

1.はじめに
StyleGANを使った画像編集には、編集する画像の潜在変数を求めるプロセスが必要です。今回ご紹介するのは、そのプロセスを高精度化・高速化するRestyleという技術です。
*この論文は、2021.4に提出されました。
2.ReStyleとは?
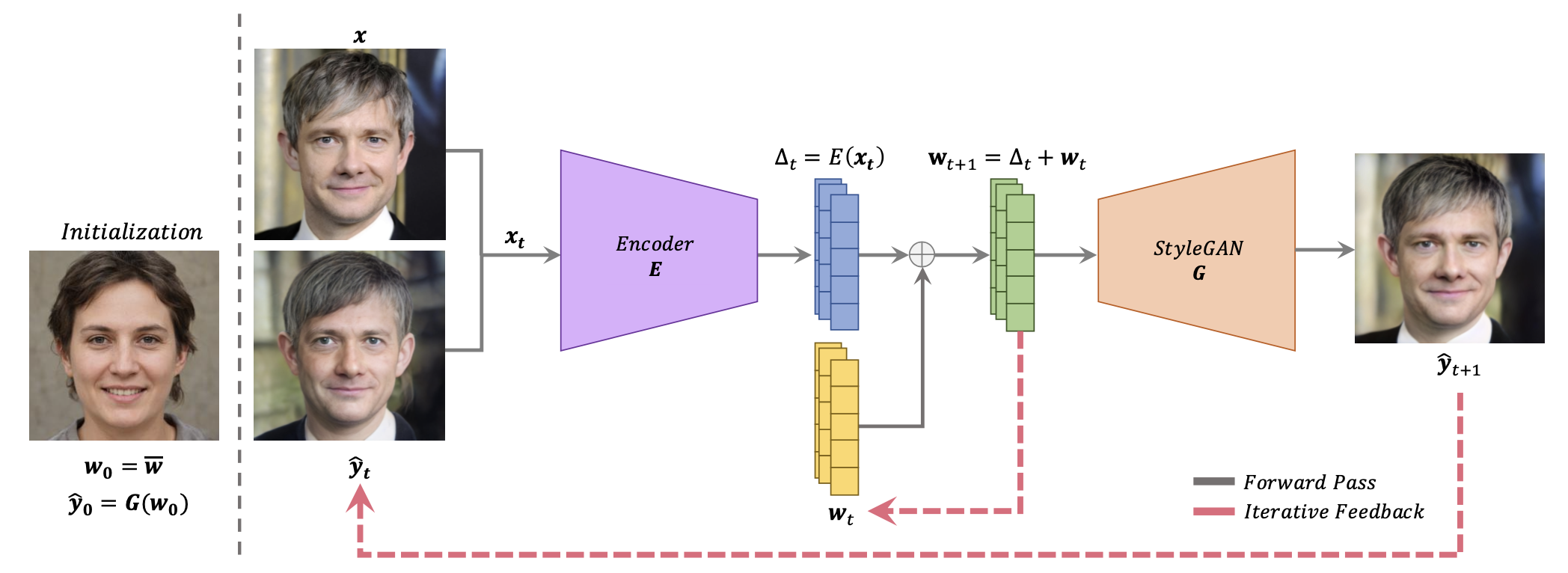
下記は、ReStyleのフローです。まず、潜在変数の平均W0をStyleGAN_Gに入力し、そのときの出力画像y0を求めて初期化します。
次に、潜在変数を求めたい画像xと出力画像y0をEncoder_Eに入力して残差△tを得ます。そして、残差△tに直前の潜在変数W0を加えてStyleGAN_Gに入力し、出力画像y1を求めます。そして、xとy1をEncoder_Eに入力することを繰り返します。
この一連のループを廻すことによって、Encoder_Eを使ってワンパスで推論するよりも精度が向上し、かつそのためのステップの増加は少なくて済む(N<10程度)ので、高精度化と高速化が両立するわけです。

3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。今回コードは非表示にしてあり、コードを確認したい場合は「コードの表示」をクリックすると見ることが出来ます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# githubからコードをコピー import os os.chdir('/content') CODE_DIR = 'restyle-encoder' !git clone https://github.com/yuval-alaluf/restyle-encoder.git $CODE_DIR # ninjaシステムインストール !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/ !sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force os.chdir(f'./{CODE_DIR}') # ライブラリーのインポート from argparse import Namespace import time import os import sys import pprint from tqdm import tqdm import numpy as np from PIL import Image import torch import torchvision.transforms as transforms import imageio import matplotlib from IPython.display import HTML from base64 import b64encode sys.path.append(".") sys.path.append("..") from utils.common import tensor2im from utils.inference_utils import run_on_batch from models.psp import pSp from models.e4e import e4e %load_ext autoreload %autoreload 2 # サンプル画像のダウンロード import gdown gdown.download('https://drive.google.com/uc?id=1EvinsyeqFSU982133ehKCC50IYR1109t', './notebooks/pic.zip', quiet=False) ! unzip -d notebooks notebooks/pic.zip |
次に、モデルを指定してダウンロードします。モデルは、6種類あるので色々試してみて下さい。ここでは、ffhq_encodeを指定します。


|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
# ダウンロード命令の作成 def get_download_model_command(file_id, file_name): """ Get wget download command for downloading the desired model and save to directory ../pretrained_models. """ current_directory = os.getcwd() save_path = os.path.join(os.path.dirname(current_directory), CODE_DIR, "pretrained_models") if not os.path.exists(save_path): os.makedirs(save_path) url = r"""wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id={FILE_ID}' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id={FILE_ID}" -O {SAVE_PATH}/{FILE_NAME} && rm -rf /tmp/cookies.txt""".format(FILE_ID=file_id, FILE_NAME=file_name, SAVE_PATH=save_path) return url MODEL_PATHS = { "ffhq_encode": {"id": "1sw6I2lRIB0MpuJkpc8F5BJiSZrc0hjfE", "name": "restyle_psp_ffhq_encode.pt"}, "cars_encode": {"id": "1zJHqHRQ8NOnVohVVCGbeYMMr6PDhRpPR", "name": "restyle_psp_cars_encode.pt"}, "church_encode": {"id": "1bcxx7mw-1z7dzbJI_z7oGpWG1oQAvMaD", "name": "restyle_psp_church_encode.pt"}, "horse_encode": {"id": "19_sUpTYtJmhSAolKLm3VgI-ptYqd-hgY", "name": "restyle_e4e_horse_encode.pt"}, "afhq_wild_encode": {"id": "1GyFXVTNDUw3IIGHmGS71ChhJ1Rmslhk7", "name": "restyle_psp_afhq_wild_encode.pt"}, "toonify": {"id": "1GtudVDig59d4HJ_8bGEniz5huaTSGO_0", "name": "restyle_psp_toonify.pt"} } path = MODEL_PATHS[experiment_type] download_command = get_download_model_command(file_id=path["id"], file_name=path["name"]) # パラメータの設定 EXPERIMENT_DATA_ARGS = { "ffhq_encode": { "model_path": "pretrained_models/restyle_psp_ffhq_encode.pt", "image_path": "notebooks/images/face_img.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "cars_encode": { "model_path": "pretrained_models/restyle_psp_cars_encode.pt", "image_path": "notebooks/images/car_img.jpg", "transform": transforms.Compose([ transforms.Resize((192, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "church_encode": { "model_path": "pretrained_models/restyle_psp_church_encode.pt", "image_path": "notebooks/images/church_img.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "horse_encode": { "model_path": "pretrained_models/restyle_e4e_horse_encode.pt", "image_path": "notebooks/images/horse_img.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "afhq_wild_encode": { "model_path": "pretrained_models/restyle_psp_afhq_wild_encode.pt", "image_path": "notebooks/images/afhq_wild_img.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "toonify": { "model_path": "pretrained_models/restyle_psp_toonify.pt", "image_path": "notebooks/images/toonify_img.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, } # モデルのダウンロード EXPERIMENT_ARGS = EXPERIMENT_DATA_ARGS[experiment_type] if not os.path.exists(EXPERIMENT_ARGS['model_path']) or os.path.getsize(EXPERIMENT_ARGS['model_path']) < 1000000: print(f'Downloading ReStyle model for {experiment_type}...') os.system(f"wget {download_command}") # if google drive receives too many requests, we'll reach the quota limit and be unable to download the model if os.path.getsize(EXPERIMENT_ARGS['model_path']) < 1000000: raise ValueError("Pretrained model was unable to be downloaded correctly!") else: print('Done.') else: print(f'ReStyle model for {experiment_type} already exists!') # モデルのロード model_path = EXPERIMENT_ARGS['model_path'] ckpt = torch.load(model_path, map_location='cpu') opts = ckpt['opts'] opts['checkpoint_path'] = model_path opts = Namespace(**opts) if experiment_type == 'horse_encode': net = e4e(opts) else: net = pSp(opts) net.eval() net.cuda() print('Model successfully loaded!') |
次に、関数定義と設定を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# 関数定義 def generate_mp4(out_name, images, kwargs): writer = imageio.get_writer(out_name + '.mp4', **kwargs) for image in images: writer.append_data(image) writer.close() def run_on_batch_to_vecs(inputs, net, opts): opts.resize_outputs = False opts.n_iters_per_batch = 5 with torch.no_grad(): _, result_batch = run_on_batch(inputs.to("cuda").float(), net, opts, avg_image) return result_batch[0][-1] def get_result_from_vecs(vectors_a, vectors_b, alpha): results = [] for i in range(len(vectors_a)): with torch.no_grad(): cur_vec = vectors_b[i] * alpha + vectors_a[i] * (1 - alpha) res = net(torch.from_numpy(cur_vec).cuda().unsqueeze(0), randomize_noise=False, input_code=True, input_is_full=True, resize=False) results.append(res[0]) return results def show_mp4(filename, width): mp4 = open(filename + '.mp4', 'rb').read() data_url = "data:video/mp4;base64," + b64encode(mp4).decode() display(HTML(""" <video width="%d" controls autoplay loop> <source src="%s" type="video/mp4"> </video> """ % (width, data_url))) # 潜在変数データの平均値を取得 avg_image = net(net.latent_avg.unsqueeze(0), input_code=True, randomize_noise=False, return_latents=False, average_code=True)[0] avg_image = avg_image.to('cuda').float().detach() if opts.dataset_type == "cars_encode": avg_image = avg_image[:, 32:224, :] # 設定 SEED = 42 np.random.seed(SEED) img_transforms = EXPERIMENT_ARGS['transform'] root_dir = "notebooks/images/" image_names = ['', '', '', '', ''] image_paths = [os.path.join(root_dir, image) + '.jpg' for image in image_names] # imagesフォルダーをリセット import os import shutil if os.path.isdir('notebooks/images'): shutil.rmtree('notebooks/images') os.makedirs('notebooks/images', exist_ok=True) |
次に、Align(顔部分を所定の位置に合わせ角度も考慮して切り取る)を実行します。picフォルダーにあるサンプル画像をAlignし、imagesフォルダーに保存します。
*ffhq_encoder, toonify 以外のモデルを指定した場合や、align済みの画像がある場合は、このブロックをスキップして、imagesフォルダーに画像(jpg)をアップロードして下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
def run_alignment(image_path): import dlib from scripts.align_faces_parallel import align_face if not os.path.exists("shape_predictor_68_face_landmarks.dat"): print('Downloading files for aligning face image...') os.system('wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2') os.system('bzip2 -dk shape_predictor_68_face_landmarks.dat.bz2') print('Done.') predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") aligned_image = align_face(filepath=image_path, predictor=predictor, output_size=256, transform_size=256) print("Aligned image has shape: {}".format(aligned_image.size)) return aligned_image ALIGN_IMAGES = True import glob import os image_paths = glob.glob('./notebooks/pic/*.jpg') image_names = os.listdir('./notebooks/pic') image_paths.sort() image_names.sort() # ffhq_encoderかtoonifyのときのみalignを実行 if ALIGN_IMAGES and experiment_type in ["ffhq_encode", "toonify"]: aligned_image_paths = [] for image_name, image_path in zip(image_names, image_paths): print(f'Aligning {image_name}...') aligned_image = run_alignment(image_path) aligned_path = os.path.join(root_dir, f'{image_name}_aligned.jpg') # save the aligned image aligned_image.save(aligned_path) aligned_image_paths.append(aligned_path) # use the save aligned images as our input image paths image_paths = aligned_image_paths |
images フォルダーにある画像から潜在変数を求めます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import glob image_paths = glob.glob('notebooks/images/*.jpg') image_paths.sort() in_images = [] all_vecs = [] if experiment_type == "cars_encode": resize_amount = (512, 384) else: resize_amount = (opts.output_size, opts.output_size) for image_path in image_paths: print(f'Working on {os.path.basename(image_path)}...') original_image = Image.open(image_path) original_image = original_image.convert("RGB") input_image = img_transforms(original_image) with torch.no_grad(): result_vec = run_on_batch_to_vecs(input_image.unsqueeze(0), net, opts) all_vecs.append([result_vec]) in_images.append(original_image.resize(resize_amount)) |
求めた潜在変数を元に補完画像を生成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
n_transition = 25 if experiment_type == "cars_encode": SIZE = 384 else: SIZE = opts.output_size images = [] image_paths.append(image_paths[0]) all_vecs.append(all_vecs[0]) in_images.append(in_images[0]) for i in range(1, len(image_paths)): if i == 0: alpha_vals = [0] * 10 + np.linspace(0, 1, n_transition).tolist() + [1] * 5 else: alpha_vals = [0] * 5 + np.linspace(0, 1, n_transition).tolist() + [1] * 5 for alpha in tqdm(alpha_vals): image_a = np.array(in_images[i - 1]) image_b = np.array(in_images[i]) image_joint = np.zeros_like(image_a) up_to_row = int((SIZE - 1) * alpha) if up_to_row > 0: image_joint[:(up_to_row + 1), :, :] = image_b[((SIZE - 1) - up_to_row):, :, :] if up_to_row < (SIZE - 1): image_joint[up_to_row:, :, :] = image_a[:(SIZE - up_to_row), :, :] result_image = get_result_from_vecs(all_vecs[i - 1], all_vecs[i], alpha)[0] if experiment_type == "cars_encode": result_image = result_image[:, 64:448, :] output_im = tensor2im(result_image) res = np.concatenate([image_joint, np.array(output_im)], axis=1) images.append(res) |
作成した補完画像からmp4を作成します。
|
1 2 3 4 5 6 7 |
kwargs = {'fps': 15} save_path = "notebooks/animations" os.makedirs(save_path, exist_ok=True) gif_path = os.path.join(save_path, f"{experiment_type}_gif") generate_mp4(gif_path, images, kwargs) show_mp4(gif_path, width=opts.output_size) |


左が実写、右が実写から潜在変数を逆算して生成した画像です。潜在変数を補完(ある潜在変数からある潜在変数へ少しづつ変化させる)しているので、連続的に変化する動画になります。
それでは、モデル指定のところを「toonify」に変更して、そこから順番に再度実行すると、

今度は、左が実写、右が3Dアニメ顔です。3Dアニメ顔を生成するtoonifyモデルは、入力がffhq_encodeと同じなので、面白い動画になりますね。
では、また。
(オリジナルgithub)https://github.com/yuval-alaluf/restyle-encoder