

1.はじめに
動画から人物の3Dモデルを作成する手法が進歩しています。今回ご紹介するのは、PyMAFという手法で、以前より実際と3Dモデルの誤差が小さくなっています。
*この論文は、2021.4に提出されました。
2.PyMAFとは?
PyMAFは、Pyramidal Mesh Alignment Feedback Loop の略で、以下にそのフローを示します。

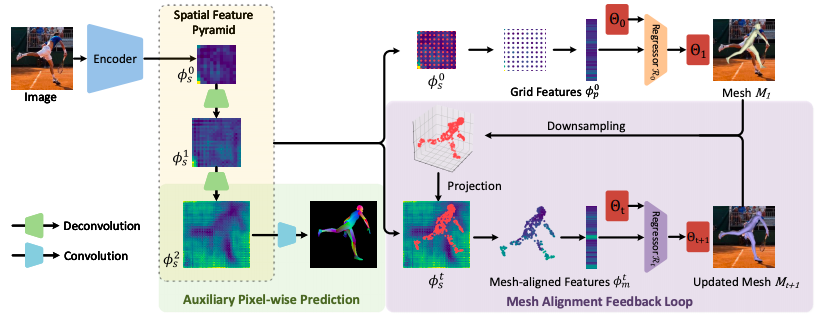
まず、画像から Encoder を通して特徴量を取り出し、Spatial Feature Pyramid で、その特徴量を何段階かアップサンプリングしたものを作ります。
次に、この特徴量を元に回帰でメッシュを求めますが、一度の回帰で求めたパラメータではメッシュと実際にズレが生じます。そこで、Mesh Alignment Feedback Loop で、求めたメッシュをダウンサンプリングしたものと特徴量からパラメータを修正するループを廻し、パラメータを最適化します。
一方で、Spatial Feature Pyramid から Auxiliary Pixel-wise Prediction(補助的なピクセル単位の予測)を求めてプロセスを監視し、ノイズ低減と信頼性向上に役立てます。
では、コードを試してみましょう。
3.コード
コードはオリジナルを少しいじったものをGithubに上げてあります。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#@title セットアップ # githubからコードを取得 ! git clone https://github.com/sugi-san/PyMAF.git %cd PyMAF # 必要なファイルをダウンロード ! wget --no-check-certificate "https://onedrive.live.com/download?cid=DF2414B28D1B6A99&resid=DF2414B28D1B6A99%21862&authkey=AJqiZVYmJa6jgoU" -O pymaf_data_for_demo.zip ! unzip pymaf_data_for_demo.zip # pytorchバージョン変更 ! pip install -U https://download.pytorch.org/whl/cu100/torch-1.1.0-cp37-cp37m-linux_x86_64.whl ! pip install -U https://download.pytorch.org/whl/cu100/torchvision-0.3.0-cp37-cp37m-linux_x86_64.whl # ライブラリーインストール ! pip install -r requirements.txt ! pip install imageio==2.4.1 ! pip install pyglet==1.5.27 # 関数読み込み from function import * |
それでは、3Dモデルの推定を行います。video に音声付き動画ファイル名(*.mp4)を指定して実行します。ここでは、video = sample3.mp4 と指定しています。自分の用意した動画を使う場合は、videoフォルダにアップロードして下さい。
なお、動画の生成時間は、元動画に写っている人物の数が多いと長くなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#@title 3Dモデルの推定 video = 'sample3.mp4' #@param {type:"string"} video_path = 'video/'+video # モデル推定 ! python3 demo.py --checkpoint=data/pretrained_model/PyMAF_model_checkpoint.pt\ --vid_file $video_path # 推定動画の作成 print('making video...') fps = get_fps(video_path) dir_name = 'output/'+os.path.splitext(video)[0]+'/'+os.path.splitext(video)[0]+'_mp4_output' file_name = dir_name+'/%6d.png' ! ffmpeg -y -r $fps -i $file_name -vcodec libx264 -pix_fmt yuv420p -loglevel error out.mp4 # 音声の抽出&付加 print('preparation for sound...') ! ffmpeg -y -i $video_path -loglevel error sound.mp3 ! ffmpeg -y -i out.mp4 -i sound.mp3 -loglevel error output.mp4 |
保存された動画の再生は、以下を実行して下さい。
|
1 2 |
#@title 動画の再生 display_mp4('output.mp4') |
作成した動画のダウンロードは、以下を実行して下さい(Chrome専用です)。
|
1 2 3 4 5 6 7 8 9 |
#@title 動画のダウンロード(chrome専用) import os import shutil from google.colab import files name = os.path.splitext(video) file_name = name[0]+'_3d.mp4' shutil.copy('output.mp4', 'download/'+file_name) files.download('download/'+file_name) |
では、また。
(オリジナルgithub)https://github.com/HongwenZhang/PyMAF
(Twitterへの投稿)