

1.はじめに
最近、D-IDという音声で顔画像を自然に動かすWebサービスが大流行りです。そんな中、今回ご紹介するのは、それと同様な機能を持つSadTalkerというオープンソース技術(CVPR 2023で発表予定)です。
*この論文は、2023.3に提出されました。
2.SadTalkerとは?
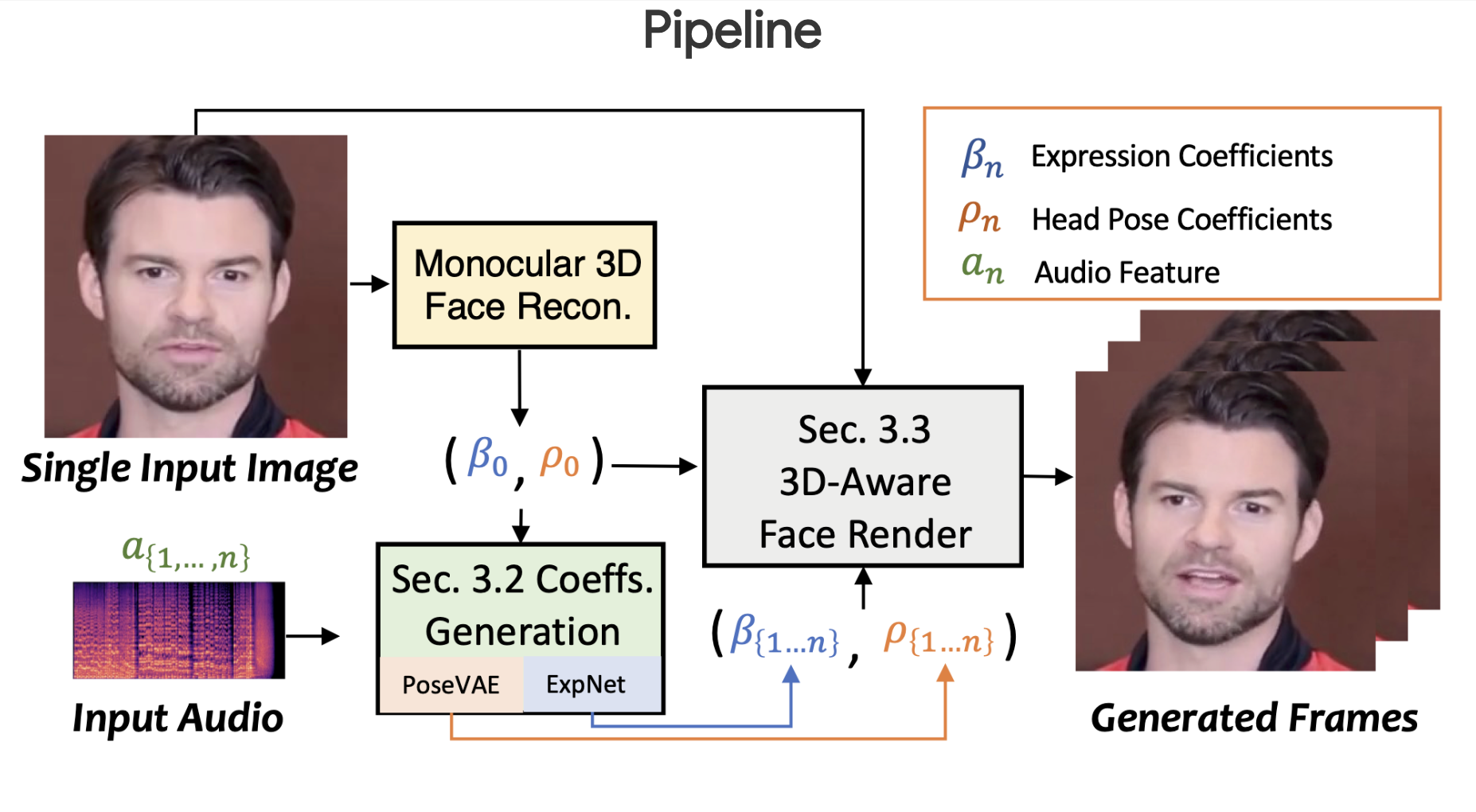
下記は、SadTalkerのパイプライン(Pipeline)です。まず、顔画像(Single Input Image)から3Dの顔画像を再構築(Monocular 3D Face Recon.)し、表情係数(Expression Coefficients)と頭のポーズ係数(Head Pose Coefficients)を抽出します。
次に、音声(Input Audio)から頭のポーズを学習するネットワーク(PoseVAE)と表情を学習するネットワーク(ExpNet)を用いて、これらの係数がどう変化するのかを求めます。
最後に、係数を元に3D対応の顔のレンダリング(3D-Aware Face Render)で合成されフレーム(Generated Frames)を生成します。

3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
まず、セットアップを行い、モデルをダウンロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#@title **setup(about 5 minutes)** !update-alternatives --install /usr/local/bin/python3 python3 /usr/bin/python3.8 2 !update-alternatives --install /usr/local/bin/python3 python3 /usr/bin/python3.9 1 !python --version !apt-get update !apt install software-properties-common !sudo dpkg --remove --force-remove-reinstreq python3-pip python3-setuptools python3-wheel !apt-get install python3-pip print('Git clone project and install requirements...') !git clone https://github.com/cedro3/SadTalker.git &> /dev/null %cd SadTalker !export PYTHONPATH=/content/SadTalker:$PYTHONPATH !python3.8 -m pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 !apt update !apt install ffmpeg &> /dev/null !python3.8 -m pip install -r requirements.txt |
|
1 2 3 4 |
#@title **download model(about 1 minute)** print('Download pre-trained models...') !rm -rf checkpoints !bash scripts/download_models.sh |
まず、顔画像と音声を指定して、音声で顔だけを動かしてみましょう。顔画像は、examples/source_imageの中から選んでimageに記入します。音声は、examples/driven_audioの中から選んでaudioに記入します。
自分で用意した顔画像や音声を使いたい場合は、examples/source_imageやexamples/driven_audioにアップロードして下さい。なお、作成した動画は、resultsにタイムスタンプ付きで保存されます。
|
1 2 3 4 5 6 7 8 9 |
#@title **inference for face** image ='full3.png' #@param {type:"string"} audio ='eluosi.wav' #@param {type:"string"} source_image = 'examples/source_image/' + image driven_audio = 'examples/driven_audio/' + audio !python3.8 inference.py --driven_audio $driven_audio \ --source_image $source_image \ --result_dir ./results --enhancer gfpgan |
作成した動画を再生します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#@title **play movie** import glob from IPython.display import HTML from base64 import b64encode import os, sys # get the last from results mp4_name = sorted(glob.glob('./results/*.mp4'))[-1] mp4 = open('{}'.format(mp4_name),'rb').read() data_url = "data:video/mp4;base64," + b64encode(mp4).decode() print('Display animation: {}'.format(mp4_name), file=sys.stderr) display(HTML(""" <video width=256 controls> <source src="%s" type="video/mp4"> </video> """ % data_url)) |
音声で顔だけを動かす場合は、頭の動きもあり割と自然に動かせます。
次に、顔画像と音声を指定して、音声でポートレイトを動かしてみましょう。顔画像は、examples/source_imageの中から選んでimageに記入します。音声は、examples/driven_audioの中から選んでaudioに記入します。
自分で用意した顔画像や音声を使いたい場合は、examples/source_imageやexamples/driven_audioにアップロードして下さい。なお、作成した動画は、resultsにタイムスタンプ付きで保存されます。
|
1 2 3 4 5 6 7 8 9 |
#@title **inference for portrait** image ='full3.png' #@param {type:"string"} audio ='eluosi.wav' #@param {type:"string"} source_image = 'examples/source_image/' + image driven_audio = 'examples/driven_audio/' + audio !python3.8 inference.py --driven_audio $driven_audio \ --source_image $source_image \ --result_dir ./results --still --preprocess full --enhancer gfpgan |
作成した動画を再生します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#@title **play movie** import glob from IPython.display import HTML from base64 import b64encode import os, sys # get the last from results mp4_name = sorted(glob.glob('./results/*.mp4'))[-1] mp4 = open('{}'.format(mp4_name),'rb').read() data_url = "data:video/mp4;base64," + b64encode(mp4).decode() print('Display animation: {}'.format(mp4_name), file=sys.stderr) display(HTML(""" <video width=256 controls> <source src="%s" type="video/mp4"> </video> """ % data_url)) |
音声でポートレイトを動かす場合は、頭の動きは比較的小さくなります。
(オリジナルgithub)https://github.com/OpenTalker/SadTalker
(Youtube投稿)
SadTalkerを使った動画例です。楽曲からの音声抽出にはDemucs、画像生成にはDream Boothを使っています。
