

1.はじめに
「目があの人の様なパッチリした二重だったら」とか、「鼻があの人のような高い鼻だったら」などと思ったことはありませんか。
今回ご紹介するのは、顔画像の特徴だけを別の画像のものに置き換えることができる Retrieve in Style(RIS)という技術です。
2.Retrieve in Style(RIS)とは?
ソース画像に参照画像のある特徴 k を転送するときに、今までは大規模なデータからチャンネル c の寄与スコア Mk,c を平均的に求めて、補完ベクトルを取得していました。しかし、この方法はある特徴(髪の毛・ポーズ)では上手く行かないことが分かっていました。
これは、チャンネルの寄与スコア Mk,c は画像によって異なるため、平均すると固有の特徴が破壊されることを示しています。そこで、サブメンバーシップというの概念を導入して、ソース画像と参照画像のみ(N=2)で寄与スコア Mk,c を求めて、補完ベクトルを取得するのが本論文の提案です。
寄与スコア Mk,c は下記の様に表されます。ここで、Aは活性化テンソル、Uはクラスターメンバーシップ、sはソース、rは参照、kは特徴、cはチャンネル数、hは高さ、wは幅です。

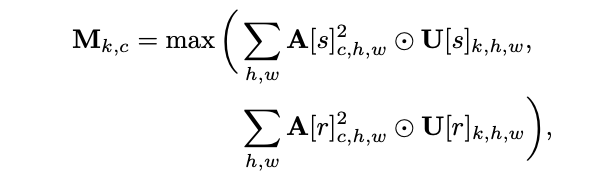
補完ベクトル q は下記の様に表されます。ここで、M は全ての特徴 k を積み重ねた寄与スコア、τ は温度です。

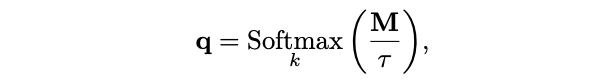
では、コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# githubからコードをコピー !git clone https://github.com/mchong6/RetrieveInStyle.git %cd RetrieveInStyle # ライブラリーのインストール !pip install tqdm gdown scikit-learn scipy lpips dlib opencv-python # ライブラリーのインポート import torch from torch import nn import numpy as np import torch.backends.cudnn as cudnn cudnn.benchmark = True import matplotlib.pyplot as plt import torch.nn.functional as F from model import * from spherical_kmeans import MiniBatchSphericalKMeans as sKmeans from tqdm import tqdm as tqdm import pickle import warnings warnings.filterwarnings("ignore", category=UserWarning) # get rid of interpolation warning from util import * from google.colab import files from util import align_face import os from e4e_projection import projection %matplotlib inline # 学習済みモデルのロード device = 'cuda' # if GPU memory is low, use cpu instead generator = Generator(1024, 512, 8, channel_multiplier=2).to(device).eval() ensure_checkpoint_exists('stylegan2-ffhq-config-f.pt') ckpt = torch.load('stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage) generator.load_state_dict(ckpt["g_ema"], strict=False) with torch.no_grad(): mean_latent = generator.mean_latent(50000) # カタログのロード truncation = 0.5 stop_idx = 11 # choose 32x32 layer to do kmeans clustering n_clusters = 18 # Number of Kmeans cluster clusterer = pickle.load(open("catalog.pkl", "rb")) |
最初に、顔画像の特徴を抽出します。Generatorにランダムベクトルを入力して得られた顔画像(1024×1024)を32×32の大きさでクラスタリング処理します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
plt.rcParams['figure.dpi'] = 150 with torch.no_grad(): sample_z = torch.randn([1, 512]).to(device) sample_w = generator.get_latent(sample_z, truncation=truncation, mean_latent=mean_latent) sample, outputs = generator(sample_w, is_cluster=1) # [b, c, h, w] # obtain 32x32 activations and classify using kmeans act = flatten_act(outputs[stop_idx][0]) b,c,h,w = outputs[stop_idx][0].size() alpha = 0.5 seg_mask = clusterer.predict(act) seg_mask = torch.from_numpy(seg_mask).view(1,h,w) seg_out = decode_segmap(seg_mask) sample_d = F.interpolate(sample, size=(256,256), mode='bilinear').cpu() seg_out_d = F.interpolate(seg_out, size=(256,256), mode='nearest') out = alpha*seg_out_d + (1-alpha)*sample_d display_image(out) |


目、眉、頬、口、髪の毛などがクラスタリングされていることがわかります。
クラスタリング結果を顔の特徴としてラベルを付けし、関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
#Gives an index to each feature we care about labels2idx = { 'nose': 0, 'eyes': 1, 'mouth':2, 'hair': 3, 'background': 4, 'cheeks': 5, 'neck': 6, 'clothes': 7, } # Assign to each feature the cluster index from segmentation labels_map = { 0: torch.tensor([7]), 1: torch.tensor([1,6]), 2: torch.tensor([4]), 3: torch.tensor([0,3,5,8,10,15,16]), 4: torch.tensor([11,13,14]), 5: torch.tensor([9]), 6: torch.tensor([17]), 7: torch.tensor([2,12]), } idx2labels = dict((v,k) for k,v in labels2idx.items()) n_class = len(labels2idx) # compute M given a style code. @torch.no_grad() def compute_M(w, device='cuda'): M = [] # get segmentation _, outputs = generator(w, is_cluster=1) cluster_layer = outputs[stop_idx][0] activation = flatten_act(cluster_layer) seg_mask = clusterer.predict(activation) b,c,h,w = cluster_layer.size() # create masks for each feature all_seg_mask = [] seg_mask = torch.from_numpy(seg_mask).view(b,1,h,w,1).to(device) for key in range(n_class): # combine masks for all indices for a particular segmentation class indices = labels_map[key].view(1,1,1,1,-1) key_mask = (seg_mask == indices.to(device)).any(-1) #[b,1,h,w] all_seg_mask.append(key_mask) all_seg_mask = torch.stack(all_seg_mask, 1) # go through each activation layer and compute M for layer_idx in range(len(outputs)): layer = outputs[layer_idx][1].to(device) b,c,h,w = layer.size() layer = F.instance_norm(layer) layer = layer.pow(2) # resize the segmentation masks to current activations' resolution layer_seg_mask = F.interpolate(all_seg_mask.flatten(0,1).float(), align_corners=False, size=(h,w), mode='bilinear').view(b,-1,1,h,w) masked_layer = layer.unsqueeze(1) * layer_seg_mask # [b,k,c,h,w] masked_layer = (masked_layer.sum([3,4])/ (h*w))#[b,k,c] M.append(masked_layer.to(device)) M = torch.cat(M, -1) #[b, k, c] # softmax to assign each channel to a particular segmentation class M = F.softmax(M/.1, 1) # simple thresholding M = (M>.8).float() # zero out torgb transfers, from https://arxiv.org/abs/2011.12799 for i in range(n_class): part_M = style2list(M[:, i]) for j in range(len(part_M)): if j in rgb_layer_idx: part_M[j].zero_() part_M = list2style(part_M) M[:, i] = part_M return M |
この後、顔画像の潜在変数を使ったデモを行います。自分で用意した画像を使用しない場合は、次のブロックだけパスして下さい。
自分で用意した画像を使用する場合は、PCからその画像をドラッグ&ドロップで RetrieveInStyle/images へアップロードして(複数OK)から、下記を実行して下さい。得られた潜在変数は、RetrieveInStyle/inversion_codes に同じファイル名+拡張子ptで保存されます。
|
1 2 3 4 5 6 |
import glob files = glob.glob('images/*.jpg') for file in files: filename = file[7:-4] cropped_face = align_face(file) projection(cropped_face, filename, generator, device) |
それでは、顔の特徴の転送を行なってみます。まず、転送先のソース画像と転送元の参照画像を表示します。10行目、14行目を修正するとソース画像と参照画像を変更できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
plt.rcParams['figure.dpi'] = 75 # load codes from inverted real images using our projection code with torch.no_grad(): ''' if you gan inverted in the previous cell, you can call it here with variable filename otherwise, you can randomly generate or call a pre-inverted image ''' # source = load_source([filename], generator, device) source = load_source(['brad_pitt'], generator, device) source_im, _ = generator(source) display_image(source_im, size=256) ref = load_source(['emma_watson', 'emma_stone', 'jennie'], generator, device) ref_im, _ = generator(ref) ref_im = downsample(ref_im) show(normalize_im(ref_im).permute(0,2,3,1).cpu(), title='References') |


ソース画像は 'brad_pitt'、参照画像は 'emma_watson'、'emma_stone'、'jennie' です。
ソース画像へ参照画像から転送する特徴は、'eyes'、 'nose'、 'mouth'、 'hair'、'pose' の5つです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Compute M for both source and reference images use cpu here to save memory source_M = compute_M(source, device='cpu') ref_M = compute_M(ref, device='cpu') # Find relevant channels for source and reference by taking max over their individual M max_M = torch.max(source_M.expand_as(ref_M), ref_M) max_M = add_pose(max_M, labels2idx) all_im = {} with torch.no_grad(): # features we are interest in transferring parts = ('eyes', 'nose', 'mouth', 'hair','pose') for label in parts: if label == 'pose': idx = -1 else: idx = labels2idx[label] part_M = max_M[:,idx].to(device) blend = style2list(add_direction(source, ref, part_M, 1.3)) blend_im, _ = generator(blend) blend_im = downsample(blend_im).cpu() all_im[label] = normalize_im(blend_im) part_grid(normalize_im(source_im.detach()), normalize_im(ref_im.detach()), all_im); |


ソース画像 'brad_pitt'の5つの特徴へ、参照画像のものが転送されています。
今度は、ソース画像へ参照画像から特徴を転送する度合いを変化させてみましょう。まず、ソース画像と参照画像を表示させます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
plt.rcParams['figure.dpi'] = 75 torch.manual_seed(3913) with torch.no_grad(): source = load_source(['emma_stone'], generator, device) source_im, _ = generator(source) display_image(source_im, size=256) ref = load_source(['brad_pitt'], generator, device) ref_im, _ = generator(ref) ref_im = downsample(ref_im) display_image(ref_im, title='reference') |


ソース画像が 'emma_stone'、参照画像が 'brad_pitt' です。
ソース画像へ参照画像から「目」と「髪型」を転送する度合いを変化させてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
plt.rcParams['figure.dpi'] = 200 source_M = compute_M(source, device='cpu') ref_M = compute_M(ref, device='cpu') max_M = torch.max(source_M.expand_as(ref_M), ref_M) max_M = add_pose(max_M, labels2idx) labels = ('eyes', 'hair') # choose what feature to interpolate {eyes/nose/mouth/hair/pose} max_alpha = 1.5 # max range to interpolate all_im = [] with torch.no_grad(): for label in labels: row = [] if label == 'pose': idx = -1 else: idx = labels2idx[label] for alpha in np.linspace(-max_alpha, max_alpha, 5): part_M = max_M[:,idx].to(device) blend = style2list(add_direction(source, ref, part_M, alpha)) blend_im, _ = generator(blend) blend_im = downsample(blend_im).cpu() row.append(blend_im) row.append(ref_im.cpu()) row = torch.cat(row, -1) all_im.append(row) all_im = torch.cat(all_im, 2) display_image(all_im, size=None) |


右端が参照画像、右から4列目がソース画像です。ソース画像から右へ行くほど参照画像の特徴に近くなり、左へ行くほど参照画像の特徴とは反対になります。
今度は、大量の顔画像データベースの中から、ソース画像の指定した特徴に近い画像を検索してみましょう。まず、generator にランダムベクトルを入力し、5000個の顔画像データベースを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 顔データベースの作成 torch.manual_seed(12390) num_data = 5000 dataset = torch.randn([num_data, 512]).to(device) with torch.no_grad(): dataset_w = generator.get_latent(dataset, truncation=truncation, mean_latent=mean_latent) dataset_M = [] for i in tqdm(range(num_data)): # have to use cuda for this or it will be very slow dataset_M.append(compute_M(index_layers(dataset_w, i), device='cuda')) dataset_M = remove_2048(torch.cat(dataset_M, 0), labels2idx).to(device) #[N, K, C] |
ソース画像を表示させます。
|
1 2 3 4 5 6 7 8 |
# 検索対象の表示 plt.rcParams['figure.dpi'] = 75 with torch.no_grad(): query_w = load_source(['tom_hiddleston'], generator, device) query_im, _ = generator(query_w) display_image(query_im) |


それでは、ソース画像の「目」、「口」、「髪型」の特徴に似ている画像を、5000個の顔画像データベースの中から検索してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 検索実行と結果表示 plt.rcParams['figure.dpi'] = 300 num_nn = 6 all_im = [] query_M = remove_2048(compute_M(query_w, device=device), labels2idx).to(device) r_query_w = list2style(query_w) r_dataset_w = list2style(dataset_w) # normalize each style dimension largest = r_dataset_w.abs().max(0, keepdim=True)[0] + 1e-8 norm_query_w = r_query_w/largest norm_target_w = r_dataset_w/largest # choose what features to perform retrieval on # parts = ('eyes', 'nose', 'mouth', 'hair') parts = ('eyes', 'mouth', 'hair',) # perform cosine similarity w.r.t a given feature with torch.no_grad(): for part in parts: idx = labels2idx[part] source_part = norm_query_w * query_M[:,idx].to(device) target_part = norm_target_w * dataset_M[:,idx].to(device) distance = cos_dist(target_part, source_part) nearest_neighbors = torch.sort(distance)[1][:num_nn] row = [query_im.cpu()] for idx in nearest_neighbors: nn_w = index_layers(dataset_w, int(idx)) nn_image, _ = generator(nn_w) row.append(nn_image.cpu()) row = [downsample(a) for a in row] row = torch.cat(row, -1) all_im.append(row) all_im = torch.cat(all_im,-2) display_image(all_im, size=None) |


特徴だけに絞って、検索できるといのは今までにはなかった取り組みです。
では、また。
(オリジナルgithub)https://github.com/mchong6/RetrieveInStyle