
今回は、学習済みWord2vecモデルを使って、類似単語の抽出や単語の演算をしてみたいと思います。
こんにちは cedro です。
単語をベクトルで表現するためには、下記1)〜4)のステップが必要で、結構手間が掛かります。
1)大量な文章(Wikipedia など)を収集する
2)収集した文章の中で不要な部分を削除する
3)形態素分析エンジン(MeCabなど)を使って適切な単語に分割したデータを作成する
4)gensimなどを使ってデータを学習させ、Word2vec モデルを作成する
*どうやって単語をベクトル化するのか知りたい方は、このブログが分かりやすいです。
今回は、1)〜4)のステップが終わっている、学習済みのWord2vecモデルを使って、お手軽に類似単語の抽出や単語の演算をして遊んでみたいと思います。
学習済みWord2vec モデルを入手する
今回使うのは東北大学 乾・岡崎研究室で作られたモデルです。これは、日本語 Wikipedia の本文全文を元に学習したもので、ベクトルは200次元です。
このリンクで研究室のホームページに行き、20170201.tar.bz2 (2017年2月1日版, 1.3GB, 解凍後 2.6GB)をダウンロードして下さい。
解凍すると、バイナリファイル (entity_vector.model.bin) とテキストファイル (entity_vector.model.txt) の2つが現れます。バイナリファイルは Word2vecモデル、テキストファイルは、その内容を可視化したものです。
まず、テキストファイルを見て、単語がどういうふうにベクトル化されているか見てみましょう。容量が1.95GBもありますので、表示されるまでに多少時間がかかります。
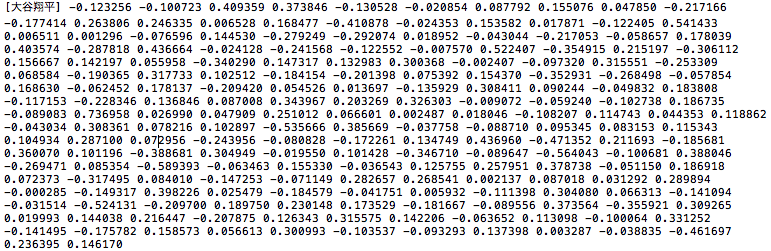
例えば、「大谷翔平」をベクトル化した結果がこれです。−1〜+1に正規化された200個の数字で表されています(1行200列の行列と思ってもらっても良いです)。
一端、この様に単語をベクトル化してしまえば、似た様な単語(ベクトルが似ている単語)を見つけたり、単語の演算ができることが分かると思います。
それでは、早速Word2vecモデルを使って遊んでみたいと思いますが、その前にまだ gensim をインストールしてない場合は、このブログを参考に、インストールして下さい。
類似単語を抽出してみます
適当な所にフォルダーを作成して、ダウンロードしたバイナリファイル (entity_vector.model.bin) を格納します。
|
1 2 3 4 5 6 7 8 |
from gensim.models import KeyedVectors model_dir = './entity_vector.model.bin' model = KeyedVectors.load_word2vec_format(model_dir, binary=True) results = model.most_similar(u'[指原莉乃]') for result in results: print(result) |
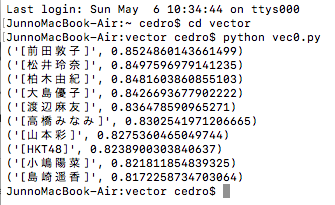
「指原莉乃」と似ているベクトルを持つ単語を検索してみます。
似ている単語を検索する場合は、results = model.most_similar( u'[指原莉乃]’ ) という式を使います。上記プログラムをvec0.py として、バイナリファイルと同じフォルダーに保存します。
ターミナルを開いて、バイナリーファルとvec0.py が保存されているフォルダーに移動し、python vec0.py でプログラムを実行します。
左側が類似単語、右側が類似確率を表し、トップ10が表示されます。1位は「前田敦子」で類似確率は85.2%となりました。まあ順当な所でしょうか。
人物名ではなく、抽象的な概念もやってみましょう。プログラムの「指原莉乃」を「人生」に置き換えて、vec1.py で保存します。
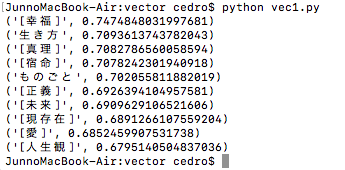
『人生」の類似単語の検索結果です。1位は「幸福」でした。ちゃんと抽象的な概念も、類似単語を検索できていますね。
単語の引き算をしてみます
|
1 2 3 4 5 6 7 8 |
from gensim.models import KeyedVectors model_dir = './entity_vector.model.bin' model = KeyedVectors.load_word2vec_format(model_dir, binary=True) results = model.most_similar(positive=[u'[妻]'],negative=[u'[愛人]']) for result in results: print(result) |
単語の引き算は results = model.most_similar( positive=[u'[妻]’], negative=[u'[愛人]’] ) という式を使います。このプログラムをvec2.pyで保存します。
「妻」から「愛人」を引くので、「妻」が持っていて「愛人」は持っていないものが残ることになります。

「妻」ー「愛人」= の演算結果です。「分娩」、「座位」、「出産」、「生殖」、「子育て」など、子供に関するリアルな単語が多いですね。
世の中には愛人に子供を作らせる豪快な方もみえますが、ほとんどの方々は愛人には子供を作らせませんからね。
次に、「悪魔」から「悪」を引くとプログラムに書き換えてみます。vec3.py で保存します。
えっ? 「悪魔」ー「悪」=「やさしい悪魔」じゃあないかって? あなた、元キャンディーズファンですね(笑)。
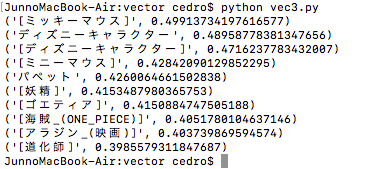
「悪魔」ー「悪」= の演算結果です。これは意外な結果でした。まさか、「悪魔」から「悪」を引いたら、「ミッキーマウス」になるとは。6位の「妖精」や9位の「アラジン」はなるほどという感じです。
ただ、「ミッキーマウス」が邪悪になると、結構怖い気がします(笑)。
単語の足し算をしてみます
|
1 2 3 4 5 6 7 8 |
from gensim.models import KeyedVectors model_dir = './entity_vector.model.bin' model = KeyedVectors.load_word2vec_format(model_dir, binary=True) results = model.most_similar(positive=[u'[妖精]',u'[悪]']) for result in results: print(result) |
単語の足し算は results = model.most_similar( positive=[u'[妖精]’,u'[悪]’] ) という式で表します。このプログラムをvec4.pyで保存します。
「妖精」と「悪」を足し算するので、「妖精」の持っているものと「悪」の持っているものの両方を持っているものになるはずです。
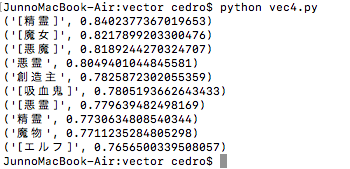
「妖精」+「悪」= の演算結果です。「魔女」とか「悪魔」はよく分かりますが、「精霊」というのは悪意を持っているんですね。
さて、今度は「公務員」+「ピストル」= を計算してみます。vec5.pyで保存します。「公務員」でしかも「ピストル」を持っているとすると。。。

「公務員」+「ピストル」= の演算結果がこれです。はい、ご想像の通り「警察官」になりました。
単語の加減算をしてみます
|
1 2 3 4 5 6 7 8 |
from gensim.models import KeyedVectors model_dir = './entity_vector.model.bin' model = KeyedVectors.load_word2vec_format(model_dir, binary=True) results = model.most_similar(positive=[u'[イチロー]',u'[サッカー]'],negative=[u'[野球]']) for result in results: print(result) |
単語の加減算は results = model.most_similar( positive=[u'[イチロー]’,u'[サッカー]’], negative=[u'[野球]’] ) という式で表します。vec6.py で保存します。
これは、「イチロー」から「野球」という属性を引いて、「サッカー」という属性を足しているので、「サッカー」界の「イチロー」は誰?という計算をすることになります。

「イチロー」ー「野球」+「サッカー」= の演算結果が、これです。1位は「ロナウド」でした。なるほどなるほど。
「新宿」ー「東京」+「大阪」= も計算してみましょう。「大阪」でいう「新宿」は何処? という計算になります。vec7.pyとします。
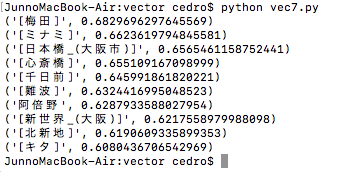
「新宿」ー「東京」+「大阪」= の演算結果がこれです。1位は「梅田」でした。
「大阪」でいう「新宿」は「梅田」なんですね。
今回は、学習済みのword2vecモデルを使って遊んでみました。
お休みの日の午後に、サクッとやってみるには丁度良いのではないでしょうか。
では、また。












コメントを残す