

今回は、NNabla のサンプルプログラムDCGANを改造して、もう少し全体を理解したいと思います。
こんにちは cedroです。
最近、Neural Network Console で開発したプログラムを実装したいと思っていて、その準備として、Neural Network Console のベースで動いているNeural Network Libraries (NNabla)を触っています。
先回、一番の悩みどころであった、データセットの読み込ませ方が理解できましたので、今回は、サンプルプログラムの改造を通じて、もう少し全体を理解したいと思います。
今回、改造するサンプルは、DCGAN です。これは、先々回やった Fashin Mnist の画像生成が好印象だったので、再度の登場です。
丁度、お正月に自分で作った顔画像のデータセット(カラー64×64サイズ、女性タレント217人、学習データ数10,368個)があるので、これを利用しようと思います。
NNablaのDCGANサンプルについて
DCGANサンプルは、NNabla と Neural Network Console の両方にあり、共に MNIST の数字を生成する仕様になっていますので、中身も似ているのかなと思うと結構違います。どこが違っているのかと言うと
1)NNablaはラベル情報を使わない
GANはランダムノイズから画像を生成するため、生成される画像を制御することが難しいです。そのため、Neural Network Consoleでは、ラベル情報を画像化し、ラベル画像と数字画像をセットで学習することで生成画像を制御しています。一方、NNabla では画像データーの分布情報を使うことで生成画像を制御しています。
2)NNablaは重装備
例えば、逆畳み込み層で言えば、Neural Network Console の2層に対して NNabla は4層あり、画像枚数(フィルター数)は全て倍あります。内部構成だけ見れば、論文で発表されたモデルと同じで、画像枚数(フィルター数)が1/4になっているだけです。結構重装備なんです。
3) NNabla はモニターが弱いが良い点もある
Neural Network Console はシステムにグラフ表示機能が組み込まれていて、学習の進捗状況をグラフで見ることが出来ます。ところが、NNabla はモニター画面やファイルに数字を書き出すだけ。実にそっけないです。
しかし、NNabla は学習中の生成画像を随時モニターできます。Neural Network Console だと学習を完了し評価を実行しないと生成画像を見ることが出来ないので、これは大きなアドバンテージです。
まず、NNablaのDCGANサンプルをそのまま動かします
改めて、NNabla の DCGAN サンプルをそのまま動かしてみましょう。
まず、SONY/nnabla-examples を開いて、HP右上にある緑色の「Clone or Download」ボタンを押し、Download Zipで、ファイル一式をダウンロードします。
ダウンロードしたファイルを解凍したら、mnist-collection の中にある、args.py , dcgan.py , mnist_data.py の3つのプログラムをコピーして、サンプルを動かすためのフォルダーを作って(例えば dcgan_mnist )、その中に入れます。

こんな感じになるはずです。

Anaconda Navigator を起動し、nnabla の仮想環境で、Open Terminal を開きます。

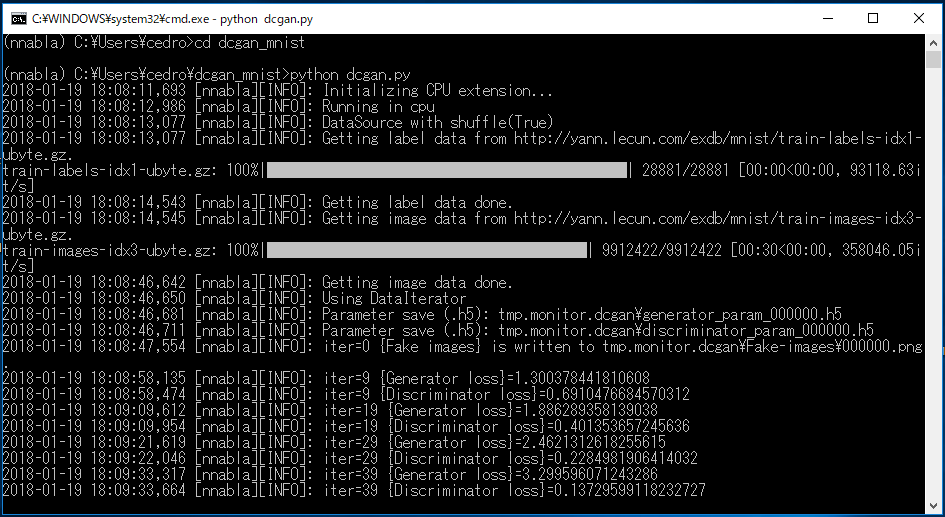
>cd dcgan_mnist でサンプルを動かすためのフォルダーに移動し
>python dcgan.py で実行します。
実行すると、まずMNISTのURLから学習のラベルデータと画像データをダウンロードし、処理を開始します。

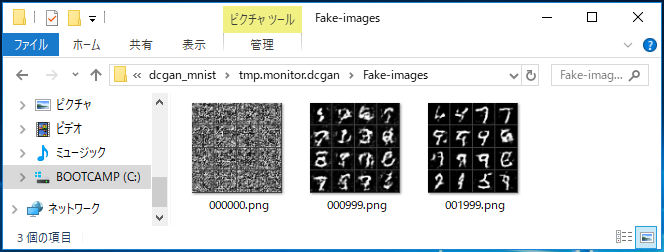
dcgan_mnist フォルダーの中には、tmp.monitor.dcagn > Fake-Image フォルダーが作られ、その中に1,000ステップ毎に、生成した画像を4×4のタイル状画像にしたものが、セーブされて行きます。
しばらく動かして、数字の画像生成の雰囲気を味わったら、Terminal を閉じて終了します。
DCGANサンプルを改造します
それでは、これから dcgan.py プログラムを3つのパートに分けて改造してみます。
1)データセット読み込み部分の改造
まず、自分が Neural Network Console で作ったオリジナルのCSV形式データセットを読み込める様にします。
NNabla には、CSV形式のデータセットを読み込むための機能が内蔵されていますので、これを API (Application Programming Interface) を通じて使います。
nnabla.utils.data_iterator.data_iterator_csv_dataset(uri, batch_size, shuffle, rng=None, normalize=True, with_memory_cache=True, with_file_cache=True, cache_dir=None, epoch_begin_callbacks=[], epoch_end_callbacks=[])
これがCSV形式のデータセットを読み込むためのAPIです(Document はここ)。
API の名前は、nnabla.utils.data_iterator.data_iterator_csv_dataset 。長いですね。
( )内はパラメーターで、全部で10個あります。えーっ、いちいち10個も指定するの?
いえいえ、必ず指定しなければならないのは、デフォルト値が無い ( = ○○○が書いてない )ものだけです。
デフォルト値が有るものは、指定しなければ、自動的にデフォルト値を指定したことになります。便利な仕組みですね。
今回、デフォルト値がないのは、uri, batch_size, shuffle の3つです。これは指定しなければいけません。
指定する内容は、uri は読み込ませる ”CSVファイルの場所と名前”、batch_size はバッチサイズ、shuffle はシャッフルの有無です。
このAPIを利用するために、プログラムを2箇所修正します。
なお、API の名前は、下記の様に2つに分けます。
API前半 = nnabla.utils.data_iterator、API 後半 = data_iterator_csv_dataset 。
|
1 2 3 4 5 |
#修正前 from mnist_data import data_iterator_mnist #修正後 import nnabla.utils.data_iterator as d |
どんな機能を使うか冒頭で宣言する部分です。
修正前は、「 from プログラム名(.pyは省略) import 機能名 」と宣言しています。これは、mnist_data.pyというプログラムの data_iterator_mnist という機能を使うよ、という意味です。
修正後は、「 import API前半 as 省略名 」と宣言します。これは、nnabla.utils.data_iterator というAPIをdと省略して使うよ、という意味です。
|
1 2 3 4 5 |
#修正前 data = data_iterator_mnist(args.batch_size, True) #修正後 data = d.data_iterator_csv_dataset(".\\face28_train.csv", args.batch_size, shuffle=True, normalize=False) |
データを読み込む部分です。
修正前は、data = data_iterator_mnist(パラメーター) と書いています。
修正後は、data = d. API後半(パラメーター)と書きます。dはAPI前半のことですね。
パラメーターは、”CSVファイルの場所と名前”、バッチサイズ、シャッフル有、ノーマライズ無 と4つ書いています。
4つ目に、ノーマライズ無とあえて指定するのは、dcgan.pyはデータを読み込んでからノーマライズをかける仕様になっているのに、APIもノーマライズ有がデフォルトになっているためです。ノーマライズをダブルでかけない様に、キャンセルしているわけです。
2)ネットワーク部分の改造
自分で作った顔画像のデータセットはカラー64×64サイズなので、長時間を掛けて質を追求する方法もあるわけですが、そうするとかなり時間がかかります。今回は、サクッとやってみたかったので、顔画像データをカラー28×28サイズに縮小して使うことにしました。
MNISTはモノクロ28×28なので、ネットワーク部分の改造は、モノクロから カラーへ変更するだけです。
|
1 2 3 4 5 |
# (32, 28, 28) --> (1, 28, 28) with nn.parameter_scope("conv5"): x = F.tanh(PF.convolution(d4, 1, (3, 3), pad=(1, 1))) |
これはジェネレーターの出力部分です。
x = F.tanh(PF.convolution(d4, 1, (3, 3), pad=(1, 1))) の部分を
|
1 2 3 4 5 |
# (32, 28, 28) --> (1, 28, 28) with nn.parameter_scope("conv5"): x = F.tanh(PF.convolution(d4, 3, (3, 3), pad=(1, 1))) |
x = F.tanh(PF.convolution(d4, 3, (3, 3), pad=(1, 1))) と変更します。
|
1 2 3 4 5 6 7 |
# Real path x = nn.Variable([args.batch_size, 1, 28, 28]) pred_real = discriminator(x) loss_dis += F.mean(F.sigmoid_cross_entropy(pred_real, F.constant(1, pred_real.shape))) |
これは、ディスクリミネーターの入力部分です。
x = nn.Variable([args.batch_size,1,28,28]) の部分を
|
1 2 3 4 5 6 |
# Real path x = nn.Variable([args.batch_size, 3, 28, 28]) pred_real = discriminator(x) loss_dis += F.mean(F.sigmoid_cross_entropy(pred_real, F.constant(1, pred_real.shape))) |
x = nn.Variable([args.batch_size,3,28,28]) と変更します。
3)モニター部分の改造
最後に、モニター部分の改造です。
dcgan.py は、1,000ステップ毎に、生成した画像を4×4のタイル状画像にして出力します。でも、せっかくならもっと頻繁に、もっと大きいサイズで出力させたいので、モニターのAPIを修正します。
nnabla.monitor.MonitorImageTile(name, monitor, interval=1000, verbose=True, num_images=16, normalize_method=None)
これが、画像をタイル状に出力するAPIです(Document はここ)。
確かに、interval=1000, num_image=16(4×4)がデフォルトになっていますので、ここを指定すればよいですね。ちなみに、num_image の設定値は、Batch_Sizeより小さくして下さいね(そうでないと画像が欠損します)。
|
1 2 3 4 5 6 7 8 |
変更前 monitor_fake = M.MonitorImageTile( "Fake image", monitor, normalize_method=lambda x: x+1/2.) 変更後 monitor_fake = M.MonitorImageTile( "Fake image , monitor, interval=100, num_images=64, normalized_method=lambda x: x+1/2) |
dcgan.py は、このAPIを既に使っていますので、該当する場所に、interval=100, num_images=64(8 × 8) を追加するだけです。これで、生成した画像が、100ステップ毎に、8×8のタイル状画像で出力されることになります。
動かしてみます

dcgan_face フォルダーを作成し、必要なプログラムを格納します。
データセットの読み込みは、APIを通じて、dcgan.py で行うようになったので、mnist_data.py はもう不要ですね。
追加するのは、Neural Network Console で作成したCSVファイル( face28_train.csv )と画像データが入ったフォルダー(2)です。
それでは、早速動かしてみましょう。
> cd dcgan_face でプログラムの入ったフォルダーに移動し、
> python dcgan.py でプログラムを実行します。

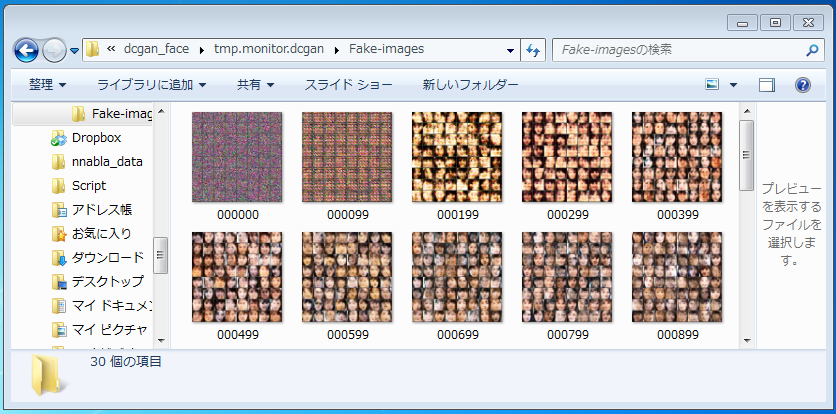
フォルダーの中に作られる、tmp.monitor.dcgan > Fake-images フォルダーを見ると。おおっ!ちゃんと100ステップ毎に、生成した画像を8×8のタイル状画像にして記録しています。
200ステップで、顔の片鱗の様なものが現れ始めます。5分置きに作成される画像を眺めていると、結構和めます(笑)。
約3時間20分かけて、4,000ステップまでやってみました。せっかくなので、記録した40枚の8×8タイル状画像をGIF動画にしてみますね。


3時間20分を8秒に短縮してお届けします。実際の画像生成の状況を1500倍のスピードで見ていることになります(笑)。
このあたりのステップ数だと、まだ大雑把に顔の輪郭を学習している段階で、細部の作り込みはこれからでしょうか。
ちなみに、このGIF動画は、GIFアニメ加工 というサイトで作りました。このサイトは、40枚までの静止画をアップでき、切り替え時間を設定すると、GIF動画を自動的に作ってくれます。
NNabla の理解がまた一歩深まりました
極々簡単な改造ですが、NNablaのプログラムを、オリジナルのデータセットを読み込ませる形にし、処理の内容を一部変更し、自分の好みの出力にするようにしてみました。
後は、APIを調べると、もっと色々なことができそうですね。
では、また。