
今回は、CelebAデータセットから、属性ファイルを使って、好みのデータセットを抽出してみます。
こんにちは cedro です。
皆さん、CelebA データセットは、ご存じですか。

このブログでも過去2回登場していますが、CelebaA データセットは有名人の顔画像をカラー178×218ピクセルで202,599枚集めたデータセットです。
機械学習はデータ数が多いに越したことなく、20万枚越えのデータ数量は天下無敵と言っても良いでしょう。しかしながら、CelebA はデータが1つのフォルダーにまとめて格納されているので用途は限られ、せいぜいGANやVAEにしか使えませんでした。
手作業で分類できないわけではないですが、さすがに1万枚以上になると無理です。根気が続きません。
実は、CelebaA には属性ファイルが付属していて、これを活用すれば自分の好みデータセットを抽出できそうなことは分かっていたのですが、なんとなく敷居が高く、そのままになっていました。
しかし、実際にトライしてみると、意外に簡単だったので、ブログにします。
というわけで、今回は、CelebA データセットから、属性ファイルを使って、好みのデータセットを抽出してみます。
CelebAの属性とは
CelebaA には、各画像データが40種類の属性について、該当するかどうかをまとめた属性ファイル( list_attr_celeba.txt )が付属しています。
まず、その40種類の属性名を、具体的な画像例と共に見て行きます。属性名の横にある2枚の画像の内、左がその属性がYESの例、右がその属性がNOの例です。また、属性名の下にある数字は 202,599枚の内、何枚がこの属性に該当しているかを示しています。

最初、1) 5_o_Clock_Shadow が全く分からなかったのですが、どうも「髭の剃り残しがある」という意味みたいです。昔シェーバーのCMでありましたが、午後5時の影を消せというノリですね。
2) Arched_Eyebrows は「三日月眉」。3) Attractive つまり「魅力的」という属性があるんですが、これに該当していない人はかわいそうですね。4) Bags_Under_Eyes は「目の下のたるみ」。
5) Bald はスキンヘッド。6) Bangsは、「前髪」という意味ですが、これはちょっと分かりませんでした。7) は「大きな唇」、8) は「大きな鼻」。

9),10),12) は髪の毛の色で、「黒髪」、「金髪」、「茶髪」。11) Blurry は「ぼやけた」画像。13) Bushy_ Eyebrows は「ゲジゲジ眉毛」。
14) chubby は「ぽっちゃり」、15) Double_Chin は「2重あご」、16) は「メガネ」。

17) Goatee は下あごに生やす「やぎひげ」。18) は「白髪」、19) は「厚化粧」。20) High_Cheekbones は「高い頬骨」で、外国ではこれが美人の条件の1つとして挙げられているようです。
21) はズバリ「男」、なのでこの属性がNOなら「女」です。22) Mouth_Slightly_Open は「口が少し開いている」、23) Mustache は「口ひげ」、24) は「細目」。

25) No_Bead は「ひげが無い」、26) Oval_Face は「うりざね顔」、27) Pale_Skin は「顔色が悪い」、28) Pointy_Nose は「とがった鼻」。
29) Receding_Hairline は「額がはげ上がった」、30) Rosy_Cheeks は「紅顔」、31) Sideburns は「頬ひげ」。そして、32) は「笑顔」。

33),34) は髪型で、「ストレート」か「カール」か。この後は、着けているものが、並びます。
35) は「イアリング」、36) は「帽子」、37) は「口紅」、38) は「ネックレス」、39) は「ネクタイ」。そして最後の 40) が「若さ」。
20万枚を超える画像に対して、40の属性について1枚づつチェックするには、相当な労力が掛かった思います。本当に感謝です。
この属性ファイルを上手く使うことによって、CelebA データセットから、色々なデータセットを抽出できることが分かると思います。
この後、データセットの入手から抽出までをやってみたいと思います。
CelebAデータセットを入手する
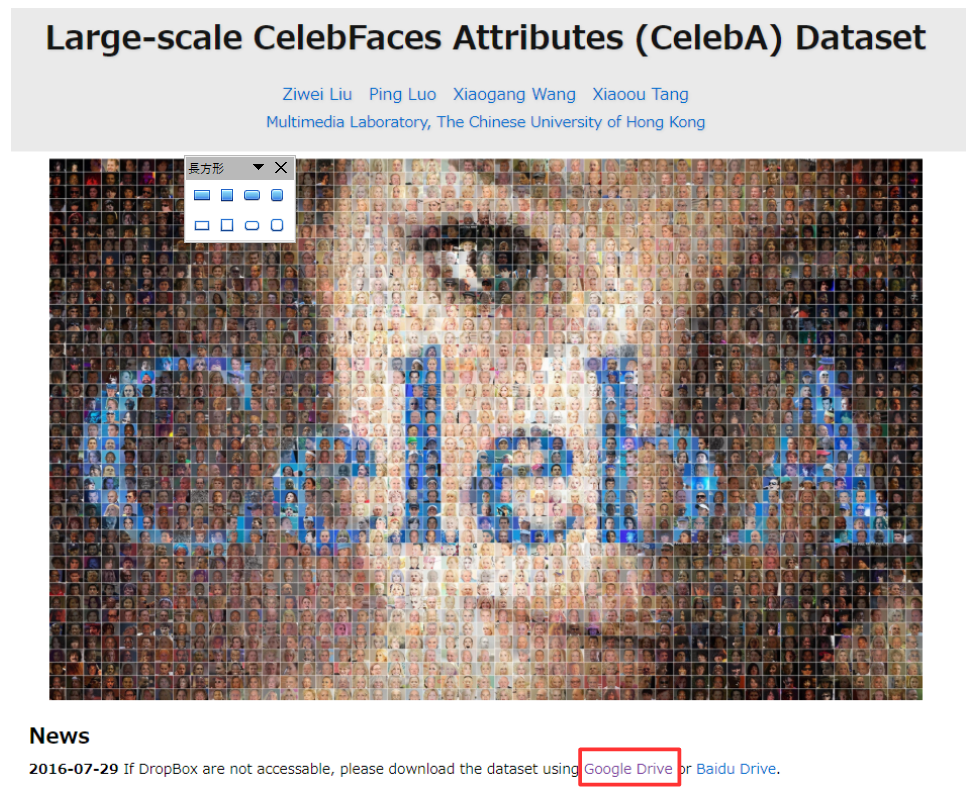
まず、このリンクから celebA のデータセットを入手します。
赤枠の「Google Drive」をクリックし、Img > img_align_celeba_png.7z にある、16個のファイルを適当なフォルダーに全てダウンロードします。
1つが700MBくらいありますので、結構時間がかかります。
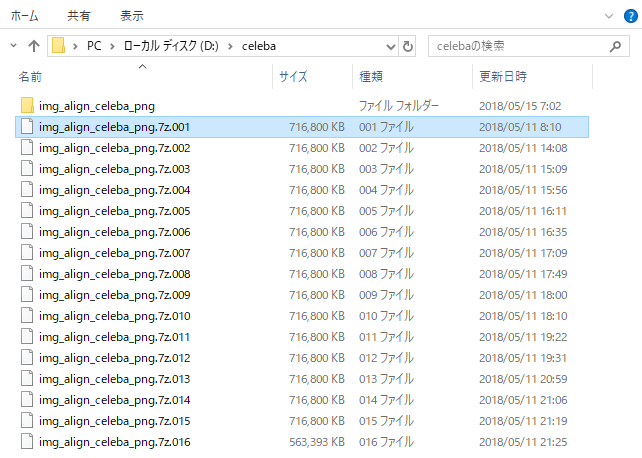
ダウンロードしたファイルを解凍すると、img_align_celeba_png というデータフォルダーが出来ます(容量は11.2GBです)。なお、この7z という形式を解凍できるアプリをお持ちでない場合は、7zip がお勧めです。
次に、同じく「Google Drive」にある属性ファイル Anno > list_attr_celeba.txt をダウンロードします。
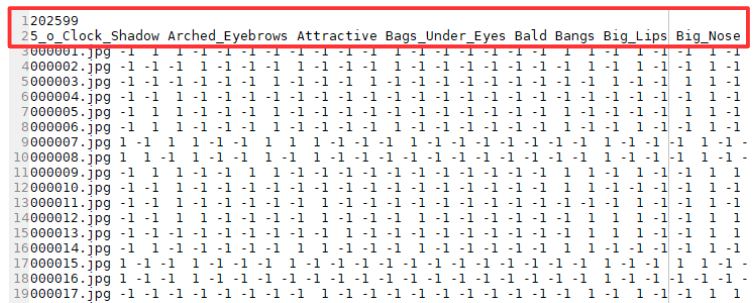
list_attr_celeba.txt のファイルの中身は、こんな形。1行目にデータ総数 202,599 、2行目に40個の属性名、3行目以降に各画像データがどの属性に該当しているかが書いてあり、データの区切りはスペースです。
3行目以降、属性に該当している場合は「1」、該当していない場合は「-1」が表示されています。
この後のプログラムで扱い易いように、赤枠で囲まれている1行目と2行目は削除します。
また、理由は分かりませんが、ダウンロードして解凍した画像が「png」なのに、属性ファイルの記載が「jpg」なので、エディタの文字置換機能等を使って、属性ファイルの方を「jpg →「png」に 全て変更しておきます。
好みのデータセットを抽出する
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from PIL import Image ### 画像処理ライブラリPillow をインポート count = 0 with open("list_attr_celeba.txt","r") as f: ### 属性ファイルを開く for i in range(202599): ### 全部で202,599枚処理する line = f.readline() ### 1行データ読み込み line = line.split() ### データを分割 count = count+1 print(count) ### 何枚目を処理しているかスクリーン表示 if line[3]=="1" and line[16]=="-1" and line[21]=="1" and line[32]=="1" and line[36]=="-1" and line[40]=="1": ### 魅力的で、メガネ無しで、男性で、笑顔で、帽子無しで、若い image = Image.open("d:/celeba/img_align_celeba_png/"+line[0]) ### 該当画像読み込み image.save("./0/"+line[0]) ### 「0」フォルダーに保存 elif line[3]=="1" and line[16]=="-1" and line[21]=="1" and line[32]=="-1" and line[36]=="-1" and line[40]=="1": image = Image.open("d:/celeba/img_align_celeba_png/"+line[0]) image.save("./1/"+line[0]) elif line[3]=="1" and line[16]=="-1" and line[21]=="-1" and line[32]=="1" and line[36]=="-1" and line[40]=="1": image = Image.open("d:/celeba/img_align_celeba_png/"+line[0]) image.save("./2/"+line[0]) elif line[3]=="1" and line[16]=="-1" and line[21]=="-1" and line[32]=="-1" and line[36]=="-1" and line[40]=="1": image = Image.open("d:/celeba/img_align_celeba_png/"+line[0]) image.save("./3/"+line[0]) |
取り上げている属性は、「3) 魅力的」、「16) メガネ」、「21) 男性」、「32) 笑顔」、「36) 帽子」、「40) 若さ」の6種類です。
「21) 男性」と「32) 笑顔」の組み合わせで、「笑っている男性」、「笑っていない男性」、「笑っている女性」、「笑っていない女性」の4種類のパターンを作り、残りの属性は固定です。
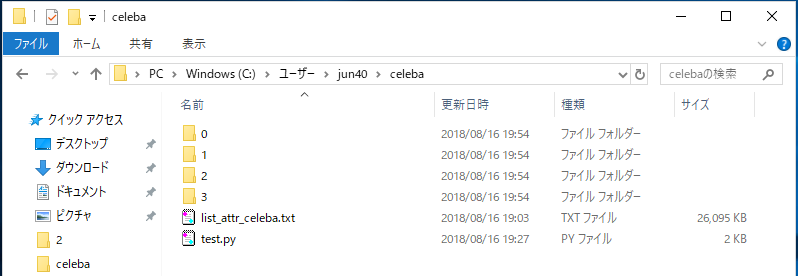
先ほど作成したプログラムをtest.py で保存します。そして、「0」、「1」、「2」、「3」の空のフォルダーを作成します。なお、私の環境では、CelebA の画像ファイルは、d:/celeba/img_align_celeba_png フォルダーに置いてあります。
|
1 2 3 |
python test.py |
プログラムが格納されているディレクトリに移動し、上記コマンドでプログラムが起動します。
さて、結果はどうでしょうか。

フォルダー「0」の「笑っている男性」です。画像数は、9,653枚。

フォルダー「1」の「笑っていない男性」です。画像数は、10,393枚。

フォルダー「2」の「笑っている女性」です。画像数は、41,607枚。

フォルダー「3」の「笑っていない女性」です。画像数は、32,249枚。
こんな感じで、属性ファイルを活用すると、20万枚にも及ぶ CelebA から自分の好きなデータセットが抽出できます。
しばらく、色々とデータセットを抽出して、遊んでみようと思います。
では、また。
P.S.
今更ながらCelebAのAは何なのかと思って、ホームページをよく見ると、CelebFaces Attributes (CelebA) Dataset と書いてありました。AはAttributesの略で、属性ファイルとセットで使うことが前提のデータセットなのね、ということにやっと気づきました。













コメントを残す