
1.はじめに
文から画像生成をするモデルを使って、出力画像をズームやシフト等をさせ、それを初期値にして文で画像生成することを繰り返すと面白い動画が出来ます。今回ご紹介するのは deforum氏が開発した Stable Diffusion を使った動画生成をするGoogle Colabです。
2.学習済みパラメータのダウンロード
まず学習済みパラメータをダウンロードします。Hugging Faceからアクセストークンの取得をしてない方は、このブログの「2.アクセストークンの取得」を参考に取得してから下記に進んで下さい。
このリンクをクリックし、学習済みパラメータ(stable-diffusion-v-1-4-original)の使用申請をします。I have read the Licence and agree with its terms のチェックボックスにチェックを入れ、Access repository をクリックします。
すると、下記画面が表示されますので、sd-v1-4.ckpt をクリックし学習済みパラメータをダウンロードします。容量は、4.28GBと大きいです。
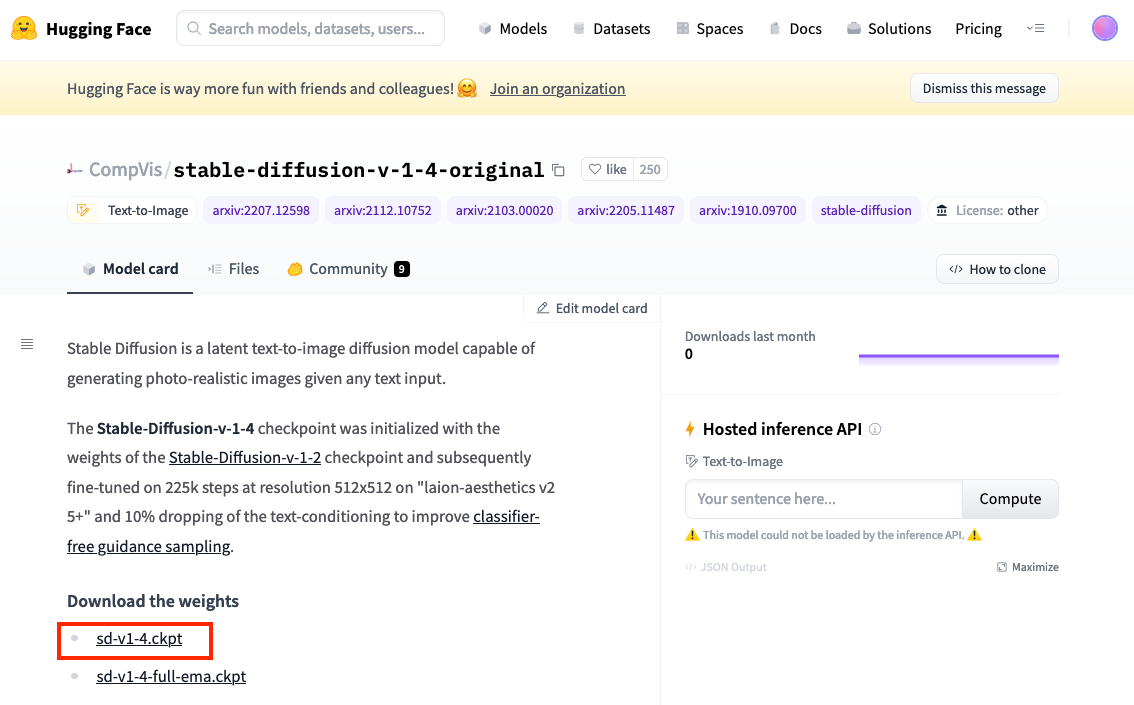
3.使い方
非常に多機能なColabですが、デモ動画を作成するための基本操作だけ説明しますので、後は皆さんが色々といじってみて下さい。最初に、このリンクをクリックしてGoogle Colabを開いて下さい。まず、下記を実行します。

Model and Output Paths まで完了すると、自分の google drive に AI/models と AI/StableDiffusion というフォルダが作成されます。このAI/models の方に、先程ダウンロードした学習済みパラメータ(sd-v1-4.ckpt)をアップロードします。その後、下記を実行します。

次に、アニメーションの設定を行います。animetion_mode でどんなアニメーションにするか選択します(Noneを選ぶとアニメーションを行いません)。max_frames でアニメーション全体のフレーム数を設定します。zoom でフレーム毎の拡大率を設定します(0〜1未満に設定するとズームアウトします)。今回はこのまま、実行します。

次に、画像生成のためのプロンプト(文)を設定します。animation_mode でNoneを設定していると prompts の方が有効となり、None以外の場合は animation_prompts の方が有効になります。1枚の画像だけでアニメーションしたい場合は、animation_prompts の内容を 0:*****の行だけにすればOKです。今回は、このまま実行します。

それでは、アニメーションのフレーム毎に画像生成を行います。下記を実行します。実行すると、1フレームづつ生成した画像を表示して行きます。

最後に、作成したフレームを使って動画を作成します。作成した動画は、AI/StableDiffusion/2022-09/StableFun フォルダの中に作成されます。


ズームインしながら、apple → banana → coconut → durian と画像が変化するアニメーションが出来ました。
それでは、もう1つやってみましょう。先程と変える部分は、Animation Setting で、max_frames = 100, zoom = “0:(1)”, translation_x = “0:(5)” つまり、全体は100フレームでズームはせず左へスクロールする形にします。
Prompts は下記のように変更して実行します。
|
1 2 3 |
animation_prompts = { 0: "The great wave by Hokusai", } |

北斎の「神奈川沖浪裏」の未公開部分が横スクロールする感じで楽しめます(笑)。
では、また。
(twitter投稿)














sd-v1-4.ckptアップロード後に実行していたったら。
Select and Load Modelのところで
下記のエラーが出るためか、その先に進めないのですがどうすればよいのでしょうか?
NameError Traceback (most recent call last)
in
22
23 # config path
—> 24 ckpt_config_path = custom_config_path if model_config == “custom” else os.path.join(models_path, model_config)
25 if os.path.exists(ckpt_config_path):
26 print(f”{ckpt_config_path} exists”)
NameError: name ‘models_path’ is not defined
いてまえさん
今、ブログのリンクから飛んでやってみましたが、残念ながらエラーは再現出来ませんでした。
原因は不明ですが、「models_path が定義されていません」というエラーなので Model and Output Paths が上手く動作していないことになります。例えば Model and Output Paths を飛ばして動かした場合にこの様なエラーが発生します。
再度、初めから試してみてください。
ありがとうございます
もう一度やり直したら、うまく出力できました!
これからも色々と参考にさせて頂きます
cedroさん。
解説、たいへん参考にさせていただいております。
プログラム未経験者の私でも、動かすことができました。ありがとうございます!
可能でしたら、ご教授いただきたいのですが。
横にシフトして動画にしていく場合、現在の絵を元に次の絵を書いていくためか、
絵がどんどん曖昧になっていく、特徴がなくなっていく、形が崩れていく傾向にあります。
これは、何か対処する方法はあるのでしょうか?
(北斎の絵は、そのようになってないですよね。)
sawadaさん
この技術の肝は、インターネット上にある文と画像のペアを膨大に学習することによって、文と画像の関連度を計算するCLIPという技術です。
インターネット上には「北斎」という単語と「例の波の画像」のペアは大量にあり、そのためこのペアの関連度は極めて高くなります。
そのため、横シフトで絵が曖昧になりそうになっても「北斎」という単語がそれを修正して行くパワーを持っているのです。
結論は、横シフトでどれだけ元の絵の特徴を保持できるかは、使っている単語のパワーによります。