Animate Anyoneで、1枚の画像から動画を生成する
1.はじめに 今回ご紹介するのは、昨年11月にアリババが発表した、1枚の画像から動画を生成する「Animat…
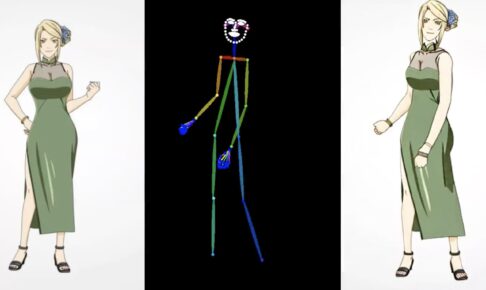 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、昨年11月にアリババが発表した、1枚の画像から動画を生成する「Animat…
 AI(人工知能)
AI(人工知能)
1.はじめに 2023.11.21に Stability AIは、静止画から動画を生成するImage2Vid…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、現在の画像生成の主流である拡散モデルでモーフィングを行うためのDiffMo…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、実写動画をアニメ化するAIサブスクリプション・サービス「Domo AI」で…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、音楽を自動生成するSuno AIというWebサービスです。これは、生成する…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、1枚の画像とモーションシークエンスから動画を生成する、MagicAnima…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、たった1枚の顔画像で、動画の顔を入れ替える事が出来るfacefusionと…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、文から動画を生成するモデル(txt2mov)の最新技術AnimateDif…
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、特殊なポーズでも3Dモデル推定が可能な4D-Humansという技術です。 …
 AI(人工知能)
AI(人工知能)
1.はじめに 今回ご紹介するのは、動画の人物を3Dモデルに置き換えることが出来る「Wonder Studio…
最近のコメント