
今回は、変分オートエンコーダで顔画像を2次元マップにマッピングしてみます。
こんにちは cedro です。
先回、変分オートエンコーダをMNISTでやってみて、潜在変数Zの2次元マップに綺麗に数字が分類されるのをみて中々興味深かったので、今度はオリジナルデータセットでやってみます。
過去に作ったデータセットはブログに投稿すると大体削除してしまい、あまり残っていないのですが、5/4のブログ「DCGAN 生成される顔画像の向きをコントロールする」で使った顔画像のデータセットが残っていたので、これを使うことにしました。
このデータセットは、カラー64×64の顔画像で右向き、左向き、正面の3種類に分けて収集したもので、全部で2,400枚×3種類=7,200枚あります。
ということで、今回は、変分オートエンコーダで顔画像を2次元マップにマッピングしてみます。
データセットを準備する
まず、今回使うデータセットの概要をご紹介します。
 右向き2,400枚です。ラベル0とします。正面ぽいのも多少交じっています。^^;
右向き2,400枚です。ラベル0とします。正面ぽいのも多少交じっています。^^;
 左向き2,400枚です。ラベル1とします。左向きと言っても左斜め下とか、左斜め下もあったり します。 ^^ ;
左向き2,400枚です。ラベル1とします。左向きと言っても左斜め下とか、左斜め下もあったり します。 ^^ ;
 正面2,400枚です。ラベル2とします。
正面2,400枚です。ラベル2とします。
今回使うサンプルプログラムはMNIST用なので、実際にはこのデータセットをモノクロ28×28に変換したものを使うことにします。
プログラムが格納してあるフォルダーに、faceフォルダーを作成し、その下に0、1、2のフォルダーを作成し、それぞれにモノクロ28×28の画像データを2,400枚づつ格納します。
プログラムを改造します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from __future__ import absolute_import from __future__ import division from __future__ import print_function from keras.layers import Lambda, Input, Dense from keras.models import Model from keras.datasets import mnist from keras.losses import mse, binary_crossentropy from keras.utils import plot_model, np_utils ### 追加 from keras import backend as K from keras.preprocessing.image import array_to_img, img_to_array, list_pictures, load_img ### 追加 from sklearn.model_selection import train_test_split ### 追加 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(x_test, batch_size=batch_size) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y_test) #plt.colorbar() ### colorbar を使用しない plt.xlabel("z[0]") plt.ylabel("z[1]") plt.savefig(filename) #plt.show() ### 表示させない |
0〜2だけなので、colorbar は表示させません。また、filenameもあえて表示させません(一端表示すると、表示中止ボタンを押すまで動作が中断して、使い勝手が悪いので)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# display a 30x30 2D manifold of digits n = 15 ### 30 → 15に変更 digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) # linearly spaced coordinates corresponding to the 2D plot # of digit classes in the latent space grid_x = np.linspace(-4, 4, n) grid_y = np.linspace(-4, 4, n)[::-1] for i, yi in enumerate(grid_y): for j, xi in enumerate(grid_x): z_sample = np.array([[xi, yi]]) x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size) plt.imshow(digit,cmap='Greys_r') ### 追加 plt.savefig(str(i)+'@'+str(j)+'fig.png') ### 追加 figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit |
マップが30×30では顔画像小さくなって見難くなるので、15×15に変更しています。
また、出力画像は後でGIF動画を作成するために、1枚づつ 0@0fig.png 〜 14@14fig.png まで225枚分(15×15=225)を保存する設定にしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# MNIST dataset #(x_train, y_train), (x_test, y_test) = mnist.load_data() #image_size = x_train.shape[1] #original_dim = image_size * image_size #x_train = np.reshape(x_train, [-1, original_dim]) #x_test = np.reshape(x_test, [-1, original_dim]) #x_train = x_train.astype('float32') / 255 #x_test = x_test.astype('float32') / 255 ### face daterset x = [] y = [] for picture in list_pictures('./face/0'): img = img_to_array(load_img(picture, grayscale=True, target_size=(28,28))) x.append(img) y.append(0) for picture in list_pictures('./face/1'): img = img_to_array(load_img(picture, grayscale=True, target_size=(28,28))) x.append(img) y.append(1) for picture in list_pictures('./face/2'): img = img_to_array(load_img(picture, grayscale=True, target_size=(28,28))) x.append(img) y.append(2) x = np.asarray(x) y = np.asarray(y) x = x.astype('float32') x = x/ 255.0 x = x.reshape(7200, 784) y = np_utils.to_categorical(y, 3) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) original_dim = 784 |
データセットの読み込み部分です。MNISTの読み込み部分は、無効にします(削除でもOK)。
list_picture, load_img, img_to_arry を使って3種類のデータを読み込んで必要な処理をした後に、train_test_split で学習用80%・評価用20%に分割しています。
プログラムを動かしてみます
|
1 2 3 |
python variational_autoencoder.py |
上記コマンドで、プログラムを開始します。
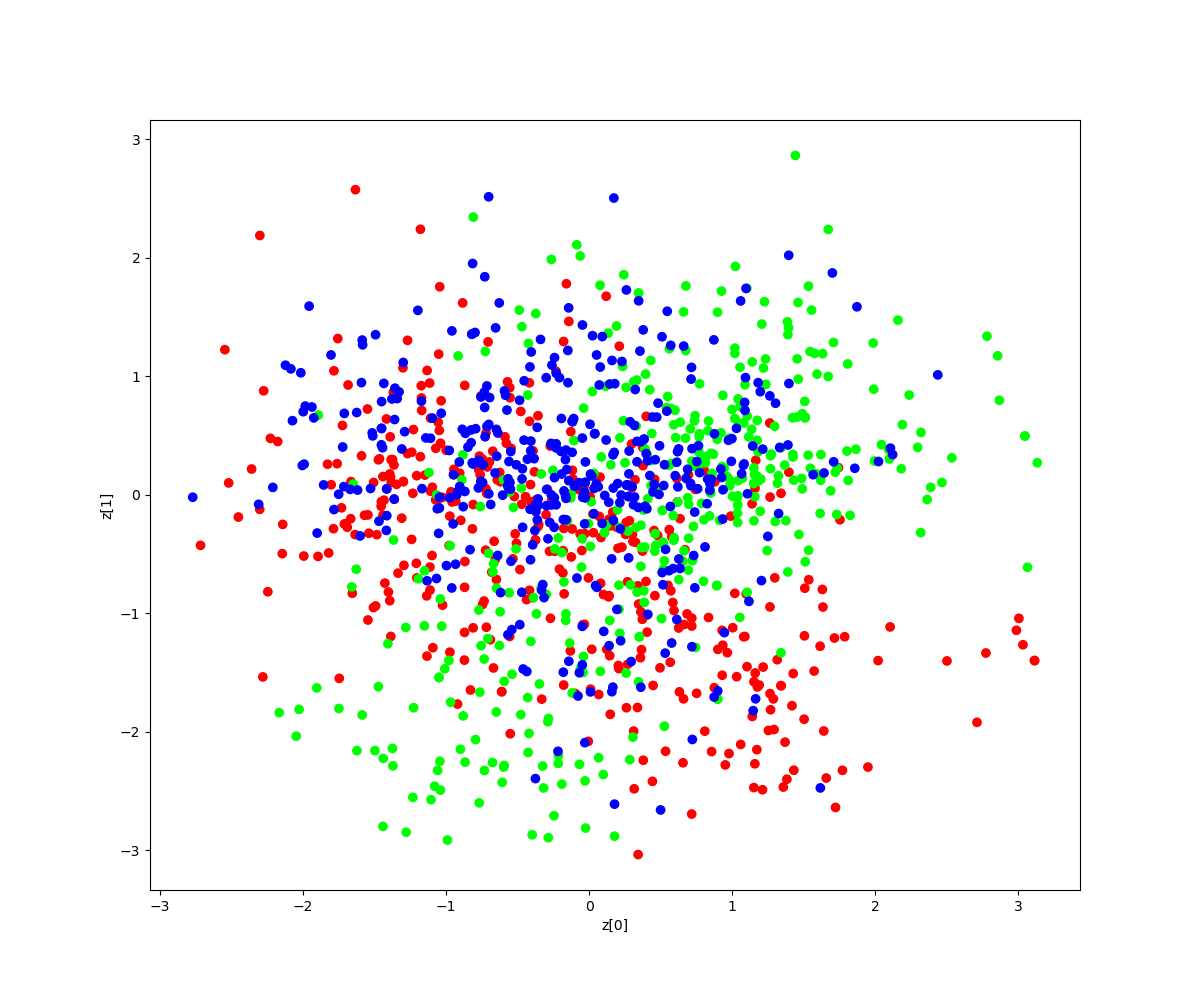
潜在変数Zの2次元マップに、右向き(0)、左向き(1)、正面(2)をマッピングした結果がこれです。なんとなく分類されている様ですが、結構重なり合っていますね(笑)。
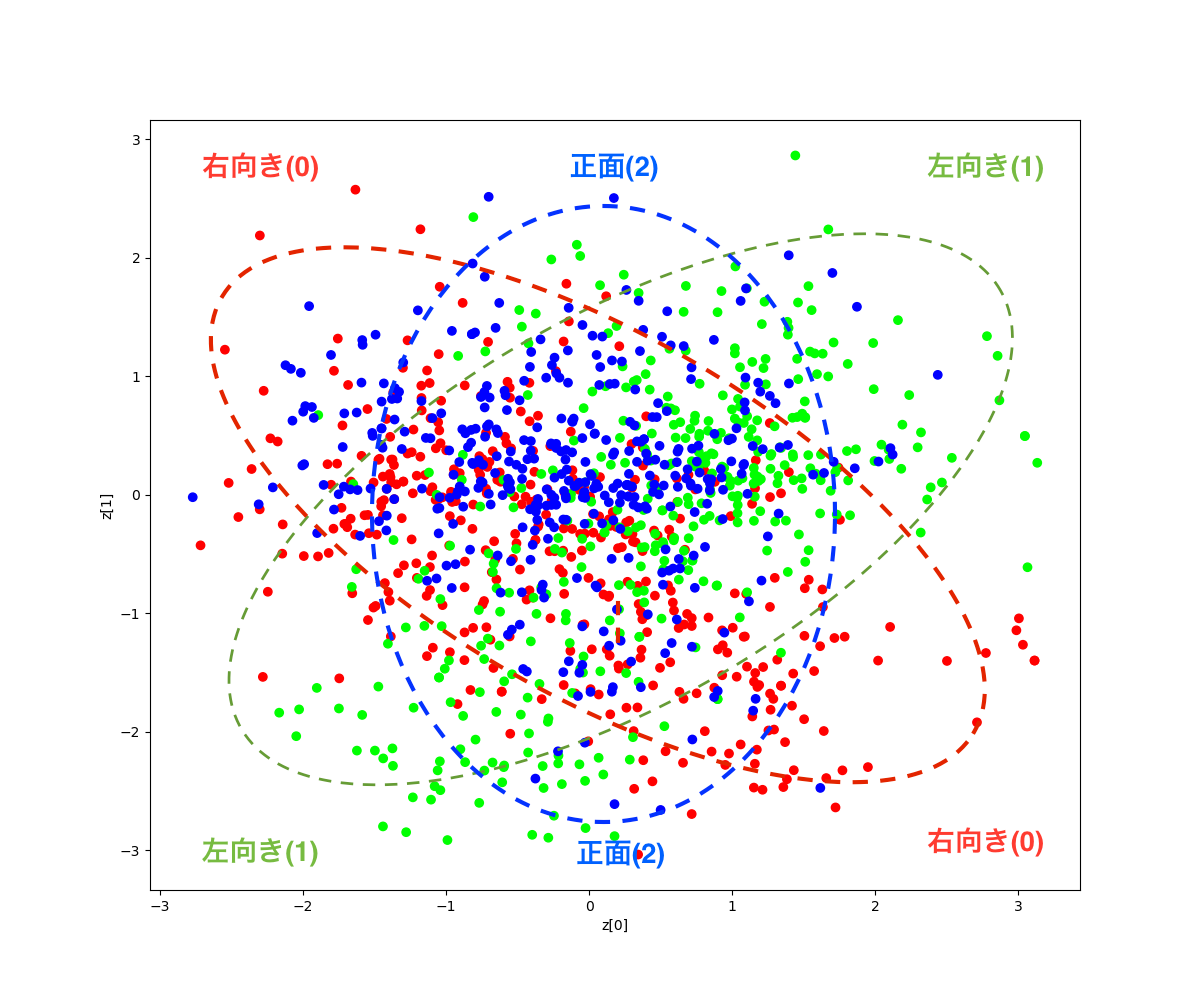
無理やり、点線で囲って分類してみると、こんな感じでしょうか(笑)。そう言われれば、なんとなくそんな気もするでしょう?
さて、どんな画像が生成されるのでしょうか。
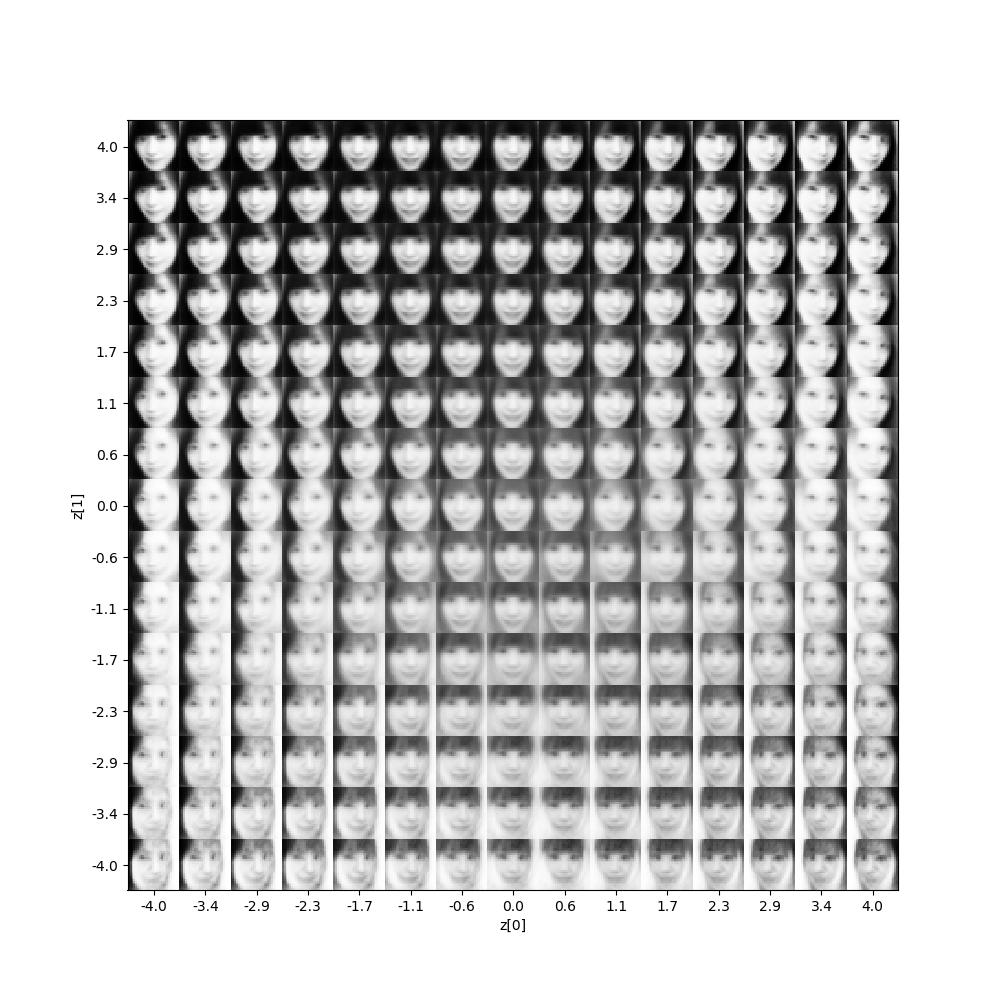
潜在変数Zのデータから、どのような出力が生成されるかマッピングさせた結果です。
さすが、変分オートエンコーダー! 期待通り、顔の向きをキーに綺麗な分布に仕上げてくれました。
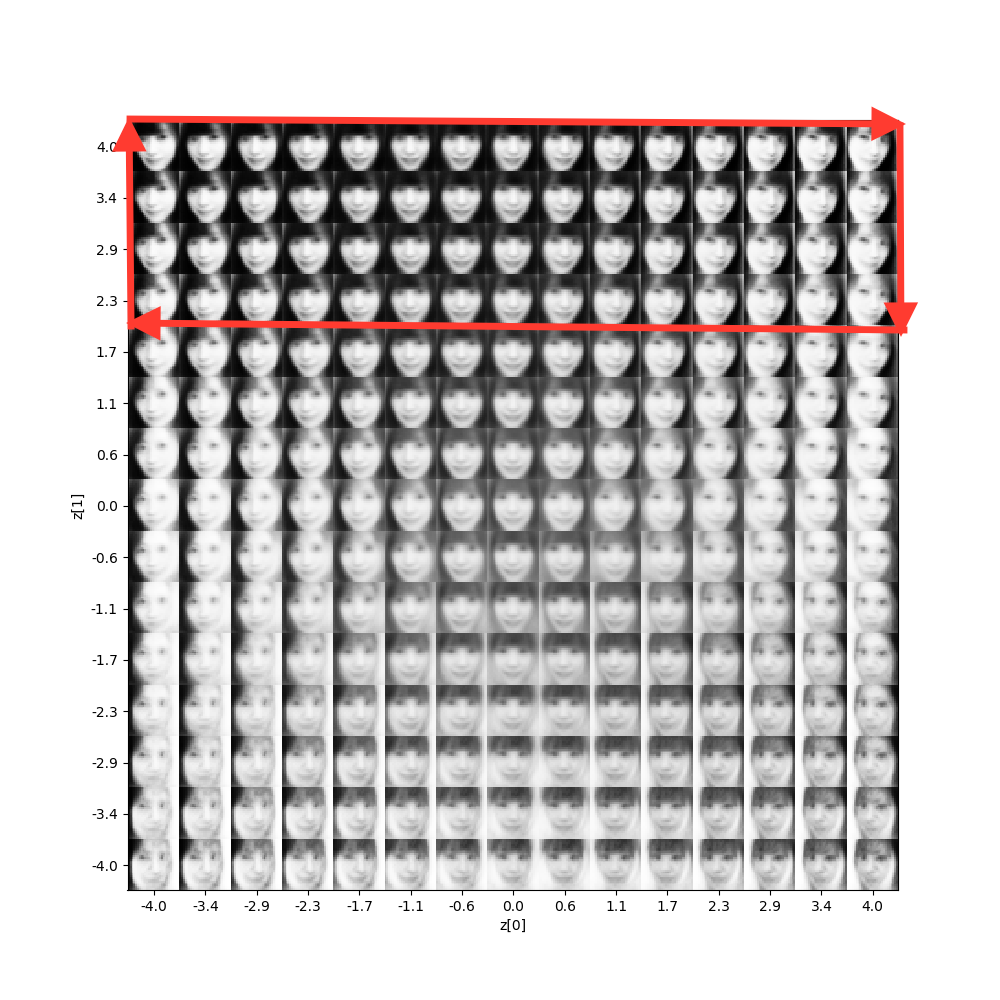
それでは、潜在変数Zのデータを赤矢印の様に操作して画像を生成させてみましょう。といっても、既に保存されている、1枚単位の画像の中から、該当するものを拾って、 GIF動画にするだけです。
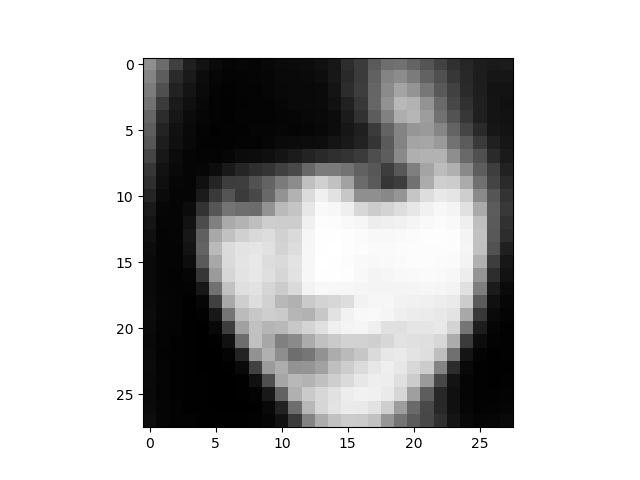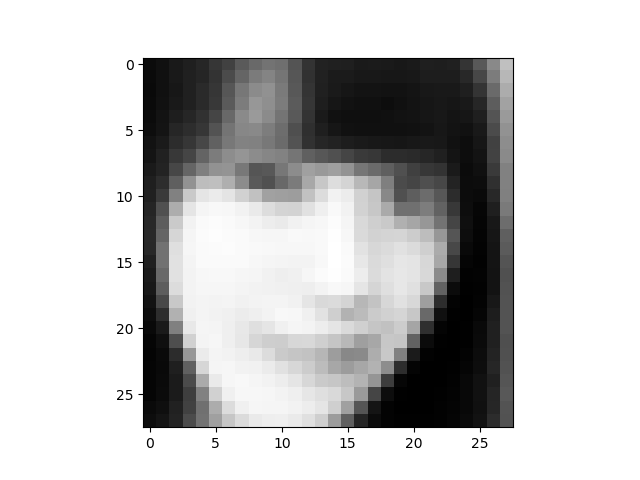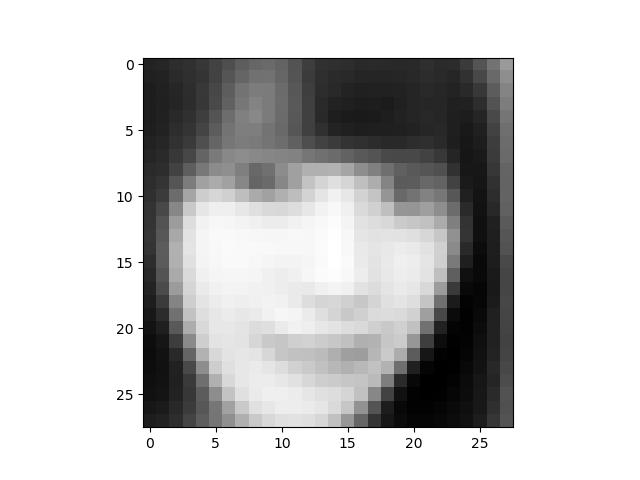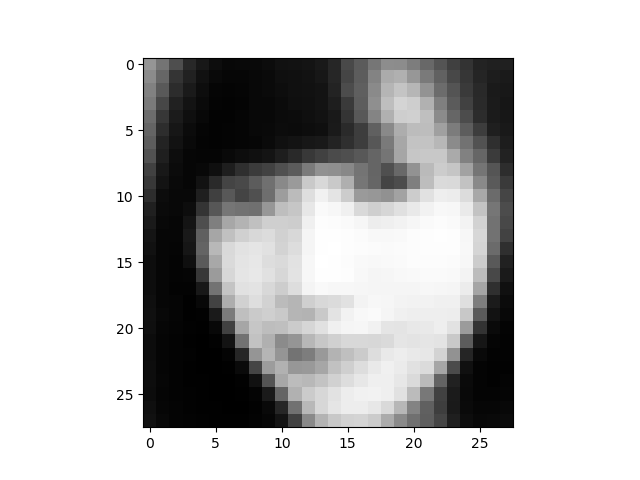
画像がモノクロ28×28のため、かなりボケた感じになります。ディスプレイから少し離れて、目を細めてご覧ください(笑)。
但し、ポイントとなる顔の向きの情報は、はっきり捕まえていますね。
変分オートエンコーダ、中々やります。
では、また。














コメントを残す