
1.はじめに
今回ご紹介するのは、画像から文章を生成するタスクを高速に学習できるClipCapという技術です。
*この論文は、2021.11に提出されました。
2.ClipCapとは?
高速に学習できる秘密は、学習済みのCLIPとGPT2(いずれもOpenAIによって開発)を組み合わせて学習させることにあります。
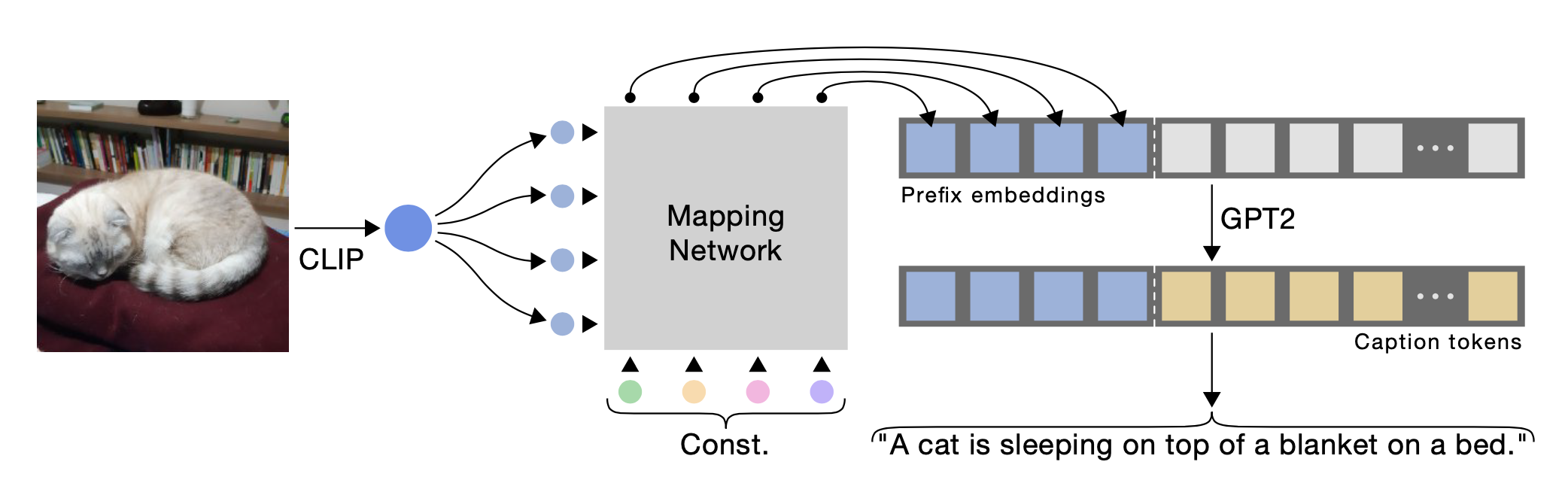
下記の図がClipCapのフロー図です。まず、学習済みCLIPで画像を特徴ベクトルに変換し、マッピングネットワーク(Mapping Network)を通して文の先頭に埋め込み(Prefix embedings)ます。そして、GPT2で文の先頭の埋め込みに続く文を学習させるわけです。
インターネット上にある膨大な画像とテキストのペアを学習したCLIPを使うことによって、最初から最適な画像の特徴ベクトルを得られるため、高速な学習が可能となります。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#@title セットアップ # install transformer & CLIP ! pip install transformers ! pip install git+https://github.com/openai/CLIP.git # get code from github ! git clone https://github.com/cedro3/CLIP_prefix_caption.git %cd CLIP_prefix_caption # install library ! pip install cog ! pip install redis # define function from predict import * from function import * # CLIP model + GPT2 tokenizer clip_model, preprocess = clip.load("ViT-B/32", device='cuda', jit=False) tokenizer = GPT2Tokenizer.from_pretrained("gpt2") # download pretrained_model ! mkdir pretrained_model ! pip install --upgrade gdown import gdown gdown.download('https://drive.google.com/uc?id=14pXWwB4Zm82rsDdvbGguLfx9F8aM7ovT', 'pretrained_model/conceptual_weights.pt', quiet=False) gdown.download('https://drive.google.com/uc?id=1IdaBtMSvtyzF0ByVaBHtvM0JYSXRExRX', 'pretrained_model/coco_weights.pt', quiet=False) |
学習済みのパラメータは coco と concetual の2つが用意されていますので、select でどちらかを選択してモデルにロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#@title モデル選択 select ='coco' #@param ['coco', 'conceptual'] if select == 'coco': model_path = 'pretrained_model/coco_weights.pt' else: model_path = 'pretrained_model/conceptual_weights.pt' prefix_length = 10 model = ClipCaptionModel(prefix_length) model.load_state_dict(torch.load(model_path, map_location=CPU)) model = model.eval() model = model.to('cuda') |
サンプル画像を表示します。自分の用意した画像を使いたい場合は、coco の場合は images_coco フォルダへ、conceptual の場合は images_conceptual フォルダへアップロードして下さい。
|
1 2 3 |
#@title サンプル画像表示 folder = 'images_'+model_name display_pic(folder) |

それでは画像から文を生成してみましょう。表示されたサンプル画像の中から1つ選んで image に記入し、実行します。ここでは、05.jpgでやってみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#@title 画像から文の生成 image = '05.jpg' #@param {type:"string"} image_path = 'images_'+select+'/'+image use_beam_search = False #@param {type:"boolean"} image = io.imread(image_path) pil_image = PIL.Image.fromarray(image) #pil_img = Image(filename=UPLOADED_FILE) display(pil_image) image = preprocess(pil_image).unsqueeze(0).to('cuda') with torch.no_grad(): # if type(model) is ClipCaptionE2E: # prefix_embed = model.forward_image(image) # else: prefix = clip_model.encode_image(image).to('cuda', dtype=torch.float32) prefix_embed = model.clip_project(prefix).reshape(1, prefix_length, -1) if use_beam_search: generated_text_prefix = generate_beam(model, tokenizer, embed=prefix_embed)[0] else: generated_text_prefix = generate2(model, tokenizer, embed=prefix_embed) print('\n') print(generated_text_prefix) |

もう1つ、01.jpgでやってみましょう。

今更ながら、CLIPはさまざまな場面で利用できることに驚きます。
では、また。
(オリジナルgithub)https://github.com/rmokady/CLIP_prefix_caption














コメントを残す