
1.はじめに
今回ご紹介するのは、静止画の人物を動画に合わせて動かす Motion Representations for Articulated Animation と呼ばれる技術です。
2.Motion Representations for Articulated Animation とは?
下記にネットワークのフローを示します。
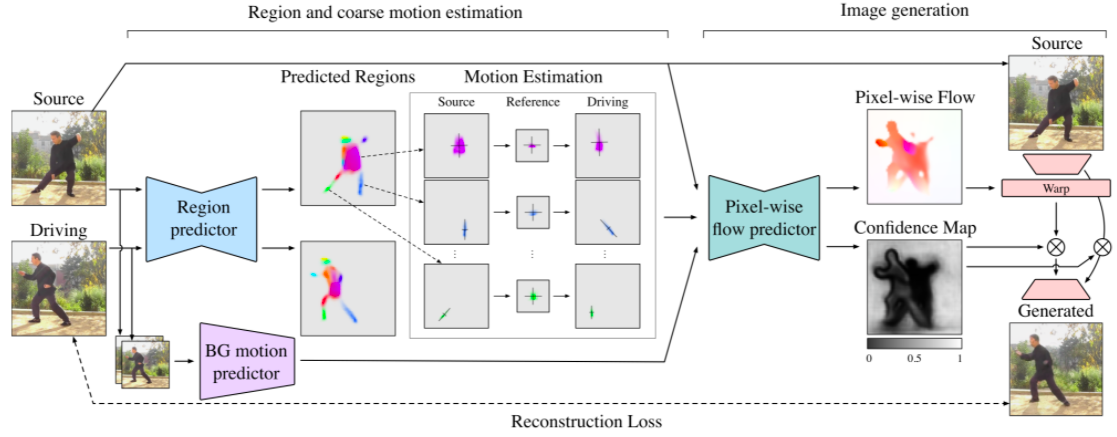
まず、Source(静止画)とDriving(動画)を Region predictor に入力してそれぞれヒートマップを取りし、ヒートマップの領域毎に Refarence(基準)に対して Source が Driving へどう変化しているか計算します。一方、Source と Driving は BG motion predictor にも入力して領域と背景の情報を取り出します。
これら2つ結果を Pixel-wise flow predictor で結合して、Pixel-wise Flow(ピクセル毎の変化) と Confidence Map(信頼マップ) を出力します。そして、Source の各ピクセルを Pixel-wise Flow によってワープし、人物が動くことによって発生する新たな領域をConfidence Map によって修復することよって最終出力を得ます。
では、コードを動かしてみましょう。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。Githubからコードを取得し、学習済みパラメータをダウンロードします。
|
1 2 3 4 5 |
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash !sudo apt-get install git-lfs !git lfs install !git clone https://github.com/snap-research/articulated-animation/ %cd articulated-animation |
|
1 2 3 4 5 6 7 |
import gdown gdown.download('https://drive.google.com/uc?id=1YHhLDf7QGhVUyAIMRsJBmCm0VDDcQdVV', './pt.zip', quiet=False) ! unzip pt.zip -d checkpoints from demo import load_checkpoints generator, region_predictor, avd_network = load_checkpoints(config_path='config/ted384.yaml', checkpoint_path='checkpoints/ted384.pth') |
次に、静止画を動画に合わせてアニメーションを行います。./sup-mat から静止画(01.jpg)と動画(movie.mp4)の読み込み、確認のため表示させます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import imageio import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from skimage.transform import resize from IPython.display import HTML import warnings warnings.filterwarnings("ignore") source_image = imageio.imread('sup-mat/01.jpg') driving_video = imageio.mimread('sup-mat/movie.mp4') source_image = resize(source_image, (384, 384))[..., :3] driving_video = [resize(frame, (384, 384))[..., :3] for frame in driving_video] def display(source, driving, generated=None): fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6)) ims = [] for i in range(len(driving)): cols = [source] cols.append(driving[i]) if generated is not None: cols.append(generated[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000) plt.close() return ani HTML(display(source_image, driving_video).to_html5_video()) |

アニメーションを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 |
from demo import make_animation from skimage import img_as_ubyte predictions = make_animation(source_image, driving_video, generator, region_predictor, avd_network, animation_mode='avd') #save resulting video imageio.mimsave('generated.mp4', [img_as_ubyte(frame) for frame in predictions]) #video can be downloaded from /content folder HTML(display(source_image, driving_video, predictions).to_html5_video()) |

今まで、こういう変換をしようとすると静止画の手は体と離れていないと上手く認識が出来なかったのですが、この技術はある程度上手くこなせているようです。
では、また。
(オリジナルGithub)https://github.com/snap-research/articulated-animation














Colabで動かしてみました!
元からある画像ではColabのランタイムはクラッシュしませんでしたが、
画像を別のものに変えるとRAMが足りなくてクラッシュしました。
そして、画像と動画を384×384ではなく、100×100にするとセルのエラーが出ました。どうすればよいでしょうか。
田中さん
コメントありがとうございます。
動画の長さを短くしてみて下さい。sup-matにある動画は13〜14秒程度です。
ありがとうございます。
試してみます!
訂正:なので、画像と動画を384×384ではなく、100×100にすると最後のセルでエラーが出ました。
cedroさん、
大変有用な情報を共有いただきましてありがとうございます。
Githubの動くコードに感動してガシガシ動かしています。(大変恐縮ですが、cedroさんが、SONY Neural Network Consoleに恋されたように、私はcedroさんのコードとOutputに感嘆しております。)
無理をなさらず続けていただけることを願っています。
田中さん、
私も同じ状態になりました。
最後の”アニメーションの作成”セルの11行目のコードを書き換えると動きました。
書き換え例:11行目と12行目を以下に変更すると動きます。 (不要な” , driving_video”を削除しています。)
#HTML(display(source_image, driving_video, predictions).to_html5_video()) # 11行目:オリジナルをコメントとして残す
HTML(display(source_image, predictions).to_html5_video()) # 12行目 オリジナルより, driving_videoを削除
かつさん
コメントありがとうございます。
情報提供、感謝いたします。