

今回は、SSDの学習済みモデルを使って物体検出をやってみます。
こんにちは cedro です。
以前、YOLOv3 で物体検出をやってみましたが、PyTorchでももちろんできます。
PyTorchでは、YOLOv3と同様に、バウンディングボックスの検出とクラス分類を平行して行うことで、高速な物体検出を実現したSSD(Single Shot multibox Detection)というモデルが使えます。
ということで、今回は、SSDの学習済みモデルを使って物体検出をやってみます。
SSDとは

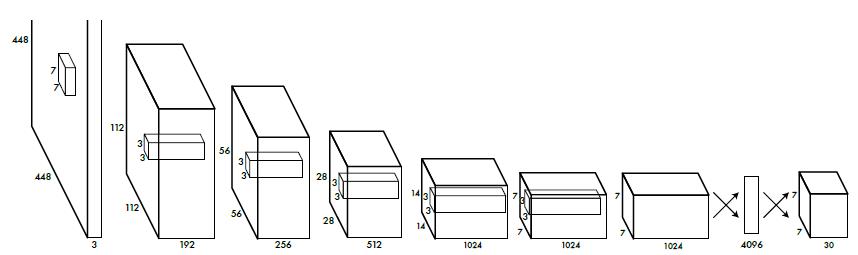
YOLOは、画像を7×7のグリッドに分割し、グリッド毎に物体検出とクラス分類を平行して行い、この結果を総合して適切なバウンディングボックスを求め、そのクラス分類結果を出力します。

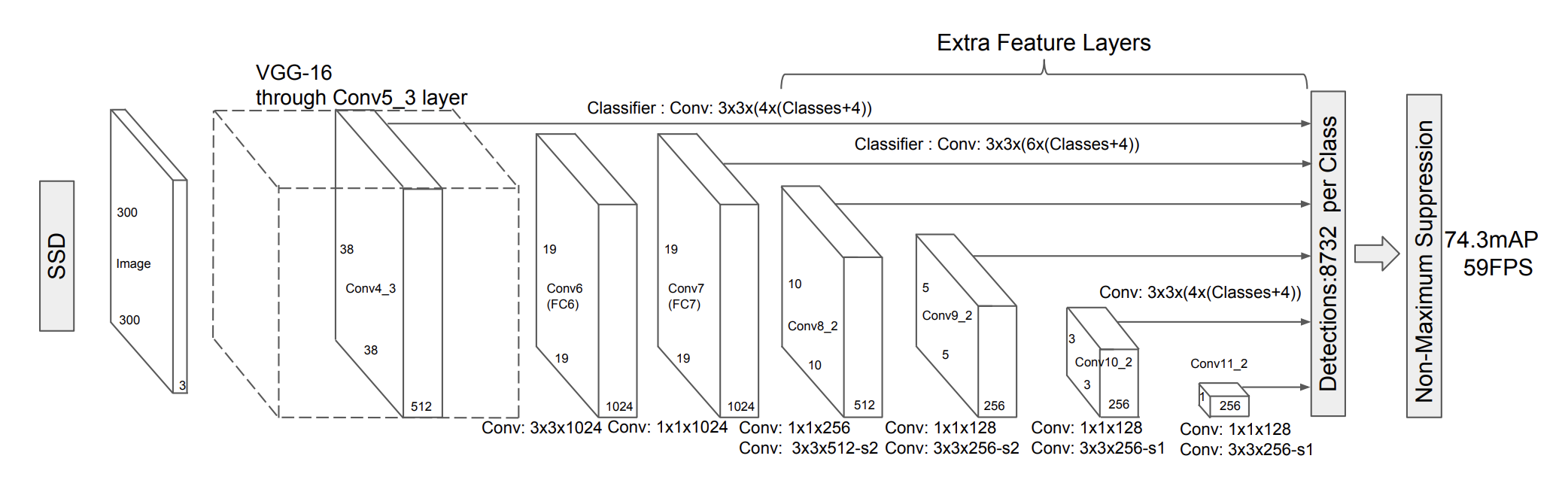

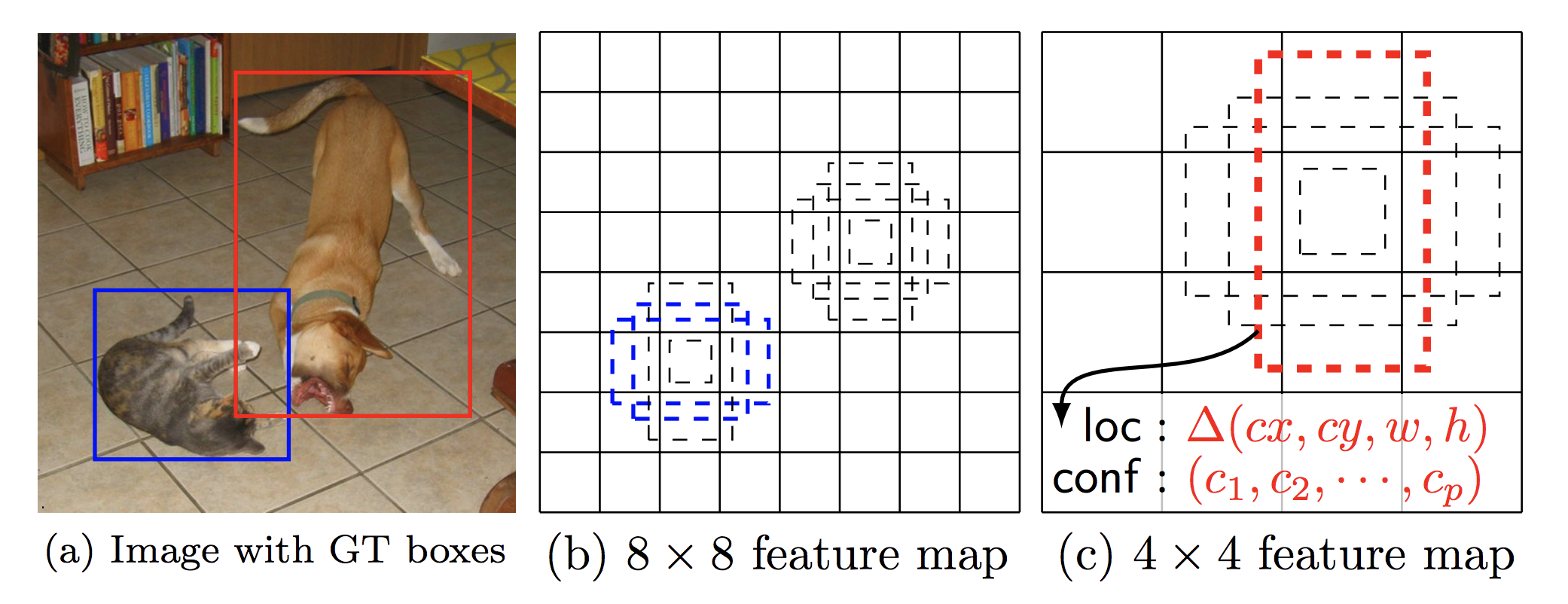
一方、SSDは、8732個のバウンディングボックスをあらかじめ設定し、バウンディングボックス毎に物体検出とクラス分類を平行して行い、最後に適切なバウンディングボックスを選択しそのクラス分類結果を出力します。

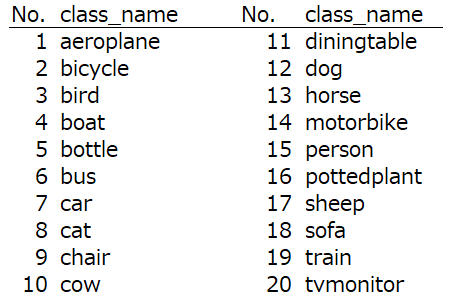
今回、使うSSD300の学習済みモデルが物体検出できるクラスは、この20種類です。
コードを書きます
今回は、学習済みモデルを使いますので、実行環境はノートパソコンで十分です。もし、PyTorch (Ver1.0)がまだインストール済みでなければ、PyTorchのホームページの説明に従ってインストールして下さい。
まず、Github からサンプルコードをクローンあるいはダウンロードします。今回使用するのは、Chapter7です。

Chapter7の中身です。ここに、demo2 フォルダーを追加します。今回作成するコードは、全てこのdemo2フォルダーの中に書きます。
また、SSDの学習済みモデル( ssd300_mAP_77.43_v2.pth )をダウンロードし、weights フォルダーに格納しておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
import os import sys module_path = os.path.abspath(os.path.join('..')) if module_path not in sys.path: sys.path.append(module_path) import torch import torch.nn as nn from torch.autograd import Variable import numpy as np import cv2 import glob from ssd import build_ssd from matplotlib import pyplot as plt # SSDモデルを読み込み net = build_ssd('test', 300, 21) net.load_weights('../weights/ssd300_mAP_77.43_v2.pth') # 関数 detect def detect(image, count): rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) x = cv2.resize(image, (300, 300)).astype(np.float32) # 300*300にリサイズ x -= (104.0, 117.0, 123.0) x = x.astype(np.float32) x = x[:, :, ::-1].copy() x = torch.from_numpy(x).permute(2, 0, 1) # [300,300,3]→[3,300,300] xx = Variable(x.unsqueeze(0)) # [3,300,300]→[1,3,300,300] # 順伝播を実行し、推論結果を出力 y = net(xx) from data import VOC_CLASSES as labels plt.figure(figsize=(10,6)) colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist() plt.imshow(rgb_image) currentAxis = plt.gca() # 推論結果をdetectionsに格納 detections = y.data # scale each detection back up to the image scale = torch.Tensor(rgb_image.shape[1::-1]).repeat(2) # バウンディングボックスとクラス名を表示 for i in range(detections.size(1)): j = 0 # 確信度confが0.6以上のボックスを表示 # jは確信度上位200件のボックスのインデックス # detections[0,i,j]は[conf,xmin,ymin,xmax,ymax]の形状 while detections[0,i,j,0] >= 0.6: score = detections[0,i,j,0] label_name = labels[i-1] display_txt = '%s: %.2f'%(label_name, score) pt = (detections[0,i,j,1:]*scale).cpu().numpy() coords = (pt[0], pt[1]), pt[2]-pt[0]+1, pt[3]-pt[1]+1 color = colors[i] currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2)) currentAxis.text(pt[0], pt[1], display_txt, bbox={'facecolor':color, 'alpha':0.5}) j+=1 plt.savefig('detect_img/'+'{0:04d}'.format(count)+'.png') plt.close() def main(): files = sorted(glob.glob('./image_dir/*.png')) count = 1 for i, file in enumerate (files): image = cv2.imread(file, cv2.IMREAD_COLOR) detect(image, count) print(count) count +=1 if __name__ == '__main__': main() |
SSDの学習済みモデルを使って、物体検出するコードです。学習済みモデルを読み込んだら、image_dir に格納されている画像(png)を1つづつ取り出し、画像を300×300にリサイズして物体検出し、バウンディングボックスとクラス名を書き込み、detect_img に画像(png)を保存します。
学習済みモデルの実行なので、あえてGPUは使わない仕様にしています。

先程のコードを ssd_model.py で保存します。そして、image_dir フォルダー(物体検知をしたい画像を入れる)とdetect_img フォルダー(物体検知の結果画像が出力される)を作成します。


この画像 ( cat_girl.png ) をimage_dir フォルダーに格納します。

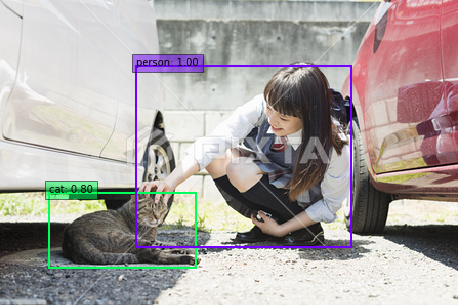
そして、ssd_model.py を実行すると、物体検出の結果画像 (0001.png) が、detect_img フォルダーに格納されます。
動画を物体検出してみる
物体検出と言えば、リアルタイムに物体検出している動画(バウンディングボックスとクラス名が連続的に表示されている)を見ることがあると思いますが、今回はあれを疑似的に再現したいと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import os import shutil import cv2 def video_2_frames(video_file='./india.mp4', image_dir='./image_dir/', image_file='img_%s.png'): # Initial setting i = 0 interval = 6 length = 60 cap = cv2.VideoCapture(video_file) while(cap.isOpened()): flag, frame = cap.read() if flag == False: break if i == length*interval: break if i % interval == 0: cv2.imwrite(image_dir+image_file % str(i).zfill(6), frame) print('Save', image_dir+image_file % str(i).zfill(6)) i += 1 cap.release() def main(): video_2_frames() if __name__ == '__main__': main() |
動画から静止画を切り出すコードです。demo2フォルダー内にある、Youtubeなどからダウンロードして来た動画(india.mp4) から、静止画を切り出して image_dir フォルダーに格納します。
interval = 6 は静止画を切り出す間隔です。通常動画は 30フレーム/秒 なので、 interval = 6 だと5フレーム/秒(0.2秒に1フレーム)の静止画を切り出すことになります。
length = 60 は先頭から何枚静止画を切り出すかの指定です。

先程のコードを mov_png.py という名前で保存し、静止画を切り出したい動画( india.mp4 )を demo2 フォルダーに格納します。
detect_img フォルダーと image_dir フォルダーの中身は一端クリアしておいて下さい。


mov_png.pyを実行すると、image_dir 内に動画の静止画が格納されます。


そして、ssd_model.py を実行すると、detect_img フォルダーの中に、物体検知をした画像が格納されます。
|
1 2 3 4 5 6 7 8 9 |
from PIL import Image import glob files = sorted(glob.glob('detect_img/*.png')) images = list(map(lambda file: Image.open(file), files)) images[0].save('india_ssd.gif', save_all=True, append_images=images[1:], duration=200, loop=0) |
静止画からGIF動画を作成するコードです。detect_img フォルダーに格納されている静止画からGIF動画(india_ssd.gif) を作成します。このコードを demo2 フォルダーにmake_gif.py で保存します。
duration = 200 はフレームの再生速度で単位はミリ秒。200だと1フレームの再生が0.2秒となります。loop = 0 は再生をループさせる設定です。

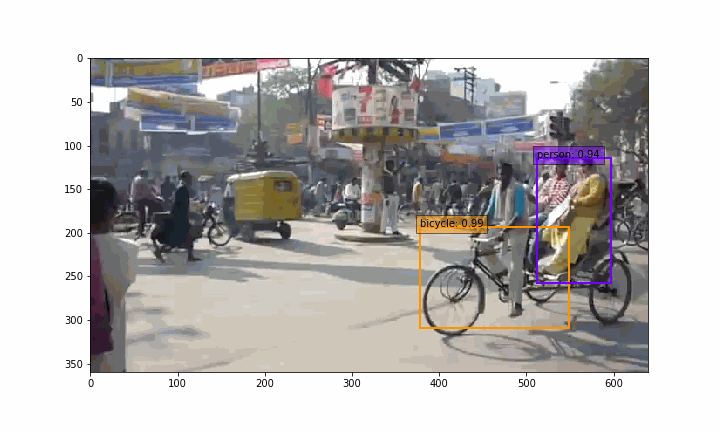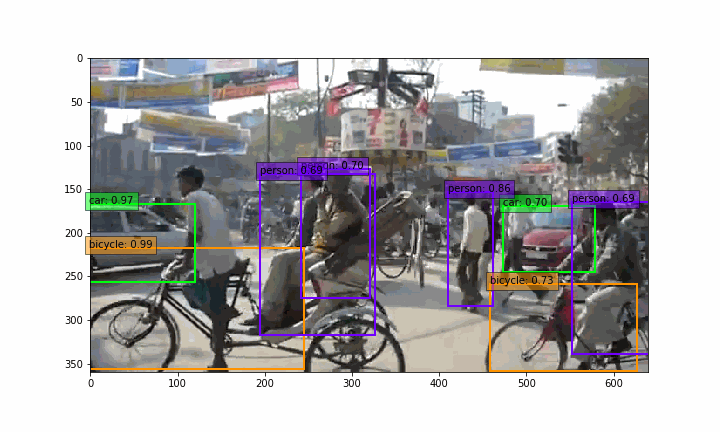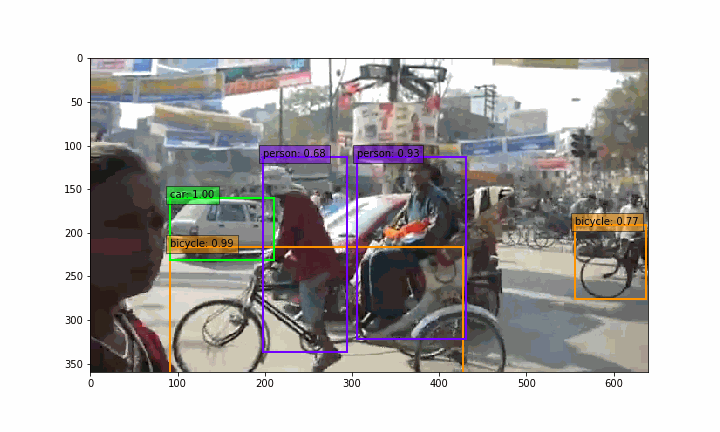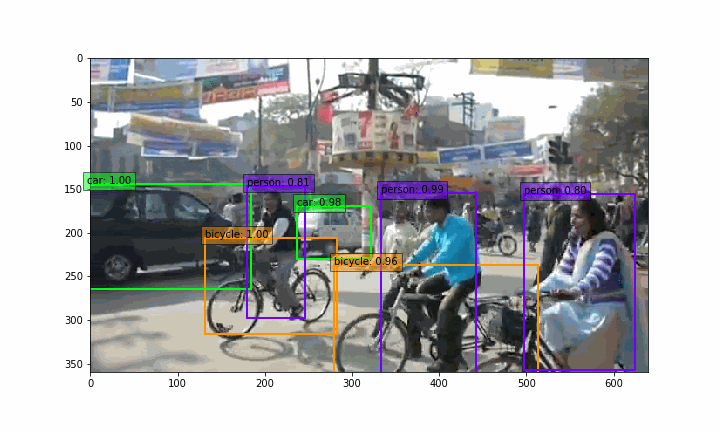
make_gif.py を実行すると、 demo2 フォルダーの中に、GIF動画(india_ssd.gif)が作成されます。
実は、静止画を物体検出しているだけですが、リアルタイム物体検出をしている様な雰囲気が出ますよね(笑)。
では、また。