
今回は、Keras のサンプルプログラム MLPを改造してみることで、新たな定番パターンを勉強したいと思います。
こんにちは cedro です。
最近、Keras をよく触るようになりました。
なぜかというと、Keras は Web に様々な情報が溢れていて、欲しい情報が直ぐ手に入るからです。
例えば、サンプルプログラムは Keras_team の公式版の他にも、色々な方々が作ったものが沢山見つかりますし、個別の機能を紹介するブログにも事欠きません。
また、何かエラーが発生した場合でも、多くの場合その処方箋が簡単に Web で探すことができます。これはありがたいことです。
Keras に触り始めて約2ヶ月経ち、そろそろ色々な 定番の処理パターンを集中してチェックしてみようかなと思っているところです。
ということで、今回は、Keras のサンプルプログラム MLPを改造してみることで、新たな定番処理パターンを勉強したいと思います。
Keras MLPとは
今回、改造するサンプルプログラムは、mnist_mlp.py で、0〜9の数字のデータセット MNIST をMLP(多層パーセプトロン)で分類する基礎的なものです。

MacbookAir でサンプルプログラムをそのまま動かすと、ターミナルに Epoch毎のデータが次々と軽快に表示され、3分かからずに終了します。
しかし出て来る結論は 、Test_loss : 0.1285 (評価ロスは1.285%) , Test_accuracy : 0.9814 (分類精度は98.14%)のたった2行だけ。
えっ!?これだけなの?という感じですよね。
特に、データセット(MNIST)は何処か知らないところから自動でダウンロードされて来るので、益々「これだけ?」感が増します。
ということで、これからこのプログラムを改造して行きます。
新たなデータセットを準備します
今回使うデータセットは、NDL Lab の文字画像データセット(平仮名73文字版)で、グレースケール48×48の平仮名画像がPNG形式で計 80,000枚あるものです。この中から、「あ、い、う、え、お、か、き、く、け、こ」の10種類だけ抜き出します。
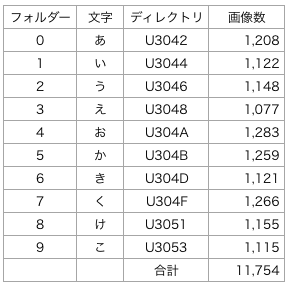
各文字の画像数は1,200枚前後で、合計約12,000枚です。MNISTのデータ数は70,000枚なので、その1/6くらいと少ないですが、なんとかなるでしょう。
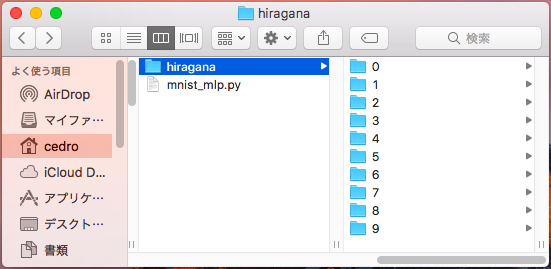
プログラムと同じところに、hiragana フォルダーを作成し、その下に0〜9のフォルダーを作成し、「あ」〜「こ」の文字をそのまま格納します(前処理は一切不要です)。
データセットを入れ替えて動かします
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop from sklearn.model_selection import train_test_split ### 追加 from PIL import Image ### 追加 import numpy as np ### 追加 import glob ### 追加 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# the data, split between train and test sets #(x_train, y_train), (x_test, y_test) = mnist.load_data() folder = ["0","1","2","3","4","5","6","7","8","9"] image_size =28 x = [] y = [] for index, name in enumerate(folder): dir = "./hiragana/" + name files = glob.glob(dir + "/*.png") for i, file in enumerate(files): image = Image.open(file) image = image.convert("L") image = image.resize((image_size,image_size)) data = np.asarray(image) x.append(data) y.append(index) x = np.array(x) y = np.array(y) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) x_train = x_train.reshape(x_train.shape[0], 784) ### 28×28×1=784 x_test = x_test.reshape(x_test.shape[0], 784) ### 28×28×1=784 |
このブログでは何度も登場しているデータセット読み込みの定番部分です。ラベル数が多いデータセットの読み込みは、この方法が便利ですねー。
なお、ネットワークの入力が全結合のため、x_train の shape を [ 学習データ数, 28, 28, 1 ] から [ 学習データ数, 784 ] にリシェイプしています。x_test も同様です。

さて、動かしてみると、データ数が少ない(MNISTの1/6)ので、処理が早いです。約20秒で処理が完了です。
さすがに、自分が準備したデータセットを使ったので、Test_accuracy : 0.9910 (識別精度99.10%)を見ると、「データが少ない割には結構良い精度じゃん」、と実感がわいて来ます(笑)。
ロス、精度の時系列グラフが欲しい
ロス、精度については、リアルタイムにターミナルに数字は表示されますが、それをを見るだけではピンと来ません。やはり、時系列推移はグラフで見たいところ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
### Plot accuracy & loss import matplotlib.pyplot as plt acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(acc) + 1) #plot accuracy plt.plot(epochs, acc, "bo", label = "Training acc" ) plt.plot(epochs, val_acc, "b", label = "Validation acc") plt.title("Training and Validation accuracy") plt.legend() plt.savefig("acc.png") plt.close() #plot loss plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.plot(epochs, val_loss, "b", label = "Validation loss") plt.title("Training and Validation loss") plt.legend() plt.savefig("loss.png") plt.close() |
プログラムの最後に、これを追加します。
Keras は、学習時の様々なデータを history ディレクトリに保存し、そこから必要なデータを読み出すことができる機能を標準で持っていますので、これを活用します。但し、学習部分に、history = model.fit ( x_train, y_train,・・・という様に、history が記述されている必要があります。
インポートしているのは、グラフを表示させるためのライブラリ Matplotlib です。さて、これでプログラムを動かすと、
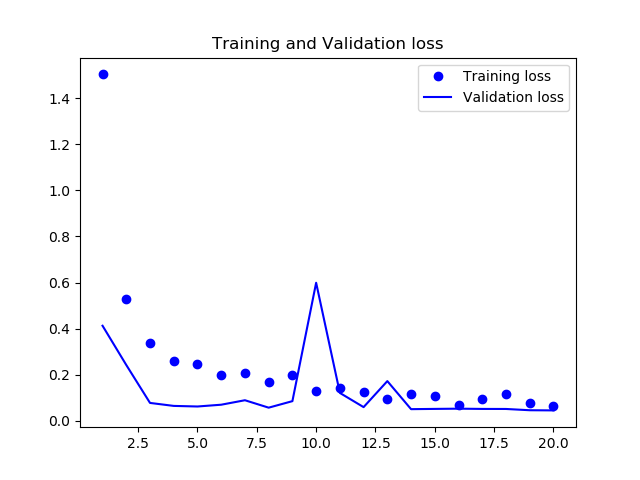
ロスの推移グラフです。
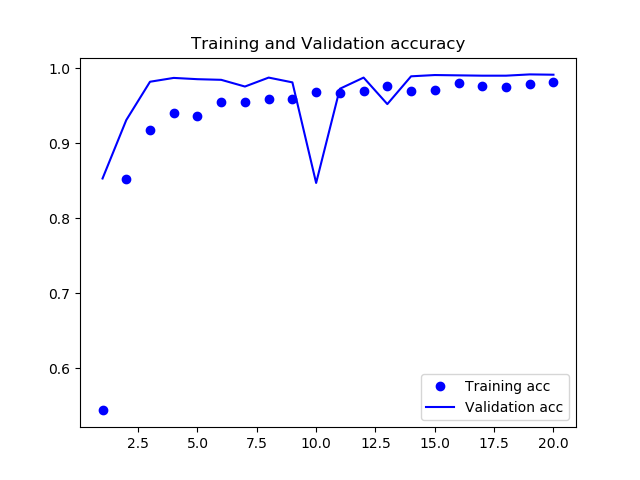
精度の推移グラフです。
Confusion Matrix が欲しい
私がディープラーニングを始めたきっかけになった SONY Neural Network Console には、データセットの識別をする場合、どのデータと間違えたかが一目で分かる Confusion Matrix 機能がありました。Keras にも、これが欲しいということで、追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
### plot Confusion Matrix import pandas as pd import seaborn as sn from sklearn.metrics import confusion_matrix def print_cmx(y_true, y_pred): labels = sorted(list(set(y_true))) cmx_data = confusion_matrix(y_true, y_pred, labels=labels) df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels) plt.figure(figsize = (10,7)) sn.heatmap(df_cmx, annot=True, fmt="d") ### ヒートマップの表示仕様 plt.title("Confusion Matrix") plt.xlabel("predict_classes") plt.ylabel("true_classes") plt.savefig("c_matrix.png") plt.close() predict_classes = model.predict_classes(x_test[1:10000,], batch_size=32) ### 予測したラベルを取得 true_classes = np.argmax(y_test[1:10000],1) ### 実際のラベルを取得 print(confusion_matrix(true_classes, predict_classes)) print_cmx(true_classes, predict_classes) |
プログラムの最後に、さらにこれを追加します(「静かなる名辞」さんのブログを参考にさせて頂きました。感謝です。)
まず、confusion_matrix というズバリのライブラリーをインポートします。しかし、これだけでは行列の形で数字を返してくれるだけなので、見栄えが悪いです。
そこで、pandas と seaborn のライブラリーをインポートし、直感的に分かり易いヒートマップ形式の画像で保存します。
ヒートマップの仕様は、sn.heatmap(df_cmx, annot=True, fmt=””)の各引数によって、指定しています。df_cmx は表示するデータ、annnot=True はセルに値を表示、fmt=”d” は整数で表示。
予測したラベルの取得には、model.predict_classes メソッドを使っています。さて、これでプログラムを動かすと、
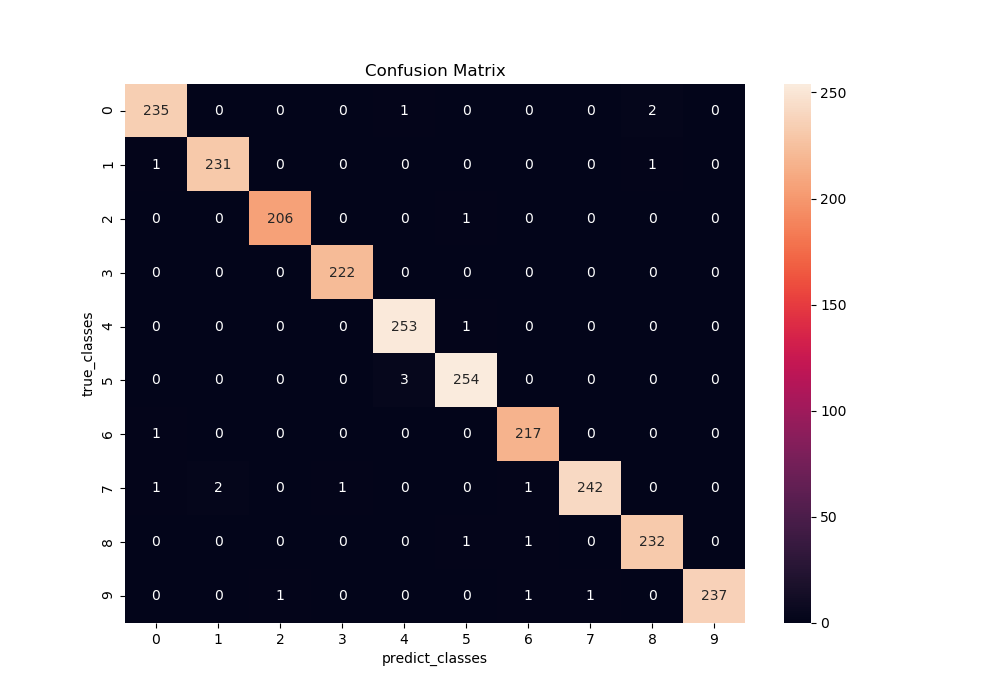
Confusion Matrix です。X軸が予測したラベル、Y軸が実際のラベルです。マスの中の数字は、そこに該当したデータ数を表しています。
例えば、実際の0をどう予測したかを見てみると、正解の0と予測したのが235個、4と間違えたのが1個、8と間違えたのが2個あったことになります。
つまり、左上角から右下角への斜めのマスの数字以外は、全てゼロになるのが理想の状態です。今回の結果は、ほぼ理想に近い状態ではないでしょうか。
ネットワークモデルを可視化したい
|
1 2 3 4 5 |
### Plot model from keras.utils import plot_model plot_model(model, to_file = "mnist_mlp.png", show_shapes = True) ### " " 内のファイル名でモデル画像を保存する |
Keras にはネットワークモデルを可視化するための plot_model という ライブラリーがあって、これをインポートしておけば、わずか1行でネットワークモデルを画像ファイルで出力できます。便利ですねー。
但し、あらかじめ pydot と graphviz をインストールしておく必要があります。さて、これでプログラムを動かすと、
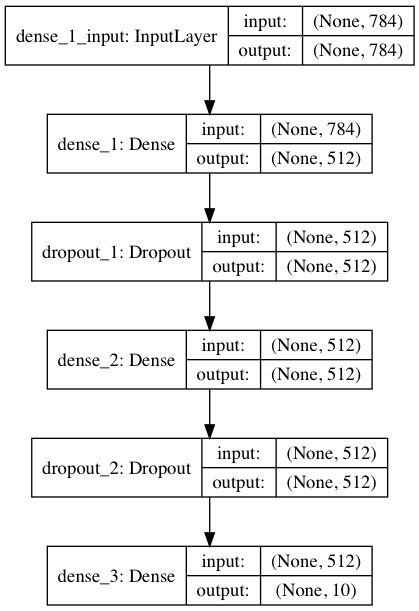
モデルを可視化した結果です。こういう形にすると、モデルが分かりやすいですね。
では、また。














コメントを残す