
1.はじめに
従来、StyleGANのドメイン変換(例えば実写からアニメ)は、ソースモデルとターゲットモデルのレイヤースワップが一般的でしたが、その場合ドメイン変換の度合いを制御するにはかなり制約がありました。
今回ご紹介するのは、ターゲットモデルの学習時に工夫を行うこでとで、ドメイン変換の度合いを制御できるFix Noiseという技術です。
*この論文は、2022.5に提出されました。
2.FixNoiseとは?
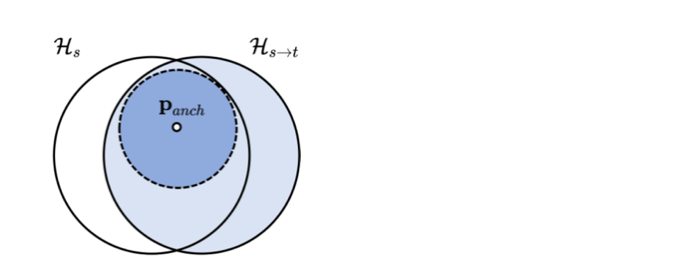
下図のように、ソースの潜在空間をHs、ターゲットの潜在空間をHs→tとします。そして、ターゲットモデルを学習するときに、ランダムノイズをHsとHs→tが交わる潜在空間にマッピングするように、FixNoiseでランダムノイズの中心点(Panch)を補正します。
学習後は、FixNoiseの補正係数を調整することによって、ターゲットモデルの出力画像へのソースの反映度を制御できます。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
#@title **1.セットアップ** # get code from github ! git clone https://github.com/cedro3/FixNoise.git %cd FixNoise # install library ! pip install legacy pyspng ninja imageio-ffmpeg==0.4.3 lpips # download pretrained_models ! mkdir pretrained import gdown gdown.download('https://drive.google.com/uc?id=1YHa_g5xC_VM5MbHsr3VSfco1_PX1sRkA', 'pretrained/wikiart-fm0.05-004032.pkl', quiet=False) gdown.download('https://drive.google.com/uc?id=1Eo4T9KjkzRYdnENXgTpqIUOvaY4-SDeD', 'pretrained/metfaces-fm0.05-001612.pkl', quiet=False) gdown.download('https://drive.google.com/uc?id=1GzM3icWaSOSGcKfYoidjEaloqc_MyAxX', 'pretrained/aahq-fm0.05-010886.pkl', quiet=False) # import library from torchvision.utils import make_grid import os import torch import PIL.Image import imageio import numpy as np #from IPython.display import Video from IPython.core.display import Video #from legacy import load_network from legacy import * # inital setting c_dim = 0 img_resolution = 256 img_channels = 3 # difine function def generate_blended_img(G_s, G_t, z=None, blend_weights=[0,0.25,0.5,0.75,1], truncation_psi=0.7, truncation_cutoff=8): all_images = [] if z == None: z = torch.randn([1,512]).cuda() assert z.shape == torch.Size([1, 512]) c = torch.zeros(1,0).cuda() img = G_s(z, c, truncation_psi, truncation_cutoff, noise_mode='const') all_images.append(img) for weight in blend_weights: img = G_t(z, c, truncation_psi, truncation_cutoff, noise_mode='interpolate', blend_weight=weight) all_images.append(img) all_images = torch.cat(all_images) images = make_grid(all_images, nrow=len(blend_weights)+1, padding=5, pad_value=0.99999) images = (images.permute(1, 2, 0) * 127.5 + 128).clamp(0, 255).to(torch.uint8).cpu().numpy() images = PIL.Image.fromarray(images, 'RGB') return images from IPython.display import display, HTML def display_mp4(path): from base64 import b64encode mp4 = open(path,'rb').read() data_url = "data:video/mp4;base64," + b64encode(mp4).decode() display(HTML(""" <video width=700 controls> <source src="%s" type="video/mp4"> </video> """ % data_url)) |
学習済みモデルは、Metafaces(FFHQ → MetFaces)、aahq(FFHQ → AAHQ)、wikiart(Church → Cityscape) の3つが用意されていますので、target_datasetでモデルを選択し実行すると、モデルがロードされます。ここでは、aahqを選択して実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#@title **2.セレクト・モデル** target_dataset = 'aahq' #@param ['metfaces', 'aahq', 'wikiart'] if target_dataset == 'metfaces': cfg = 'paper256' source_pkl = 'https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/transfer-learning-source-nets/ffhq-res256-mirror-paper256-noaug.pkl' target_pkl = 'pretrained/metfaces-fm0.05-001612.pkl' if target_dataset == 'aahq': cfg = 'paper256' source_pkl = 'https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/transfer-learning-source-nets/ffhq-res256-mirror-paper256-noaug.pkl' target_pkl = 'pretrained/aahq-fm0.05-010886.pkl' if target_dataset == 'wikiart': cfg = 'stylegan2' source_pkl = 'https://nvlabs-fi-cdn.nvidia.com/stylegan2/networks/stylegan2-church-config-f.pkl' target_pkl = 'pretrained/wikiart-fm0.05-004032.pkl' G_s = load_network(cfg, source_pkl, img_resolution, img_channels, c_dim).cuda() G_t = load_network(cfg, target_pkl, img_resolution, img_channels, c_dim).cuda() |
まず、FixNoiseによる補正係数を100%、75%、50%、25%、0%に変化させた時の画像を生成してみましょう。
|
1 2 3 |
#@title **3.補間画像** generate_blended_img(G_s, G_t) |

それでは、FixNoiseによる補正係数を変化させたときの画像から動画を作ってみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#@title **4.補間動画** num_step = 201 truncation_psi = 0.7 truncation_cutoff = 8 blend_weights = np.linspace(0,1,num_step) outdir = 'results' os.makedirs(outdir, exist_ok=True) video = imageio.get_writer(f'{outdir}/noise_interpolation_{target_dataset}00.mp4', mode='I', fps=50, codec='libx264', bitrate='16M') z = torch.randn([1,512]).cuda() c = torch.zeros(1,0).cuda() img_source = G_s(z, c, truncation_psi, truncation_cutoff, noise_mode='const') for weight in blend_weights: img = G_t(z, c, truncation_psi, truncation_cutoff, noise_mode='interpolate', blend_weight=weight) all_images = torch.cat([img_source, img]) images = make_grid(all_images, nrow=2, padding=0) images = (images.permute(1, 2, 0) * 127.5 + 128).clamp(0, 255).to(torch.uint8).cpu().numpy() video.append_data(images) video.close() display_mp4('results/noise_interpolation_'+target_dataset+'00.mp4') |
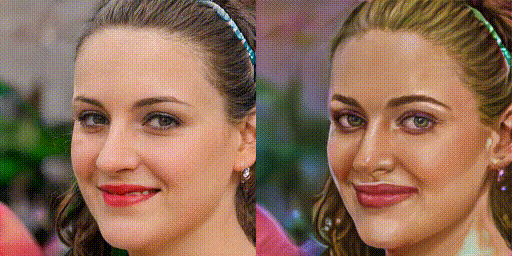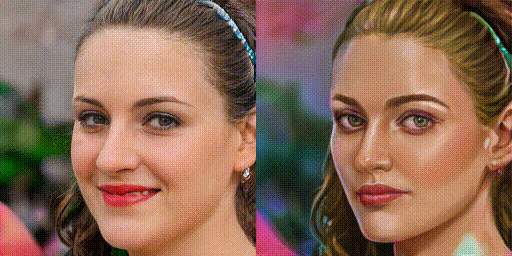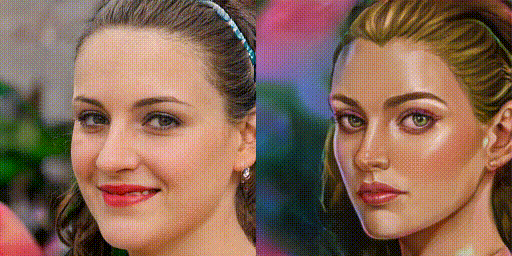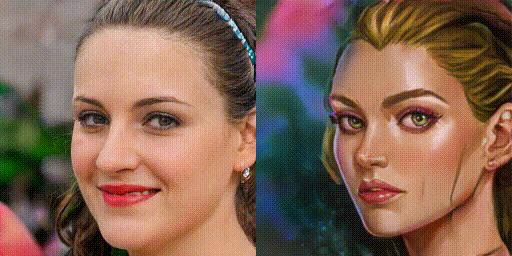
ドメイン変換の度合いをきめ細かく調整できるのは、便利そうですね。
では、また。
(オリジナルgithub)https://github.com/LeeDongYeun/FixNoise













コメントを残す