

1.はじめに
StyleGANの画像編集には画像の潜在空間への反転が必要ですが、画像の正確な表現と潜在変数の編集のし易さはトレードオフの関係にあります。今回ご紹介するのは、このトレードオフの改善を高速処理で実現するHyperstyleという技術です。
*この論文は、2021.11に提出されました。
2.Hyperstyleとは?
StyleGANで画像編集を行う場合、まず画像を潜在空間へ反転することが必要で、このための手法は数多く提案されています。しかしながら、このときの画像の正確な表現と潜在変数の編集のし易さはトレードオフの関係にあります。
最近、このトレードオフを軽減するためにジェネレータを微調整する方法が提案されていますが、新しい画像毎に長いトレーニングが必要です。Hyperstyleは、このジェネレータを微調整するアプローチを高速に行うモデルです。
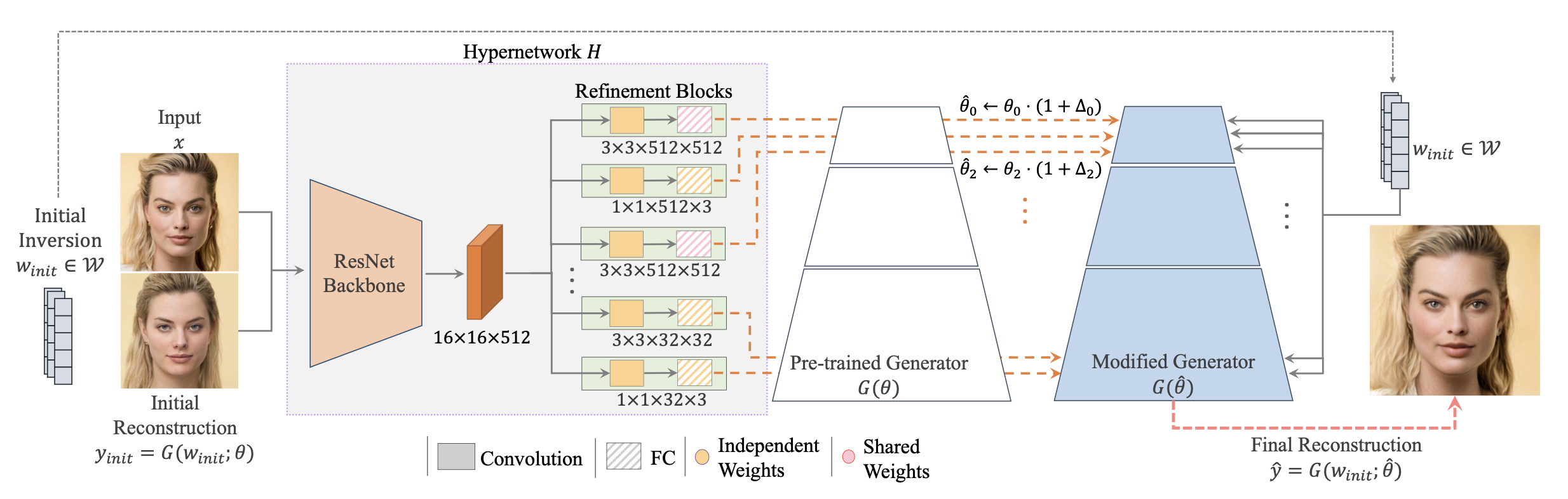
下記はHyperstyleのフローです。ポイントは、ジェネレータのパラメータ全体のトレーニングを行うのではなく、パラメータを絞り込んでエンコーダで調整します。
目的の画像(Input)と近似潜在変数(Initial reconstruction)から求めた画像を、エンコーダ(Hypernetwork H)に入力します。エンコーダでは、Resnetを通して特徴マップに展開し、学習済みジェネレータ(Pre-trained Generator)との差分を計算して、ジェネレータ(modified Generator)に適用します。

3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 |
#@title セットアップ import os os.chdir('/content') CODE_DIR = 'hyperstyle' # clone repo !git clone https://github.com/cedro3/hyperstyle.git $CODE_DIR # install ninja !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/ !sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force os.chdir(f'./{CODE_DIR}') # Import Packages import time import sys import pprint from tqdm import tqdm import numpy as np from PIL import Image import torch import torchvision.transforms as transforms import imageio from IPython.display import HTML from base64 import b64encode sys.path.append(".") sys.path.append("..") from notebooks.notebook_utils import Downloader, HYPERSTYLE_PATHS, W_ENCODERS_PATHS, run_alignment from utils.common import tensor2im from utils.inference_utils import run_inversion from utils.domain_adaptation_utils import run_domain_adaptation from utils.model_utils import load_model, load_generator from function import * %load_ext autoreload %autoreload 2 # download pretrained_models ! pip install --upgrade gdown import gdown gdown.download('https://drive.google.com/uc?id=1NxGZfkE3THgEfPHbUoLPjCKfpWTo08V1', 'pretrained_models.zip', quiet=False) ! unzip pretrained_models.zip # set expeiment data EXPERIMENT_DATA_ARGS = { "faces": { "model_path": "./pretrained_models/hyperstyle_ffhq.pt", "w_encoder_path": "./pretrained_models/faces_w_encoder.pt", "image_path": "./notebooks/images/face_image.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "cars": { "model_path": "./pretrained_models/hyperstyle_cars.pt", "w_encoder_path": "./pretrained_models/cars_w_encoder.pt", "image_path": "./notebooks/images/car_image.jpg", "transform": transforms.Compose([ transforms.Resize((192, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) }, "afhq_wild": { "model_path": "./pretrained_models/hyperstyle_afhq_wild.pt", "w_encoder_path": "./pretrained_models/afhq_wild_w_encoder.pt", "image_path": "./notebooks/images/afhq_wild_image.jpg", "transform": transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) } } experiment_type = 'faces' EXPERIMENT_ARGS = EXPERIMENT_DATA_ARGS[experiment_type] # Load HyperStyle Model model_path = EXPERIMENT_ARGS['model_path'] net, opts = load_model(model_path, update_opts={"w_encoder_checkpoint_path": EXPERIMENT_ARGS['w_encoder_path']}) print('Model successfully loaded!') # difine function def generate_mp4(out_name, images, kwargs): writer = imageio.get_writer(out_name + '.mp4', **kwargs) for image in tqdm(images): writer.append_data(image) writer.close() def get_latent_and_weight_deltas(inputs, net, opts): opts.resize_outputs = False opts.n_iters_per_batch = 5 with torch.no_grad(): _, latent, weights_deltas, _ = run_inversion(inputs.to("cuda").float(), net, opts) weights_deltas = [w[0] if w is not None else None for w in weights_deltas] return latent, weights_deltas def get_result_from_vecs(vectors_a, vectors_b, weights_deltas_a, weights_deltas_b, alpha): results = [] for i in range(len(vectors_a)): with torch.no_grad(): cur_vec = vectors_b[i] * alpha + vectors_a[i] * (1 - alpha) cur_weight_deltas = interpolate_weight_deltas(weights_deltas_a, weights_deltas_b, alpha) res = net.decoder([cur_vec], weights_deltas=cur_weight_deltas, randomize_noise=False, input_is_latent=True)[0] results.append(res[0]) return results def interpolate_weight_deltas(weights_deltas_a, weights_deltas_b, alpha): cur_weight_deltas = [] for weight_idx, w in enumerate(weights_deltas_a): if w is not None: delta = weights_deltas_b[weight_idx] * alpha + weights_deltas_a[weight_idx] * (1 - alpha) else: delta = None cur_weight_deltas.append(delta) return cur_weight_deltas def show_mp4(filename, width): mp4 = open(filename + '.mp4', 'rb').read() data_url = "data:video/mp4;base64," + b64encode(mp4).decode() display(HTML(""" <video width="%d" controls autoplay loop> <source src="%s" type="video/mp4"> </video> """ % (width, data_url))) |
サンプル画像を見てみましょう。自分の画像を使用したい場合は、./images/picに画像をアップロードしてください。
|
1 2 |
#@title サンプル画像表示 display_pic('./images/pic') |


サンプル画像にalign処理(目、鼻、口、顎などを処置の位置に合わせて切り出す)を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#@title align処理 import glob from tqdm import tqdm reset_folder('./images/align') files = sorted(glob.glob('./images/pic/*.jpg')) for file in tqdm(files): aligned_image = run_alignment(file) name = os.path.basename(file) aligned_image.save('./images/align/'+name) display_pic('./images/align') |


それでは、hyperstyleを使って反転処理(実写と同じ画像を出力する潜在変数を求める)を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
#@title 反転の実行 import glob image_paths = sorted(glob.glob('./images/align/*.jpg')) in_images = [] all_vecs = [] all_weights_deltas = [] img_transforms = EXPERIMENT_ARGS['transform'] if experiment_type == "cars": resize_amount = (512, 384) else: resize_amount = (opts.output_size, opts.output_size) for image_path in image_paths: #print(f'Working on {os.path.basename(image_path)}...') original_image = Image.open(image_path) original_image = original_image.convert("RGB") input_image = img_transforms(original_image) # get the weight deltas for each image result_vec, weights_deltas = get_latent_and_weight_deltas(input_image.unsqueeze(0), net, opts) all_vecs.append([result_vec]) all_weights_deltas.append(weights_deltas) in_images.append(original_image.resize(resize_amount)) n_transition = 25 if experiment_type == "cars": SIZE = 384 else: SIZE = opts.output_size images = [] image_paths.append(image_paths[0]) all_vecs.append(all_vecs[0]) all_weights_deltas.append(all_weights_deltas[0]) in_images.append(in_images[0]) for i in tqdm(range(1, len(image_paths))): if i == 0: alpha_vals = [0] * 10 + np.linspace(0, 1, n_transition).tolist() + [1] * 5 else: alpha_vals = [0] * 5 + np.linspace(0, 1, n_transition).tolist() + [1] * 5 for alpha in alpha_vals: image_a = np.array(in_images[i - 1]) image_b = np.array(in_images[i]) image_joint = np.zeros_like(image_a) up_to_row = int((SIZE - 1) * alpha) if up_to_row > 0: image_joint[:(up_to_row + 1), :, :] = image_b[((SIZE - 1) - up_to_row):, :, :] if up_to_row < (SIZE - 1): image_joint[up_to_row:, :, :] = image_a[:(SIZE - up_to_row), :, :] result_image = get_result_from_vecs(all_vecs[i - 1], all_vecs[i], all_weights_deltas[i - 1], all_weights_deltas[i], alpha)[0] if experiment_type == "cars": result_image = result_image[:, 64:448, :] output_im = tensor2im(result_image) res = np.concatenate([image_joint, np.array(output_im)], axis=1) images.append(res) |
それでは、求めた潜在変数を使用してモーフィングする動画を作成してみましょう。
|
1 2 3 4 5 6 7 8 |
#@title 動画の作成 kwargs = {'fps': 15} save_path = "./notebooks/animations" os.makedirs(save_path, exist_ok=True) gif_path = os.path.join(save_path, f"{experiment_type}_gif") generate_mp4(gif_path, images, kwargs) show_mp4(gif_path, width=opts.output_size) |


左が実写、右が求めた潜在変数から生成した画像です。ガッキーは経験上反転が難しいキャラクターなのですが、これを見ると中々精度が高いです。
では、また。
(オリジナルgithub : https://github.com/yuval-alaluf/hyperstyle)
2022.3.21 年齢シミュレーションcolab追加
年齢による顔の変化をシミュレーションするcolabを追加しました。https://github.com/cedro3/hyperstyle/blob/main/hyperstyle_edit.ipynb
(twitter投稿)