

1.はじめに
今回ご紹介するのは、文から画像を生成するモデルに動画と文のペアをファインチューニングし、文の変更によって動画の被写体、背景、属性、スタイルの変更を実現するTune-A-Videoという技術です。
*この論文は、2022.12に提出されました。
2.Tune-A -Videoとは?
文から動画を生成する技術は以前からありましたが、大規模なテキストとビデオのデータセットが必要で学習コストが極めて高いものでした。Tune-A-Videoは、文から画像を生成するモデルを下記のようにファインチューニングすることで学習コストを下げます。このとき、アテンションブロックの射影行列のみを更新して残りのパラメーターは固定することで効率化を図っています。

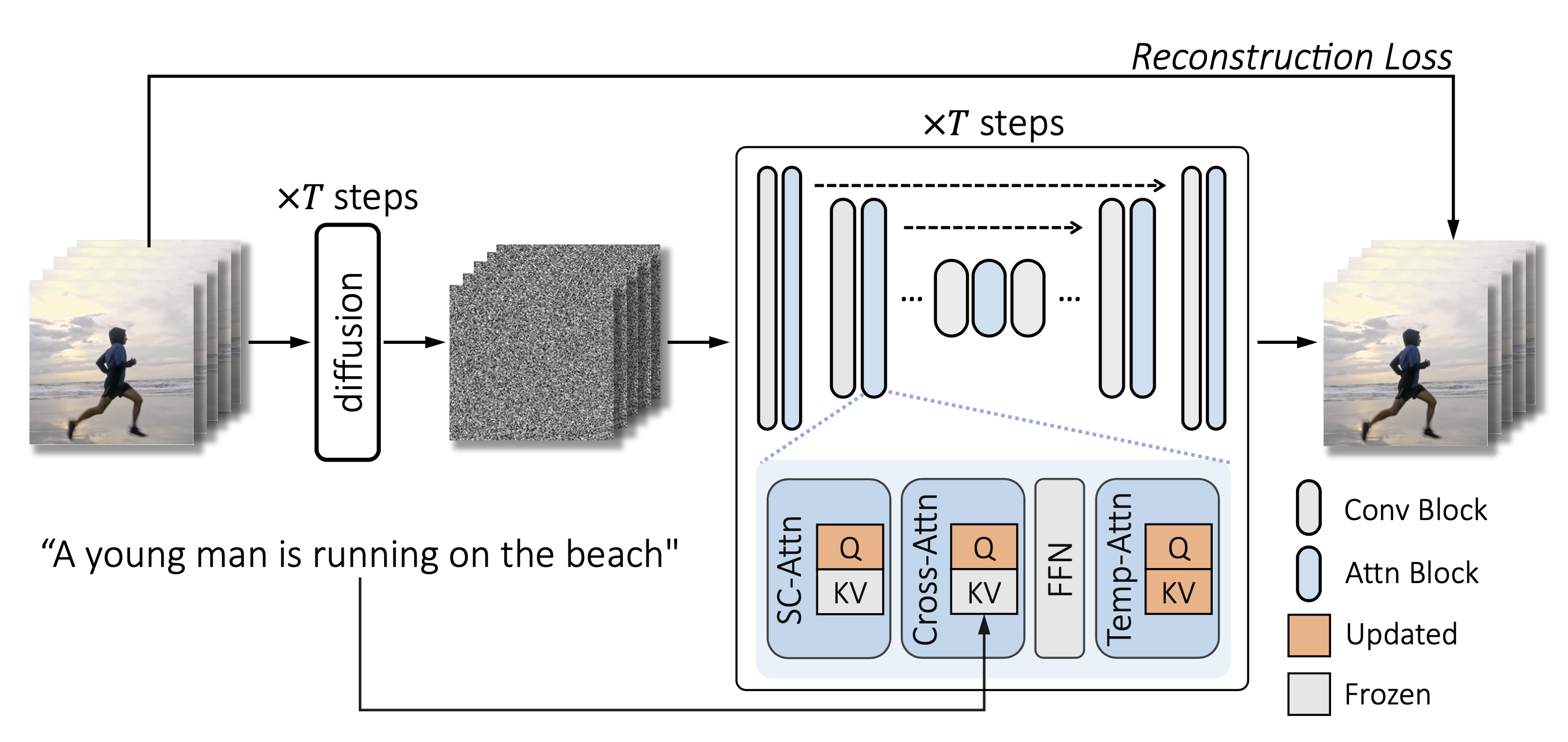
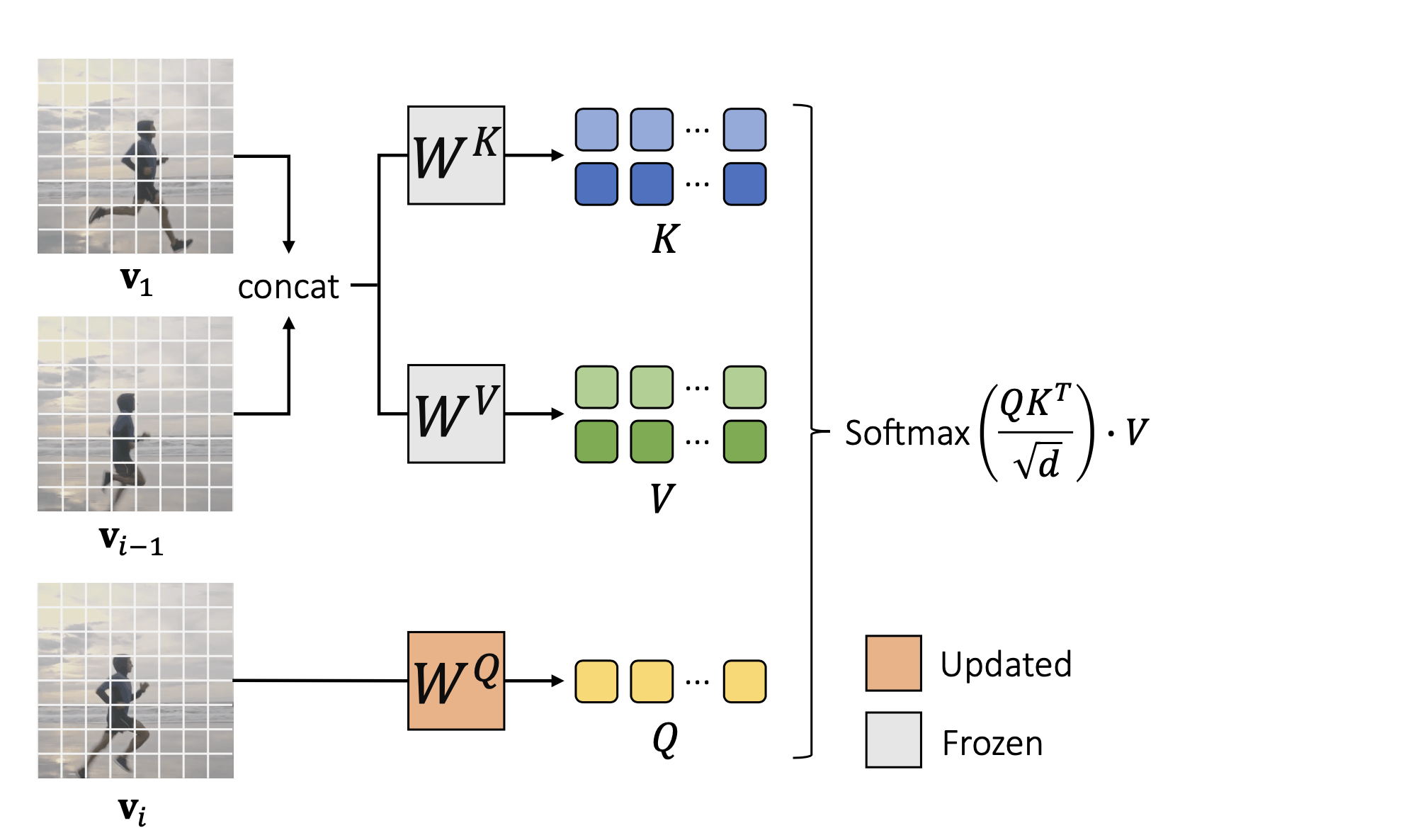
さらに、時空間のアテンションは計算が2次的に増加するため、SC-Attn(Sparse-Causal Attention)は下記のように、動画の最初のフレームと直前のフレームのみを参照する形にしています。

3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Open in Colab」ボタンをクリックすると動かせます。
*但し、今回のモデルはGPUメモリを多く消費するため無料のColabでは動かせず、colab pro(約1,000円/月)のプレミアムGPU設定で「A100」をゲットしないと動かせないので、ご注意下さい。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#@title **Setup** # check GPU ! nvidia-smi -L # change torch version ! pip install torch==1.13.0 torchvision==0.14.0 # install xformers ! pip install -q https://github.com/brian6091/xformers-wheels/releases/download/0.0.15.dev0%2B4c06c79/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl # copy github code & install library ! git clone https://github.com/cedro3/Tune-A-Video.git %cd Tune-A-Video ! pip install -r requirements.txt # download model ! mkdir checkpoints %cd checkpoints !git lfs install !git clone https://huggingface.co/CompVis/stable-diffusion-v1-4 %cd .. |
それでは、configs/*.yamlの設定に基づいて、動画と文のセットでファインチューニングを行い、色々な文から動画を生成するモデルを作成してみましょう。ここでは、configs/man-surfing.yamlを使用し、まず「男性がサーフィンをしている動画と文(”a man is surfing”)のセット」でファインチューニングします。動画(data/man-surfing)は、これです。


そのあと、”a panda is surfing”, “a boy, wearing a birthday hat, is surfing”, “a raccoon is surfing, cartoon style”, “Iron Man is surfing in the desert”の4種類の文から動画を生成するモデルを作成します。
|
1 2 |
#@title **Train** ! accelerate launch train_tuneavideo.py --config="configs/man-surfing.yaml" |
作成したモデルを元にGIF動画を作成します。outputs/man-surfing_lr3e-5_seed33の下に作成されているフォルダ名(毎回変わります)をid_nameに記入し、作成したい動画のモデルをpromptで選択します。ここでは、promptは“a panda is surfing”を選択しています。なお、同じモデルでも生成する動画は毎回変わります。ちなみに、GPUに「A100」を使用していないと、ここでCuda Out of memory のエラーが発生します。
*あらかじめ記入されているid_nameはダミーです。必ず、ご自分のColabで作成したものに変更して下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#@title **Make GIF** from tuneavideo.pipelines.pipeline_tuneavideo import TuneAVideoPipeline from tuneavideo.models.unet import UNet3DConditionModel from tuneavideo.util import save_videos_grid import torch id_name = "2023-01-31T12-15-52" #@param {type:"string"} model_id = "./outputs/man-surfing_lr3e-5_seed33/" + id_name unet = UNet3DConditionModel.from_pretrained(model_id, subfolder='unet', torch_dtype=torch.float16).to('cuda') pipe = TuneAVideoPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", unet=unet, torch_dtype=torch.float16).to("cuda") prompt = "a panda is surfing" #@param ["a panda is surfing", "a boy, wearing a birthday hat, is surfing", "a raccoon is surfing, cartoon style", "Iron Man is surfing in the desert"] video = pipe(prompt, video_length=8, height=512, width=512, num_inference_steps=50, guidance_scale=7.5).videos # save video save_videos_grid(video, "outputs/video.gif") |
作成したGIF動画を再生します。
|
1 2 3 |
#@title **Play GIF** from IPython.display import Image Image("outputs/video.gif", format='png') |


被写体が男性からパンダに変わっていますね。作成したGIF動画をダウンロードします。
|
1 2 3 |
#@title **Download GIF** ( for chrome only) from google.colab import files files.download("outputs/video.gif") |
もう1つ “Iron Man is surfing in the desert” でやってみましょう。

今度は、被写体が男性からアイロンマンに、背景が海から砂漠に変わっていますね。文から動画を生成する取り組み、今後が楽しみです。では、また。
(オリジナルgithub)https://github.com/showlab/Tune-A-Video