
今回は、ImageAugmentation による画像データ水増し効果を確認してみます。
こんにちは cedro です。
ニューラルネットワークを上手に学習させるコツの1つは、大量のデータを入手することです。
例えば、数字の0~9のデータセット MNISTは、学習用に60,000個、評価用に10,000個のデータを持っています。これだけのデータ数があれば、データの水増しは考える必要はないでしょう。
しかし、色々な理由で、そこまで大量のデータを集めるのは難しい場合が結構あります。そんな場合に役に立つのが、データの水増しという手法です。
私は、昨年10月のブログ「SONY Neural Network Console 画像データの水増しは有効か?」で、画像加工ソフトを使ったデータ水増しをやってみた経験がありますが、その時の効果は限定的でした。
そうした中、以前から、Neural Network Console には、データ水増し専用のレイヤー ImageAugmentation があることに気づいてはいたのですが、今まで使ってみたことはありませんでした。
ということで、今回は、 ImageAugmentation による画像データ水増し効果を確認してみたいと思います。
ImageAugmentation とは?
ImageAugmentaion は、複数の設定データに従って、入力画像にランダムな変化を加えて出力するレイヤーです。
つまり、Input レイヤーの次にこれを入れておけば、自動的に画像データの水増しが図れるという便利なレイヤーなのです。
どんな設定が出来るのか、見てみましょう。

これが、ImageAugmentation で設定出来る内容( Layer Property )です。拡大縮小、回転、アスペクト比、歪、左右反転、上下反転、輝度、コントラスト、ノイズ等、様々な設定が可能です。
何をどれ位の範囲で変化させるかだけ最初に設定しておけば、学習時に何をどれだけ効かせるかは Neural Network Console が自動的にランダムに選んで画像に加工を加えてくれます。
正に、お任せの水増しレイヤーなんです。素晴らしい!
では、実際にどんな加工をしてくれるのかを見てみましょう。まず、加工の状況を調べるための簡単なデータセットを作ります。
こんな感じのデータセットです。

「9」フォルダーの中には、この43.png だけ入ってます。
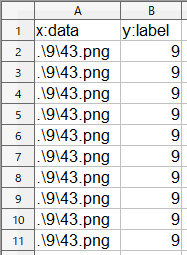
ia_test.csv は、こんな感じ。36個分の同じ「9」のデータを入れてます。違うデータだとランダムに画像に加工を加える状況が見難くなるので、同じデータにしています。データセットが出来たら、Neural Network Console に登録します。

こんなニューラルネットワークを作成します。えっ、これだけで動くの?と思うでしょう。大丈夫、動きます。
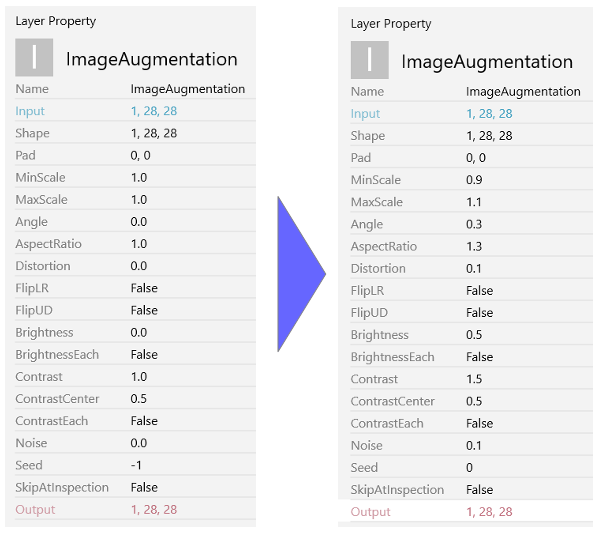
ImageAugmentationの設定を左側のデフォルトから右側へ変更します。拡大縮小、回転、アスペクト比、歪、輝度、コントラスト、ノイズの設定を変更しています。
データセットについては、学習用はダミーなので何でもOKですが、とりあえず mnist_train.csv を選択し、評価用はさっき登録した ia_test.csv を選択します。
Global Config で バッチサイズを36にします( ia_test.csv のデータ数が36個で、これより大きいとエラーになってしまうので)。
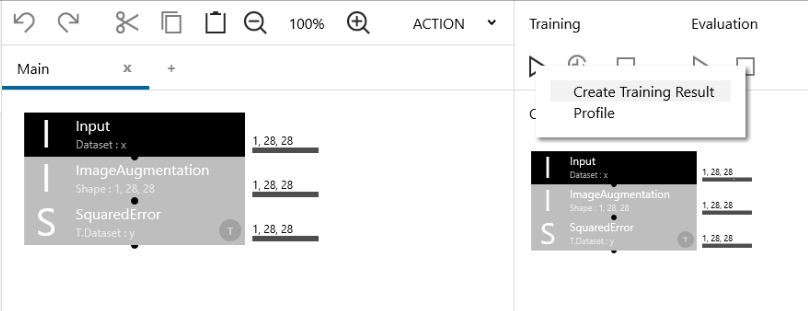
Training の「▷」ボタンの上で右クリックをして、ポップアップメニューから Create Training Result を選択します。そうすると全く学習せずに、学習完了となります。
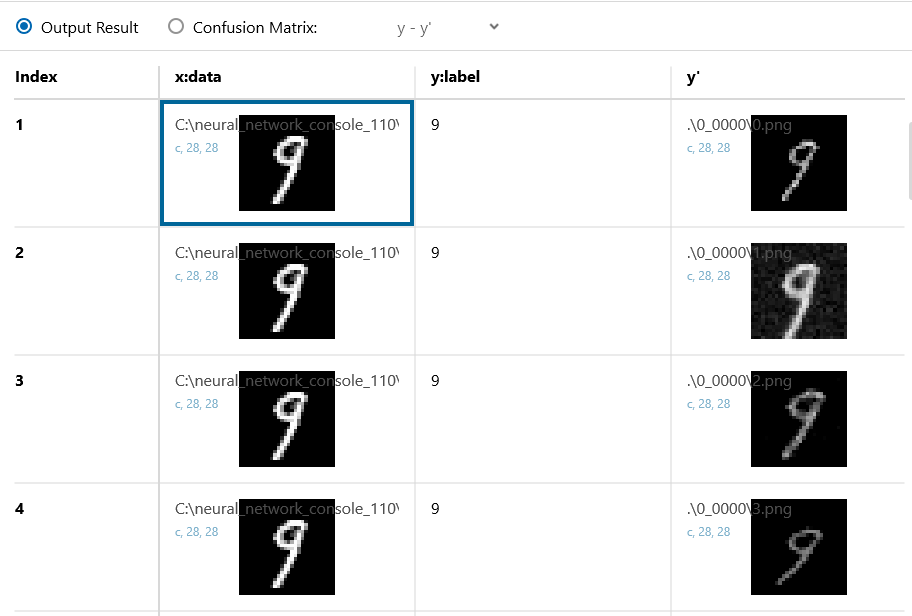
そして評価を実行すると、Output Result に画像を加工した結果が表示されます。画像は、プロジェクトのフォルダーにも出力されるので、そちらを見てみると、

1つの「9」画像に対して、設定した条件に従って、ランダムに画像に加工を加えている状況が分かると思います。この自動的にランダムに加工してくれるところが嬉しいところ。
実際の効果を確認してみる
こんな場面を想定してみます。
0~9の数字を識別をさせたいと考えているが、学習用データが100個(各数字10個づつ)しか用意できなかったします。この場合に、ImageAugmentation を使うことによって識別精度をどれだけ向上させることが出来るかを確認してみます。
検証に使うサンプルプロジェクトは、LeNet です。

LeNet は、通常60,000個のデータを使って学習し、識別精度は99%以上を誇るネットワークですが、もし100個のデータで学習するとどうなるでしょうか。
Neural Network Console には、mnist_training_100.csv という0~9の数字データが100個だけの学習ファイル(本来は半教師学習用です)が用意されています。今回は、これを使ってみます。
学習ファイルを mnist_taining.csv から mnist_training_100.csv に変更して学習をします。なお、評価ファイルは、mnist_test.csv のままです。
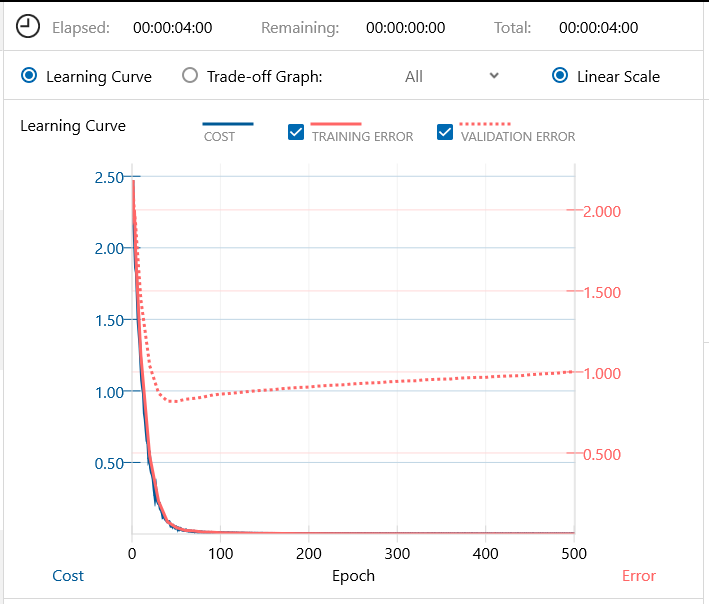
バッチ64、エポック500で、学習開始します。学習時間は4分。もうこれ以上やっても、改善は見られない感じです。

学習データが60,000個の時には99%以上の認識精度を誇った LeNet も、学習データが100個になってしまうと認識精度は75%にがた落ちです。
そこで、ImageAugmentation の登場です。

Input の次に、ImageAugmentation を入れるだけです。なんて簡単なんでしょう(ImageAugmentation の設定は、先程と同じです)。
但し、Runtime(推論)の時には、ImageAugmentation を入れない方が良い(推論をする時にわざわざ入力画像に加工して難しくすることはない)ので、ちょっと工夫をします。
通常は、Mainのネットワークだけ作成すれば、Neural Network Console が自動的に、Training、Validation、Runtime のネットワークを作ってくれますが、Rutime(推論) だけネットワークを変えたい時は、3つネットワークを自分で作成します。
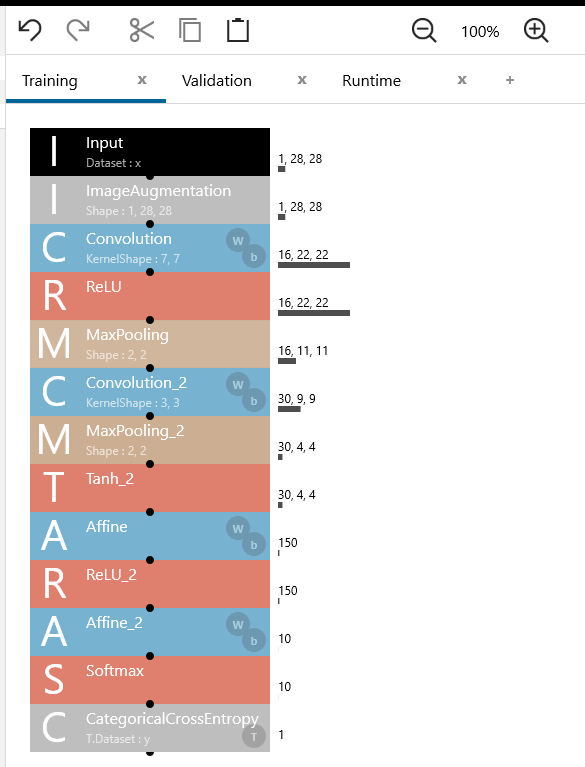
ネットワーク名をMainからTrainingに変更し、「+」ボタンを押して、ValidationとRuntimeを追加します。
Validation には、Training と同じネットワークをコピーすればOKです。

Runtime は、ImageAugmentation を外します。そして、CategoricalCrossEntropy を削除し、Softmax の Name を「y’」に変更します。
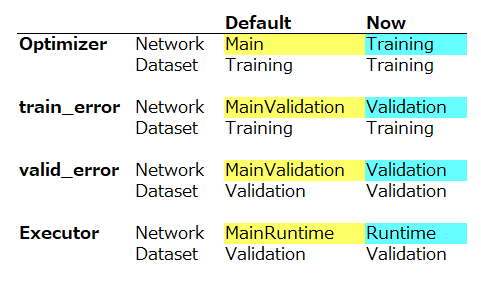
後、CONFIG画面で、Optimizer、train_error、valid_error、Executor の4つについて、Network とDatasetの設定をDefault からNowに変更します。
通常は Main だけ作成すると、Neural Network Console が、自動的に、MainValidation と MainRuntime を作っているわけです。
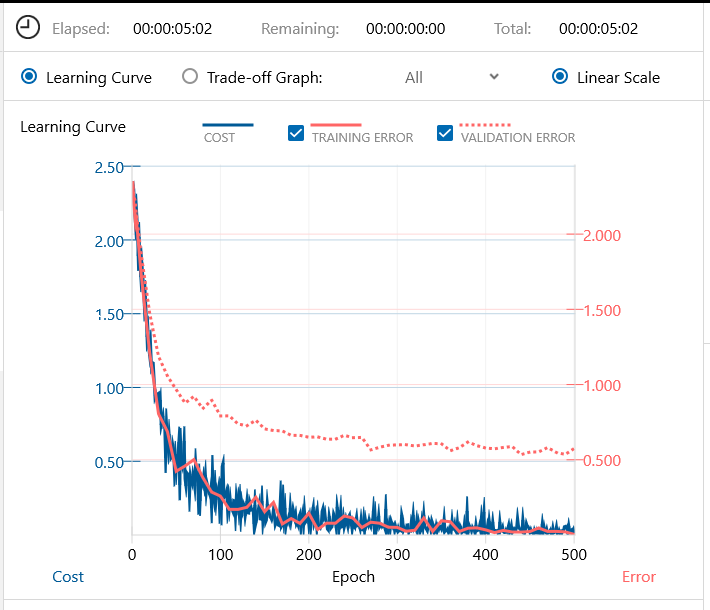
先程と同じく、バッチ64、エポック500で、学習を開始します。5分2秒で学習完了です。まだ、エポック数を増やせば、誤差が下がりそうな雰囲気です。
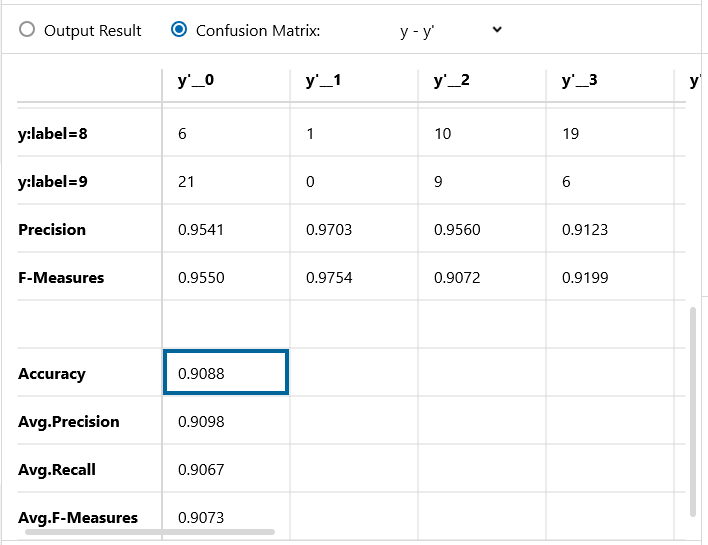
なんと認識精度は 90%。ImageAugmentation 無しの時と比べて、+15%も向上しました。効果絶大です!
もちろん、学習データを十分確保するのが一番良い訳ですが、様々な理由でそれが出来ないことは結構あると思います。
そんな時、ImageAugmentation は強力な武器になりそうです。
では、また。














コメントを残す