
今回は、DCGANの学習済みモデルを使って、入力ベクトルを操作することで、生成する顔画像の「顔の向き」をコントロールしてみます。
こんにちは cedro です。
前編では、顔画像生成器と称して、DCGANの学習済みモデルを作成しました。
これで、いくらでも好きなだけ顔画像を生成することが可能になりました(笑)。
但し、顔画像は「右向き」、「左向き」、「正面」がランダムに生成されます。どうせなら、自分の指定した「顔の向き」のみを生成することは出来ないでしょうか。
そこで、今回の後編では、顔画像と入力ベクトルの関係を調べ、入力ベクトルを操作することによって、狙いの「顔の向き」だけ(例えば、右向きだけ)を画像生成できるようにコントロールしてみます。
顔画像と入力ベクトルの関係を調べます
前回作成した、顔画像生成器のプログラムを修正し、生成した顔画像の入力ベクトルを記録できるようにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
from __future__ import absolute_import from six.moves import range import numpy as np import nnabla as nn import nnabla.logger as logger import nnabla.functions as F import nnabla.parametric_functions as PF import nnabla.solvers as S import nnabla.utils.save as save from args import get_args import os def generator(z, maxh=1024, test=False, output_hidden=False): """ Building generator network which takes (B, Z, 1, 1) inputs and generates (B, 3, 64, 64) outputs. """ # Define shortcut functions def bn(x): # Batch normalization return PF.batch_normalization(x, batch_stat=not test) def upsample2(x, c): # Twise upsampling with deconvolution. return PF.deconvolution(x, c, kernel=(4, 4), pad=(1, 1), stride=(2, 2), with_bias=False) assert maxh / 16 > 0 #with nn.parameter_scope("gen"): # (Z, 1, 1) --> (1024, 4, 4) with nn.parameter_scope("deconv1"): d1 = F.elu(bn(PF.deconvolution(z, maxh, (4, 4), with_bias=False))) # (1024, 4, 4) --> (512, 8, 8) with nn.parameter_scope("deconv2"): d2 = F.elu(bn(upsample2(d1, maxh / 2))) # (512, 8, 8) --> (256, 16, 16) with nn.parameter_scope("deconv3"): d3 = F.elu(bn(upsample2(d2, maxh / 4))) # (256, 16, 16) --> (128, 32, 32) with nn.parameter_scope("deconv4"): d4 = F.elu(bn(upsample2(d3, maxh / 8))) # (128, 32, 32) --> (64, 64, 64) with nn.parameter_scope("deconv5"): d5 = F.elu(bn(upsample2(d4, maxh / 16))) # (64, 64, 64) --> (3, 64, 64) with nn.parameter_scope("conv6"): x = F.tanh(PF.convolution(d5, 3, (3, 3), pad=(1, 1))) return x # Fake path nn.clear_parameters() z = nn.Variable((1, 100, 1, 1)) ## 入力ベクトルは画像1枚分 fake = generator(z) y = fake # 学習済みパラメーターの読み込み nn.parameter.load_parameters(".\\generator_param_130000.h5") ## 重みパラメーターの読み込み # Create monitor. import nnabla.monitor as M monitor = M.Monitor("c:\\Users\\jun40\\dcgan_gen1") ## 生成画像の保存フォルダー指定(プログラムを格納したフォルダーと同じにして下さい) monitor_fake = M.MonitorImageTile( "Fake images", monitor, interval=1, num_images=1, normalize_method=lambda x: x + 1 / 2.) ## 生成画像は1枚づつ # CSV file write import csv ## CSVライブラリー読み込み write_fp=csv.writer(open("face.csv","w")) ## 書き込み用CSVファイル準備 # Training loop. for i in range(512): ## 生成する画像は512枚 z.d = np.random.randn(*z.shape) y.forward() monitor_fake.add(i, fake) vector=np.ravel(z.d) print(vector) ## 入力ベクトルをモニターに表示 write_fp.writerow(vector) ## 入力ベクトルをCSVファイルに書き込む |
生成する画像は全部で512枚。画像を1枚づつ生成し、生成する毎にその時の入力ベクトルをCSVファイル( face.csv )に書き込むようにしています。
重みパラメーターは、前回のブログから再度学習を進めて作成した、130,000ステップのものを使用しています。

これらのプログラムを適当なフォルダーに保存して、> python dcgan_gen1.py で実行します。
プログラムを実行すると、「Fake-image」フォルダーが作成され、この中に生成された顔画像が保存されます。そして、face.csv ファイルが作成され、その時の入力ベクトルが記録されます。

これが生成された顔画像で、全部で512枚あります。生成される画像が、「右向き」か「左向き」か「正面」になるかは、ランダムです。また、画像の質が低いものも中には生成されています。
この512枚の画像の中から、画像の質も考慮しながら、代表的な「右向き」、「左向き」の画像を25枚づつ選びます。

こんな感じで、右向き25枚を選びます。
こんな感じで、左向き25枚を選びます。
そして、それぞれ25枚の画像に該当する入力ベクトルをCSVファイル(face.csv)から拾って、次元毎に平均し、右向きのベクトルR、左向きのベクトルLを計算します。
入力ベクトルを操作して生成画像のカテゴリーをコントロールしてみます
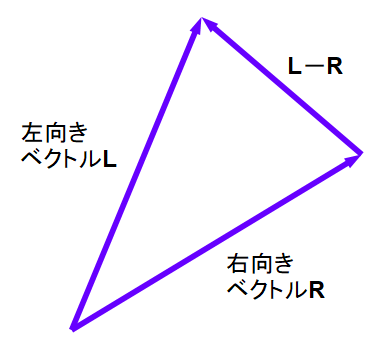
さて、かなり乱暴ですが、右向きベクトルRに、LーRを1/4づつ加えると、顔が右向きから徐々に左向きに変化するベクトルが出来るはずです。
①右向き :R
②やや右向き :R+(L-R)×1/4 = (3R+L)/4
③ほぼ正面 :R+(L-R)×2/4 = (2R+2L)/4
④やや左向き :R+(L-R)×3/4 = (R+3L)/4
⑤左向き :R+(LーR)×4/4 =L
①~⑤のベクトルを実際に計算してみます。計算結果は、数値のままだと分かり難いので、グラフ化(横軸が次元、縦軸が数値の面グラフ)します。
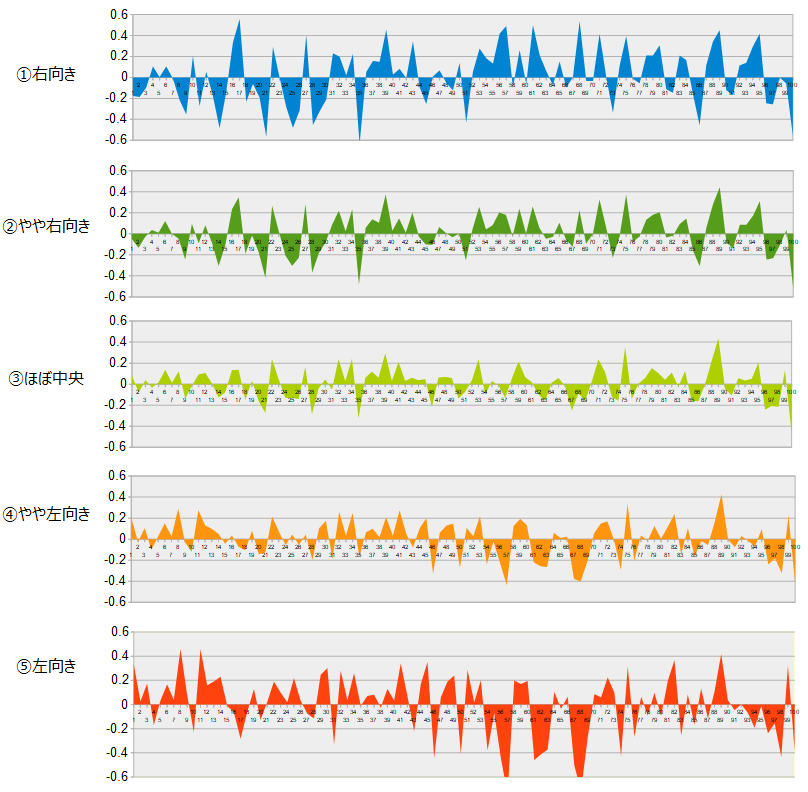
①右向きと⑤左向きは、対照的な波形のように見え、③ほぼ中央が一番おとなしい波形にみえますね。
それでは、画像発生器の入力に、①~⑤のベクトルをオフセットとして加えられるように、プログラムを修正します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
from __future__ import absolute_import from six.moves import range import numpy as np import nnabla as nn import nnabla.logger as logger import nnabla.functions as F import nnabla.parametric_functions as PF import nnabla.solvers as S import nnabla.utils.save as save from args import get_args import os def generator(z, maxh=1024, test=False, output_hidden=False): """ Building generator network which takes (B, Z, 1, 1) inputs and generates (B, 3, 64, 64) outputs. """ # Define shortcut functions def bn(x): # Batch normalization return PF.batch_normalization(x, batch_stat=not test) def upsample2(x, c): # Twise upsampling with deconvolution. return PF.deconvolution(x, c, kernel=(4, 4), pad=(1, 1), stride=(2, 2), with_bias=False) assert maxh / 16 > 0 #with nn.parameter_scope("gen"): # (Z, 1, 1) --> (1024, 4, 4) with nn.parameter_scope("deconv1"): d1 = F.elu(bn(PF.deconvolution(z, maxh, (4, 4), with_bias=False))) # (1024, 4, 4) --> (512, 8, 8) with nn.parameter_scope("deconv2"): d2 = F.elu(bn(upsample2(d1, maxh / 2))) # (512, 8, 8) --> (256, 16, 16) with nn.parameter_scope("deconv3"): d3 = F.elu(bn(upsample2(d2, maxh / 4))) # (256, 16, 16) --> (128, 32, 32) with nn.parameter_scope("deconv4"): d4 = F.elu(bn(upsample2(d3, maxh / 8))) # (128, 32, 32) --> (64, 64, 64) with nn.parameter_scope("deconv5"): d5 = F.elu(bn(upsample2(d4, maxh / 16))) # (64, 64, 64) --> (3, 64, 64) with nn.parameter_scope("conv6"): x = F.tanh(PF.convolution(d5, 3, (3, 3), pad=(1, 1))) return x # Fake path nn.clear_parameters() z = nn.Variable((1, 100, 1, 1)) fake = generator(z) y = fake # 学習済みパラメーターの読み込み nn.parameter.load_parameters(".\\generator_param_130000.h5") # Create monitor. import nnabla.monitor as M monitor = M.Monitor("c:\\Users\\jun40\\dcgan_gen2") ## 生成画像の保存フォルダー指定(プログラムを格納したフォルダーと同じにして下さい) monitor_fake = M.MonitorImageTile( "Fake images", monitor, interval=1, num_images=1, normalize_method=lambda x: x + 1 / 2.) # CSV file write import csv write_fp=csv.writer(open("face.csv","w")) read_fp=csv.reader(open("offset.csv","r")) ### オフセット読み込みファイルを準備 for line in read_fp: ### 1行読み込み line=list(map(float,line)) ### 文字を数値に変換 offset=np.reshape(line,[100,1,1]) ### 100個の1×1画像に変換 # Training loop. for i in range(512): z.d = np.random.randn(*z.shape)+offset ### 入力にオフセットを加算 y.forward() monitor_fake.add(i, fake) vector=np.ravel(z.d) print(vector) write_fp.writerow(vector) |
オフセットに使うベクトルは、CSVファイル(offset.csv)の1行目に予め書き込んでおき、プログラムから読み込む形にしています。

これらのプログラムを適当なフォルダーに保存して、> python dcgan_gen2.py で実行します。

①~⑤のベクトルをそれぞれオフセットとして加えて、5回プログラムを実行し、生成した画像をまとめたものがこれです。
④やや左向きが、やや色々な顔の向きが混在しているものの、全体としては概ね顔の向きをコントロールできていると思います。
なお、顔画像生成器を改造して作成した、生成画像とその時の入力ベクトルを保存するプログラムをGithub(https://github.com/cedro3/dcgan)に上げておきますので、良かったら動かしてみてください。
では、また。













コメントを残す