
こんにちは cedro です。

CIFAR10などの画像データセットは、1枚の写真の中には必ず1つのクラスの物体しか写っていないわけですが、実際の写真を見てみると、人と犬が一緒に写っていたり、バイクの後ろに自動車が写っていたりと、1枚の写真の中に複数のクラスの物体が写っているのが普通です。
そのため、1枚の写真の中の、何処に、何が写っているのかを検出する、「物体検出」をしたいというニーズが出てきます。
今回は、物体検出をするニューラルネットワークの中で、特に高速処理が可能な「Yolo」の学習済みモデルを使って、Macでサクッと「物体検出」をやってみます。
Yoloって何?
「Yolo」とは、You only look once(あなたは一度見るだけです) の頭文字を取ったもので、物体の位置検出とクラス分類を同時に行うことで、高速処理を可能にしたニューラルネットワークです。
ちなみに、通常「Yolo」というと、You only live once(人生は一度きり)という意味なのですが、これをもじったと思われます。
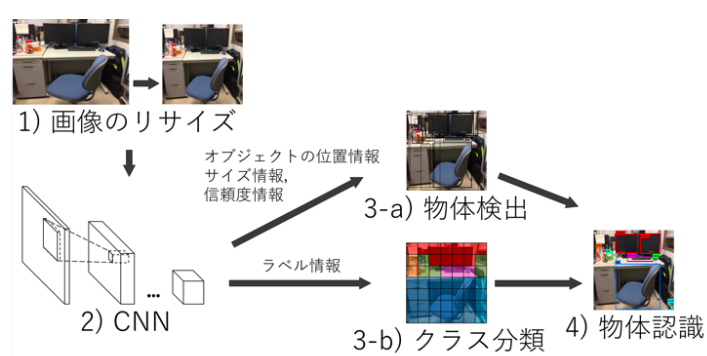
引用元:物体認識アルゴリズムを FPGA に実装するための基礎研究(吉元 裕真 、田向 権)
動作原理は、画像を正方形にリサイズした後、CNNで、バウンディングボックスと呼ばれる長方形の線による「物体検出」と7×7のグリッドそれぞれの「クラス分類」を並行して行い、最後にこの2つの結果を合体するというものです。
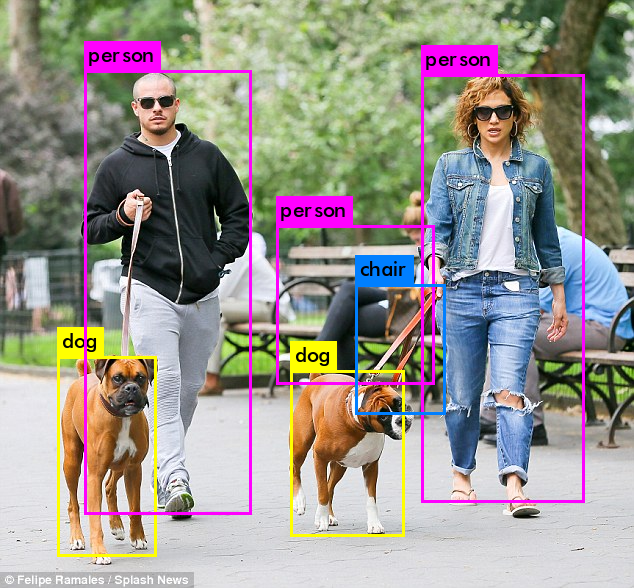
冒頭の写真で言うと、こんな出力結果になります。二匹の犬とそれを連れている人物二人、そして後ろにいる一人も検出しています。
Yoloをインストールします
インストール環境は以下の様です。
マシン:MacBook Air (13-inch,2017), 1.8GHz Core i5, メモリ8GB
OS : macOS Sierra 10.12.6
プログラム:Wgetインストール済み
Yoloの最新バージョンは Yolov3 で、前回と比べると若干スピードは落ちたものの、検出精度が大幅にアップしたとのことです。今回は、最新バージョンをインストールします。
|
1 2 3 4 5 6 7 8 9 |
JunnoMacBook-Air:~ cedro$ git clone https://github.com/pjreddie/darknet.git Cloning into 'darknet'... remote: Counting objects: 5792, done. remote: Total 5792 (delta 0), reused 0 (delta 0), pack-reused 5791 Receiving objects: 100% (5792/5792), 6.16 MiB | 842.00 KiB/s, done. Resolving deltas: 100% (3881/3881), done. |
git cloneで、自分のPCに「Yolo」のプログラムをコピーします。
git clone https://github.com/pjreddie/darknet.git と入力します。
|
1 2 3 4 5 6 7 8 9 10 |
JunnoMacBook-Air:~ cedro$ cd darknet JunnoMacBook-Air:darknet cedro$ make mkdir -p obj ・ ・ ・ obj/yolo.o obj/detector.o obj/nightmare.o obj/darknet.o libdarknet.a -o darknet -lm -pthread libdarknet.a clang: warning: argument unused during compilation: '-pthread' [-Wunused-command-line-argument] |
cd darknet と入力し、先程コピーしたフォルダーに移ります。
make と入力し、ビルドします。
|
1 2 3 |
JunnoMacBook-Air:darknet cedro$ ./darknet usage: ./darknet <function> |
ビルドできたか確認してみます。
./darknet と入力して、usage: ./darknet <fuction> と返ってくればOKです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
JunnoMacBook-Air:darknet cedro$ wget https://pjreddie.com/media/files/yolov3.weights --2018-05-26 08:25:11-- https://pjreddie.com/media/files/yolov3.weights pjreddie.com (pjreddie.com) をDNSに問いあわせています... 128.208.3.39 pjreddie.com (pjreddie.com)|128.208.3.39|:443 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 248007048 (237M) [application/octet-stream] `yolov3.weights' に保存中 yolov3.weights 100%[===================>] 236.52M 1.40MB/s 時間 2m 41s 2018-05-26 08:27:53 (1.47 MB/s) - `yolov3.weights' へ保存完了 [248007048/248007048] |
yolov3の重みパラメータ(237MB)をダウンロードします。
wget https://pjreddie.com/media/files/yolov3.weights と入力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
JunnoMacBook-Air:darknet cedro$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg layer filters size input output 0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs 1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs 2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BFLOPs 3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs ・ ・ ・ 103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs 106 yolo Loading weights from yolov3.weights...Done! data/dog.jpg: Predicted in 10.723442 seconds. bicycle: 99% truck: 92% dog: 99% |
まず、サンプル画像(dog.jpg)で物体検出してみます。
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg と入力します。
10秒ほど待つと、検出精度は、bicycle:99%、truck:92%、dog:99% (最後の3行)と出ました。
|
1 2 3 |
JunnoMacBook-Air:darknet cedro$ open predictions.png |
さて、検出結果を表示させてみましょう。
open predictions.png と入力します。

犬、自転車、トラックと3つのクラスの物体検出がされていますね。
これは、darknet フォルダーの中身です。結果の出力は、predictions.png に毎回上書きされていきますので、保存したい場合はコピーして下さい。
自分が物体検出させたい画像データを入れておく、pic フォルダーを追加しました。後は、
./darknet detect cfg/yolov3.cfg yolov3.weights pic/○○○.jpg と入力すれば物体検出します。
色々試して見る
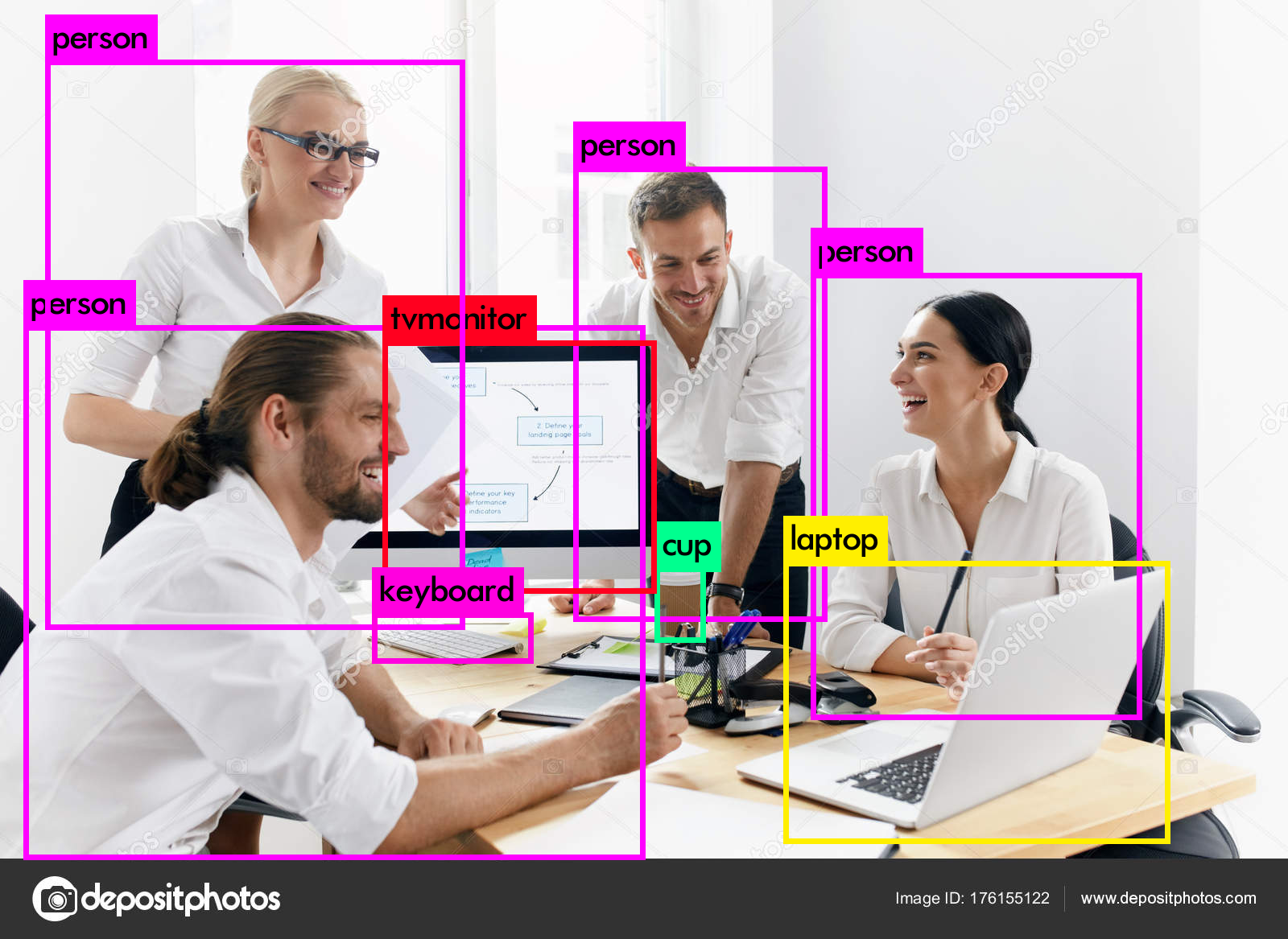
これはオフィスの写真。人物、TVモニター、キーボード、ラップトップ、カップと様々なクラスのものを物体検出していますね。
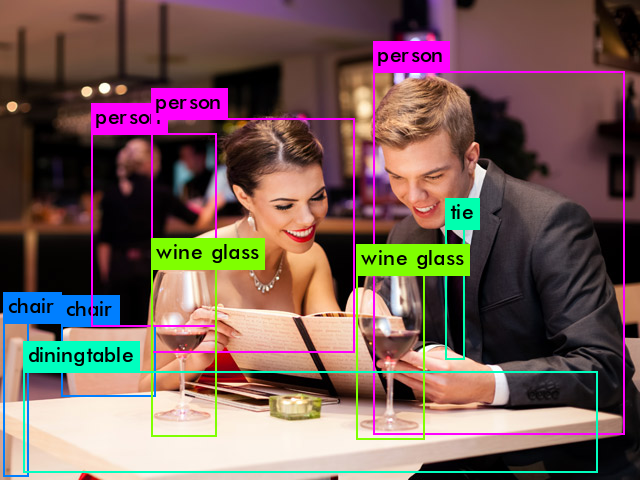
これは、レストランでデートでしょうか。人物、ワイングラス、イス、テーブルに加えて、ネクタイも物体検出していますね。

そして、これはインドの交差点。動画を静止画に切り出して物体検出し、その後GIF動画にしてみました。リアルタイム物体検出のイメージが湧くと思います(笑)。
こんなにも、手軽に物体検出ができるなんて凄過ぎる! 技術革新が日々進んでいる感じがします。
では、また。













cedroさん
お世話になっております。
hiroです。
あれから、neural network consoleを継続して使用しています。
そこで、お聞きしたいことが一点ありまして、今回ご連絡させていただきました。
本ツールの構造自動探索機能は、一つのネットワークグラフを繰り返し最適化してくれるものだと認識しております。
しかし、同じネットワークグラフを使い、データだけを繰り返し変更し、自動で連続して分析を行う方法はありますでしょうか。(その際のデータは、数値だけが異なり、行数や項目等は同じものを使用するものとします)
分析したい内容は同じでも、中身のデータだけが異なる場合は、通常であれば毎回データをセットし直し、実行を行う必要があると考えてます。しかし、その数が数百、数千とある場合においては、その都度手動で変更するのは大変ではないかと考えています。
自分でも調べていますが、未だ有力な情報に出会うことができておりません。
もし、自動でデータを変えて分析する機能について
ご存知であれば、ご教示いただけると幸いです。
ご検討の程よろしくお願い致します。
自分の持っている色々な写真から物体検出できて、新しい技術を身近に感じることができ、とても楽しかったです。
得にサンプルにあるような食卓の写真は、ワイングラス、ボトル、フォークなど細かいところもで拾ってくれ、美しいです。
Wgetのインストールを少し調べましたが、その他、教えていただいた手順で、すぐに動かすことができました。
ありがとうございます。
Mafaldine さんへ
コメントありがとうございます!
学習済みモデルが簡単に手に入るので、本当に手軽に物体認識が試せますよね。
AIの普及には目を見張るものがあります。
また、こういったネタを投稿して行きます。
今後とも、よろしくお願いします。
https://www.youtube.com/watch?v=XEuR5vkAPpA
おかげさまで、YOLO V3、ようやく、少し使えるようになりました。
cedroさんの説明、これからも楽しみにしています。
mafaldineさんへ
コメントありがとうございます!
それは、なによりです。
これからも、色々な事に挑戦して、分かったことをブログにして行きたいと思います。
今後とも、よろしくお願いします。
初めまして、「YOLOって何?」の下にある、YOLOの構成図の作者の吉元です。
この図を使用して頂いて大変うれしく思います。
ぜひ、引用元を明示して頂けないでしょうか。
よろしくお願いします。
吉元様
いつも大変お世話になります。
申し訳ございません。ご指摘の通りです。
ご指示の通り、引用元を追加させて頂きました。
この図は、WebにあるYOLOに関する説明の中で、たぶん最も分かり易くまとめた図だと思います。
今後とも、よろしくお願い致します。