
1.はじめに
今まで、1枚の顔画像から自由に動かせる3Dモデルを生成しようとすると、一般的な表現パラメータのみしか使えず、リアルなアニメーションは出来ないという問題がありました。今回ご紹介するのは、この問題を解決する DECA という技術です。
*この論文は2020.12に提出されました。
2.DECAとは?
DECAは、Detailed Expression Capture and Animation の略で、入力された顔画像を一般的な表現パラメーターと個人固有の詳細パラメーターに分離し、一般的な表現パラメータのみを動かすことによって、詳細3Dモデルを制御する技術です。
まず、DECAの学習時のネットワークを以下に示します。特徴は、顔画像を入力するエンコーダが2つあることです。

エンコーダEcは、カメラ、アルベド、照明、形状、ポーズ、表情といった一般的な表現パラメータを取り出して粗い形状を作成し、入力との差 Lcoarse を学習によって最小化します。
もう1つのエンコーダEdは、個人固有の詳細パラメータを取り出します。そして、Ecからの情報と合わせて詳細形状を作成し、入力との差 Ldetail を学習によって最小化します。
この学習によって、一般的な表現パラメータとそれと連動した個人固有の詳細パラメータを分けて獲得できるようになることがミソです。次に、学習後のネットワークを見てみましょう。
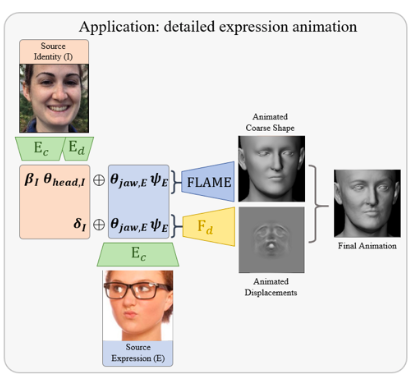
ネットワークに1枚の顔画像を入力すると粗い形状と変位情報から詳細3Dモデルを生成します。そして、エンコーダEcの一般的な表現パラメータのみ変化させると、個人固有の詳細パラメータもそれに連動して詳細3Dモデルを的確に動かせるわけです。
3.コード
コードはGoogle Colabで動かす形にしてGithubに上げてありますので、それに沿って説明して行きます。自分で動かしてみたい方は、この「リンク」をクリックし表示されたノートブックの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
まず、セットアップを行います。ライブラリーを取得し、githubからコードをコピーします。
|
1 2 3 4 5 6 7 8 |
# ライブラリー取得 !pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html !pip install pytorch3d # githubからコードをコピー !git clone https://github.com/cedro3/DECA.git %cd DECA !pip install -r requirements.txt |
次に、google drive から必要なデータをダウンロードし、dataフォルダーにコピーします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# Google drive から必要なデータをダウンロードし、dataフォルダーにコピーする import requests import zipfile def download_file_from_google_drive(id, destination): # ダウンロード画面のURL URL = "https://drive.google.com/u/1/uc?id=117mFRXjRD75YNzS3660BfiZCVgiY-At1&export=download" session = requests.Session() response = session.get(URL, params = { 'id' : id }, stream = True) token = get_confirm_token(response) if token: params = { 'id' : id, 'confirm' : token } response = session.get(URL, params = params, stream = True) save_response_content(response, destination) def get_confirm_token(response): for key, value in response.cookies.items(): if key.startswith('download_warning'): return value return None def save_response_content(response, destination): CHUNK_SIZE = 32768 with open(destination, "wb") as f: for chunk in response.iter_content(CHUNK_SIZE): if chunk: # filter out keep-alive new chunks f.write(chunk) if __name__ == "__main__": file_id = 'TAKE ID FROM SHAREABLE LINK' destination = './deca.zip' # 保存先パスの指定 download_file_from_google_drive(file_id, destination) # zipファイル解凍 zipf = zipfile.ZipFile('./deca.zip') zipf.extractall('./data') zipf.close() |
それでは、デモを行ってみましょう。./TestSamples/examples/ のフォルダーにある顔画像を使用します。
|
1 |
!python demos/demo_reconstruct.py -i TestSamples/examples --saveDepth True --saveObj True |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# display demo_reconstruct import os import cv2 import numpy as np import matplotlib.pyplot as plt import glob files = sorted(glob.glob('./TestSamples/examples/results/*.jpg')) for file in files: fig = plt.figure(figsize=(10,2)) img = cv2.imread(file) img_RGB = img[:, :, ::-1] plt.imshow(img_RGB) plt.show() |



1人につき6枚画像が並んでいます。左から、①対象画像、②2次元顔ランドマーク、③3次元顔ランドマーク(赤は非表示ポイント)、④3Dモデル、⑤詳細3Dモデル、⑥深さを表しています。
せっかくなので、これを動画で行ってみましょう(コードは省略します)。


実際の顔動画があれば、その通り動く詳細3Dモデルが得られることが分かります。ただ、これだけでは応用範囲が限定されます。ある動きを詳細3Dモデルにさせたい時に、必ずその通りに動く顔動画が必要になるからです。
そこで、DECAの狙いである、顔動画無しで詳細3Dモデルを制御するデモをやってみましょう。
|
1 |
!python demos/demo_teaser.py |
|
1 2 3 |
# display demo_teaser from IPython.display import Image Image('./TestSamples/teaser/results/teaser.gif', format='png') |

1人につき、4枚の画像があります。左から、①対象画像、②詳細3Dモデル、③詳細3Dモデルを左右に回転させた動画、④詳細3Dモデルの口を開閉させた動画、です。個人固有の詳細情報は保ったまま上手く動かせていることが分かると思います。
では、また。
(オリジナル github)https://github.com/YadiraF/DECA














コメントを残す