたかったのです。
でもそこには「上昇・下降・変わらず」となった結果はデータとして含まれてませんよね。
(それは何%乖離とした場合にも同じなのですが・・)
にも拘わらずどうして学習・予測が出来るのでしょうか、いまだに分かってません(汗;)
それとWindows 10 i5-6200U ですが15時間経っても終わりませんでした。
やっぱりGPUは要るのでしょうね。
MOKOさんへ
ここ数年日経平均は上昇トレンドに乗っていますので、絶対値を使うと、過去のデータが生かされなくて上手く学習ができないかもしれません。例えば、過去に10,000円から10,500円に+5%上がった時の終値、5日、25日、75日の各データを絶対値で学習していると、現在の20,000円を超える株価には適用できないと思います。
しかし、前週終値を起点としての乖離率を使えば、絶対値が変化していても、過去のデータが生かせると思います。終値が+5%上がった時に、5日、25日、75日はそこから何%、どちらに乖離していたかを学習しますので、絶対値が20,000円を超えても適用できます。
あと、15時間かかっても終わらないのは学習時のことでしょうか。学習時のことであれば、データが20行×4列と軽いので、マシンの能力の問題ではないように思います。学習時のグラフは、どんな形になっていますでしょうか。
ありがとうございます。
そのようなこともあるのですね。気づきませんでした(汗;)
なぜ絶対値を使ったかと言いますと、例えば2番底を打てば反転上昇する可能性はありますよね。
株価でもそのチャートでも良いのですが、そのようなパターンを学習予測したかったのです。
データを20行(20日間)をもの長期にしたのもその為なんです。
15時間かかっても終わらないのは学習時のことです。
学習時のグラフはたぶん普通だと思うのですがデータ数としは24,000ほどあります。
それと何度かプログラム自体を削除しては再インストールしています。
再インストールと言ってもフォルダ内に置くだけですし、削除はと言えばフォルダごと削除しています。
可能であれが予測をしたいデータをどのように作るのかを教えてください。
結果はまだ出てませんのでx:dataをs1.csv・k1.csv・b1.csvのどれかにすることも、y:labelを0・1・2のどれかにすることも出来ないと思うのです。
中村さん
コメントありがとうございます。
学習の時、y:label は実態に合わせておかないと正しく学習できません。
しかし、評価(予測)の時は、その学習結果を元に、x:data だけみて推論しますので、原理的には y:label にはなんと書いてあってもOKです。但し、SONY Neural Network Consoleの仕様上、注意が必要な点があります。
例えば、今週のデータが出揃ったところで、実際に来週エントリーするかどうか予測する場合は、今週分だけのデータと評価ファイルを作成して、SONY Neural Network Consoleに登録します。
このとき、y:label は「2」にしておいて下さい(2にしておかないと表示範囲が0,1だけになってしまいます)。そして、学習済みのプロジェクトのValidationをこれと入れ替えて評価ボタンを押せば予測結果が出ます。
今後とも、よろしくお願いします。
y:label は「2」にしないと駄目なのですね。
ありがとうございます。
これで解決しました。
もし機会があり、この予測の一連の操作が自動で出来るのあればupしていただければと思います。
さすればリアルタイムでの活用も可能となりますので。
(今週分だけのデータと評価ファイルは別途作るとして)
ただ今のところPythonなどの言語もありませんし理解もしてませんがね。
参考にさせて頂いております。
基本的なところを教えて下さい。
こちらのデータでは、1週間前の終値→今週の値動き を算出してこれを入力にしていると思いますが
普通に考えると、今日の終値→前週からの値動き を算出して、これを入力にして明日の終値の値動き
を予測するのではないかと思うのですが、どうなんでしょうか。
高橋さん
コメントありがとうございます!
もちろん、そういう形で予測をさせる方法もアリだと思います。
様々なアプローチがあるはずですので、色々試してみるのが良いと思います。