

今回は、畳み込み変分オートエンコーダでセレブの顔画像を2次元マップにマッピングしてみます。
こんにちは cedro です。
最近、多様な画像を2次元マップに綺麗な分布で落とし込んでくれる変分オートエンコーダにはまってます。
先々回はMNISTで、先回はオリジナルデータセット(モノクロ28×28の顔画像)でやってみましたが、せっかくならセレブの顔画像でもやってみたくなりました。
Keras のサンプルプログラムには、精度の高い畳み込み変分オートエンコーダがありますので、今回はこれを改造して使ってみたいと思います。
というわけで、今回は、畳み込み変分オートエンコーダでセレブの顔画像を2次元マップにマッピングしてみます。
データセットを準備する
データセットは、6/21のブログ「NNabla PGGAN セレブの顔画像を生成する」でダウンロードした CelebAを利用します。

約20万枚あるCelebAデータセットの内7万枚分を、OpenCVで顔部分を切り抜き、カラー64×64にリサイズします。

サンプルプログラムを格納したフォルフダーに face フォルダーを作り、その下に0フォルダーを作り、7万枚の画像データは全てこの0フォルダーに格納します。
本当は、データセットの属性リスト(性別、髪色、目色など)に従ってラベル分けしておくと、属性毎のドット分布も見ることが出来るんですが、面倒なので今回は省きます。
VAEは、教師なし学習で、ラベルを見ずに分布を作るため、画像を2次元マップにマッピングするだけなら、ラベル分けは不要です。
プログラムを改造します
keras のサンプルプログラム(variational_autoencoder_deconv.py)を改造します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from __future__ import absolute_import from __future__ import division from __future__ import print_function from keras.layers import Dense, Input from keras.layers import Conv2D, Flatten, Lambda from keras.layers import Reshape, Conv2DTranspose from keras.models import Model from keras.datasets import mnist from keras.losses import mse, binary_crossentropy from keras.utils import plot_model, np_utils ### 追加 from keras import backend as K from keras.preprocessing.image import array_to_img, img_to_array, list_pictures, load_img ### 追加 from sklearn.model_selection import train_test_split ### 追加 |
新たに必要なパッケージを追加でインポートします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(x_test, batch_size=batch_size) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1]) ### c=y_testを削除 #plt.colorbar() ### clorbar を使用しない plt.xlabel("z[0]") plt.ylabel("z[1]") plt.savefig(filename) #plt.show() ### 表示させない |
2次元マップにドットで分布を表示する部分です。データは1種類だけなので、c=y_test は削除し、colorbar は表示させません。また、filenameもあえてディスプレイに表示させません(一端表示すると、表示中止ボタンを押すまで動作が中断して、使い勝手が悪いので)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# display a 30x30 2D manifold of digits n = 15 ### 30 → 15に変更 digit_size = 64 ### 28 → 64 に変更 figure = np.zeros((digit_size * n, digit_size * n, 3)) ### 3 を追加 # linearly spaced coordinates corresponding to the 2D plot # of digit classes in the latent space grid_x = np.linspace(-4, 4, n) grid_y = np.linspace(-4, 4, n)[::-1] for i, yi in enumerate(grid_y): for j, xi in enumerate(grid_x): z_sample = np.array([[xi, yi]]) x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size, 3) ### 3 を追加 plt.imshow(digit,cmap='Greys_r') ### 追加 plt.savefig(str(i)+'@'+str(j)+'fig.png') ### 追加 figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit |
2次元マップに画像をマッピングする部分です。マップが30×30では顔画像が小さくなって見難くなるので、15×15に変更しています。そして、モノクロ28×28→カラー64×64への変更に伴う修正をしています。
また、出力画像は後でGIF動画を作成するために、1枚づつ 0@0fig.png 〜 14@14fig.png まで225枚分(15×15=225)を保存する設定にしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# MNIST dataset #(x_train, y_train), (x_test, y_test) = mnist.load_data() #image_size = x_train.shape[1] #x_train = np.reshape(x_train, [-1, image_size, image_size, 1]) #x_test = np.reshape(x_test, [-1, image_size, image_size, 1]) #x_train = x_train.astype('float32') / 255 #x_test = x_test.astype('float32') / 255 ### face daterset x = [] y = [] for picture in list_pictures('./face/0'): img = img_to_array(load_img(picture, target_size=(64,64))) x.append(img) y.append(0) x = np.asarray(x) y = np.asarray(y) x = x.astype('float32') x = x/ 255.0 y = np_utils.to_categorical(y, 1) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) original_dim = 12288 image_size = 64 |
データセットの読み込み部分です。MNISTの読み込み部分は、無効にします(削除でもOK)。
list_picture, load_img, img_to_arry を使ってデータを読み込んで必要な処理をした後に、train_test_split で学習用80%・評価用20%に分割しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# network parameters input_shape = (image_size,image_size,3) ### 1 → 3 に変更 batch_size = 128 kernel_size = 3 filters = 32 ### 16 → 32 に変更 latent_dim = 2 epochs = 50 # VAE model = encoder + decoder # build encoder model inputs = Input(shape=input_shape, name='encoder_input') x = inputs for i in range(3): ### 2 → 3 に変更 filters *= 2 x = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu', strides=2, padding='same')(x) # shape info needed to build decoder model shape = K.int_shape(x) # generate latent vector Q(z|X) x = Flatten()(x) x = Dense(16, activation='relu')(x) z_mean = Dense(latent_dim, name='z_mean')(x) z_log_var = Dense(latent_dim, name='z_log_var')(x) # use reparameterization trick to push the sampling out as input # note that "output_shape" isn't necessary with the TensorFlow backend z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var]) # instantiate encoder model encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder') encoder.summary() #plot_model(encoder, to_file='vae_cnn_encoder.png', show_shapes=True) ### # build decoder model latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) for i in range(3): ### 2 → 3 に変更 x = Conv2DTranspose(filters=filters, kernel_size=kernel_size, activation='relu', strides=2, padding='same')(x) filters //= 2 outputs = Conv2DTranspose(filters=3, ### 1 → 3 に変更 kernel_size=kernel_size, activation='sigmoid', padding='same', name='decoder_output')(x) |
ネットワークを構築する部分です。モノクロ28×28 → カラー64×64 の変更に伴う修正をしています。
そして、2箇所ある、for i in rage (2) → for i in range (3) に変更することで、エンコーダとデコーダの畳み込みレイヤーを2段から3段にパワーアップさせ、これに伴い fllters は16→32に変更しています。

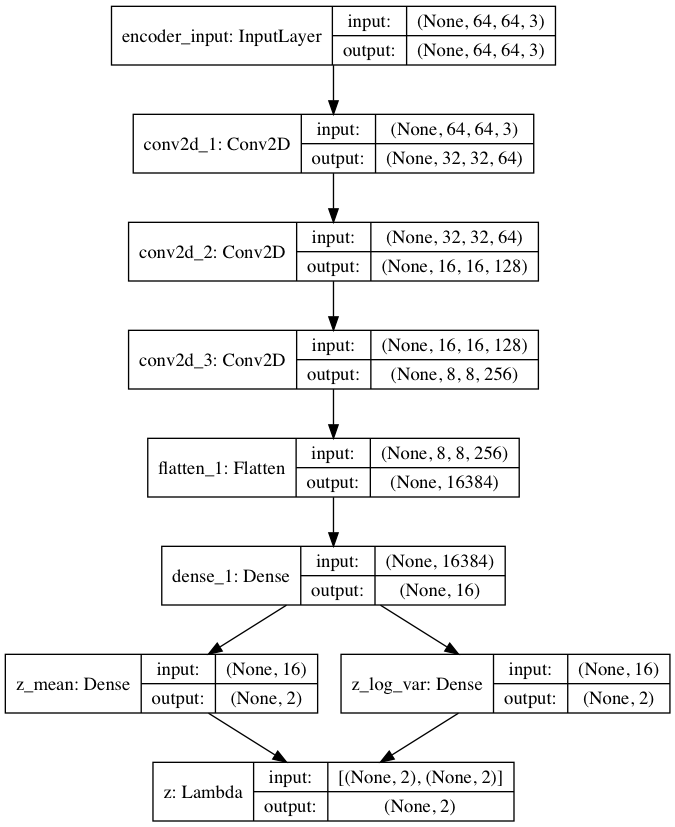
エンコーダーの構成図はこんな形(プログラムが出力する vae_cnn_encoder.png です)。畳み込みの部分は、カラー64×64の入力を32×32フィルター64枚で受けてから、8×8フィルター256枚まで次元圧縮(1/4 )しています。

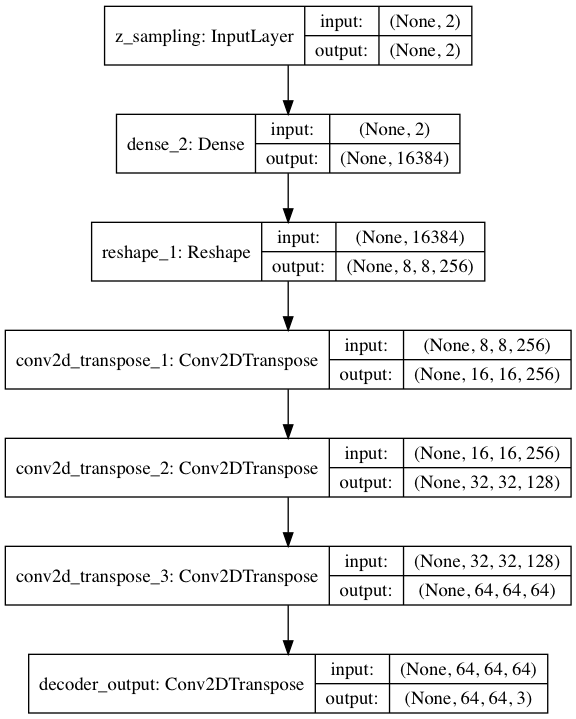
デコーダの構成図はこんな形(プログラムが出力する vae_cnn_decoder.png です)。畳み込み部分は、エンコーダの逆です。
プログラムを動かしてみます
|
1 2 3 |
python variational_autoencoder_deconv.py |
プログラムを格納したフォルダーで、上記コマンドを入力するとプログラムが起動します。学習時間は、GTX1060で1eopch 100sec 程度、50epoch で約80分でした。

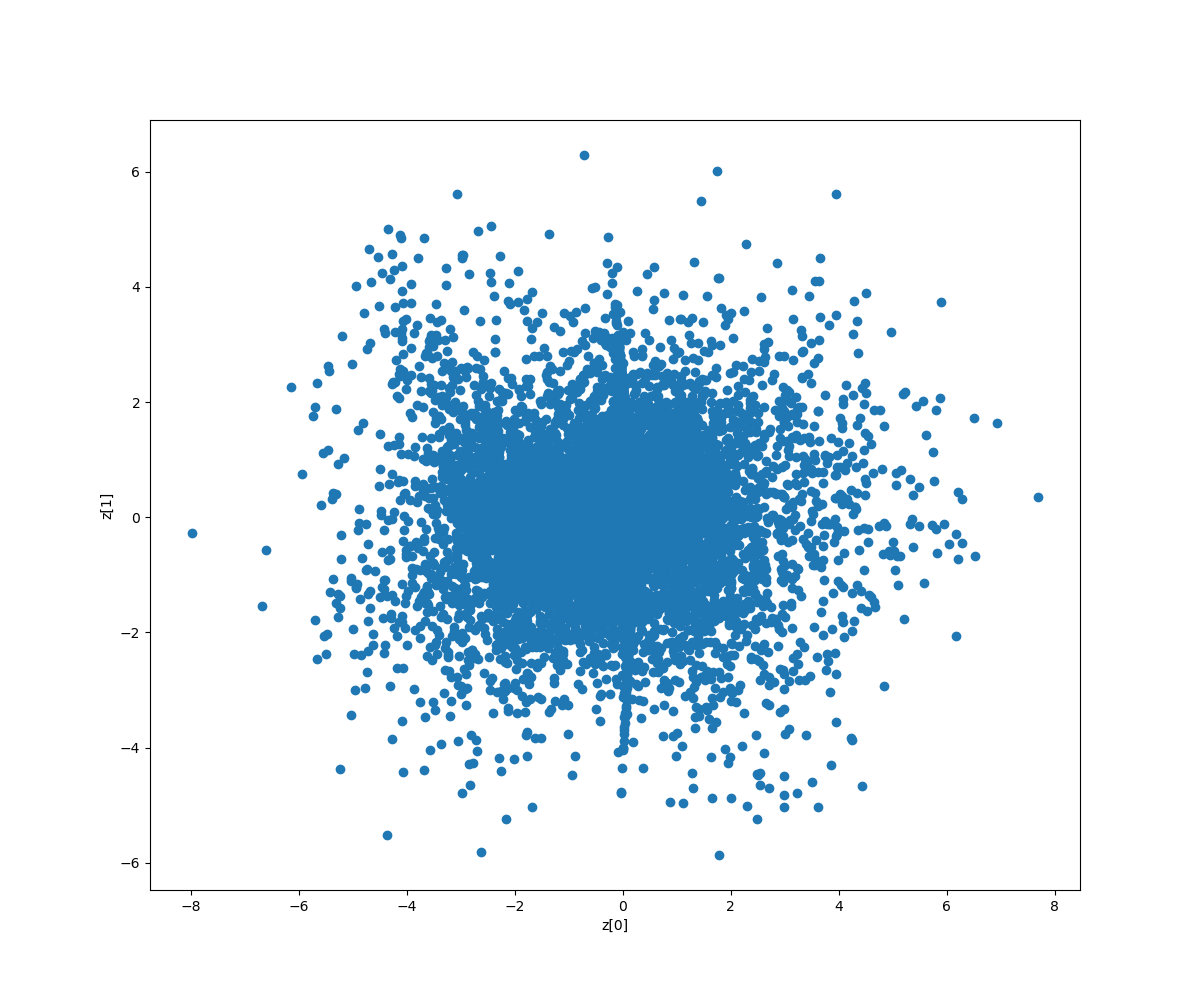
これは、2次元マップにドットで分布させたものです。データが1種類しかないので1色だけです。分布状態は、まずまずではないでしょうか。


これは、2次元マップに画像を分布させたものです。


それでは、2次元マップに分布した画像を青矢印に拾って、GIF動画にしてみましょう。


先回のGIF動画は、顔の向きだけが分かる程度でしたが、今回は性別や顔の作りも多少区別ができ、表現力が向上しています。
VAEのポテンシャルの高さを改めて感じます。
では、また。